Modeling Deception in Multi-Robot Target-Attacker-Defender Game via Deep Reinforcement Learning
Abstract
Deception is a crucial strategy in adversarial scenarios, yet its application in multi-agent confrontations remains understudied. This paper investigates deception in a multi-robot Target-Attacker-Defender (MR-TAD) game, where Attackers aim to capture Targets while evading Defenders. To model deception effectively, we propose a hierarchical decision-making framework that integrates multi-agent reinforcement learning (MARL) for high-level deceptive strategies and optimal control for low-level motion control. Furthermore, we introduce a novel composite deception-oriented reward function, which combines hitting rewards, belief switch rewards, and position advantage rewards to facilitate the training of deceptive behaviors. Simulation results across varying numbers of robots demonstrate that incorporating deception significantly increases the success rate of Attackers, with an average improvement of over 70% compared to non-deceptive strategies. Additionally, real-world experiments with omnidirectional mobile robots further confirm the effectiveness of the proposed method. This study establishes a generalizable framework for modeling deception in multiagent systems, with potential applications in various multi-agent scenarios.
Contributions
- We formulated a problem of MR-TAD games where agents can switch their goals, and a novel hierarchical decision-making scheme is proposed to model deception in MR-TAD games.
- A composite deception-oriented reward design method is presented to facilitate the training of deceptive behaviors, greatly improving training efficiency and convergence.
- Simulations of varying numbers of robots are carried out to demonstrate the scalability and robustness of our method. Besides, we conducted real-world experiments based on omnidirectional vehicles.
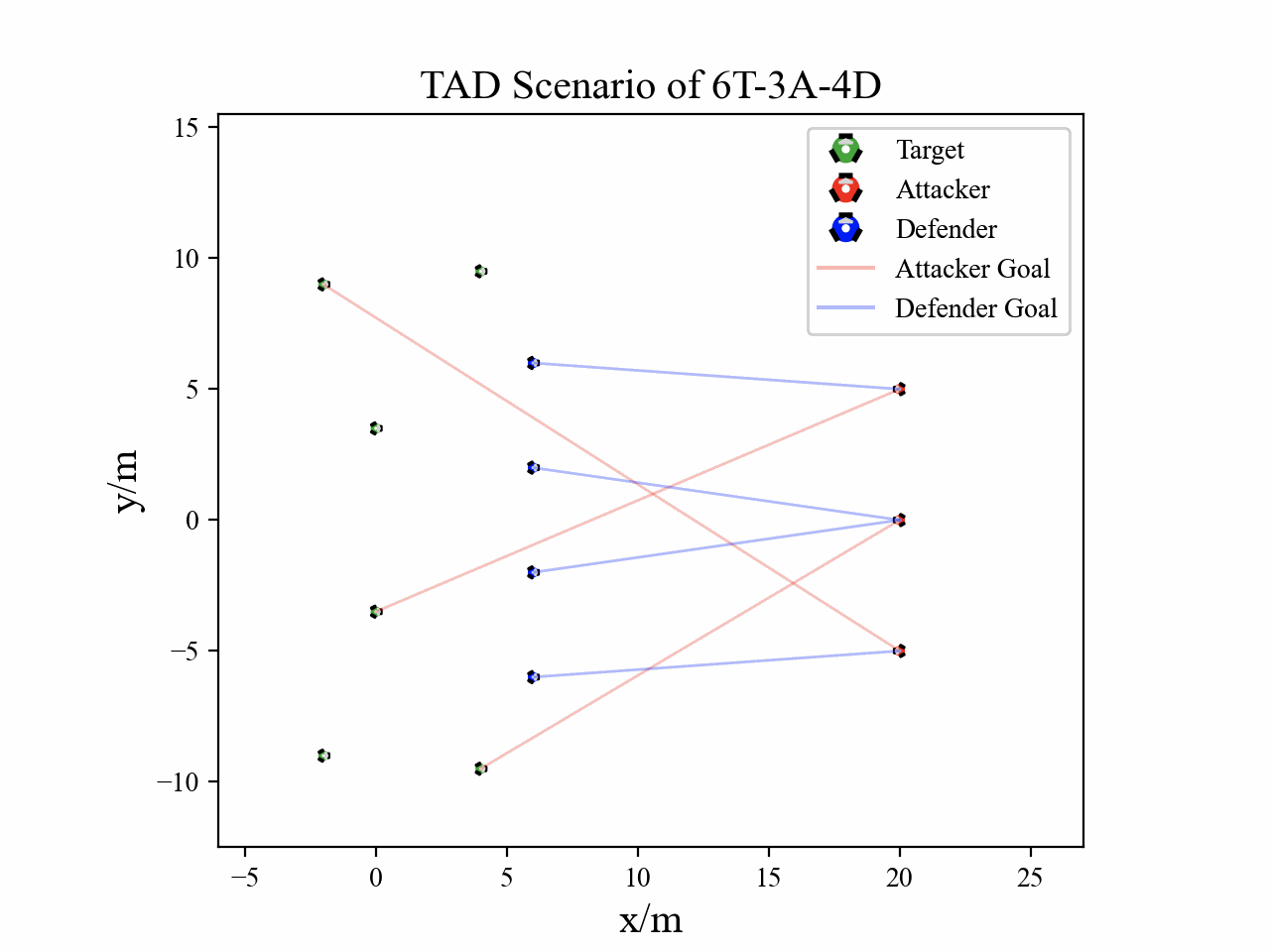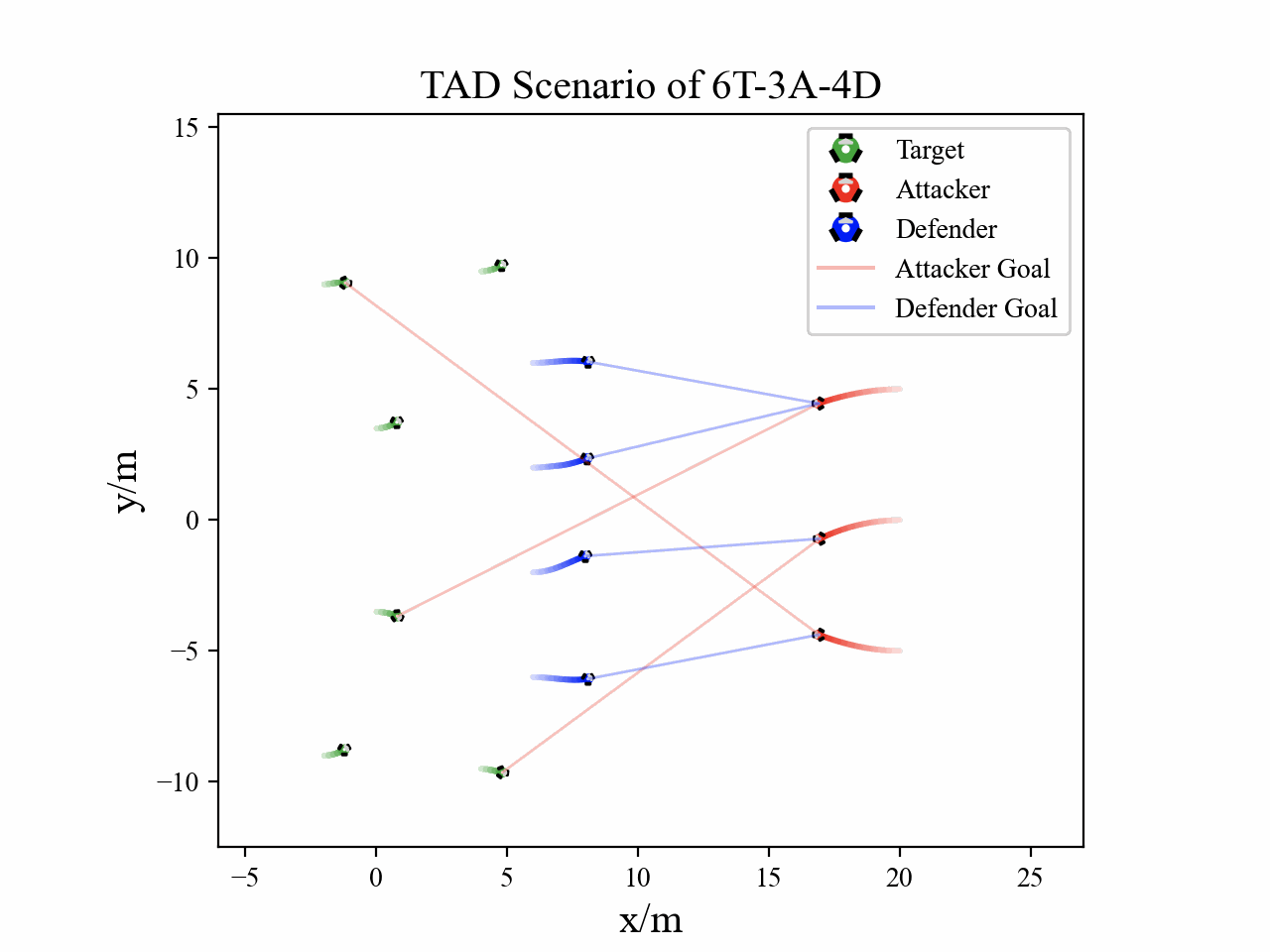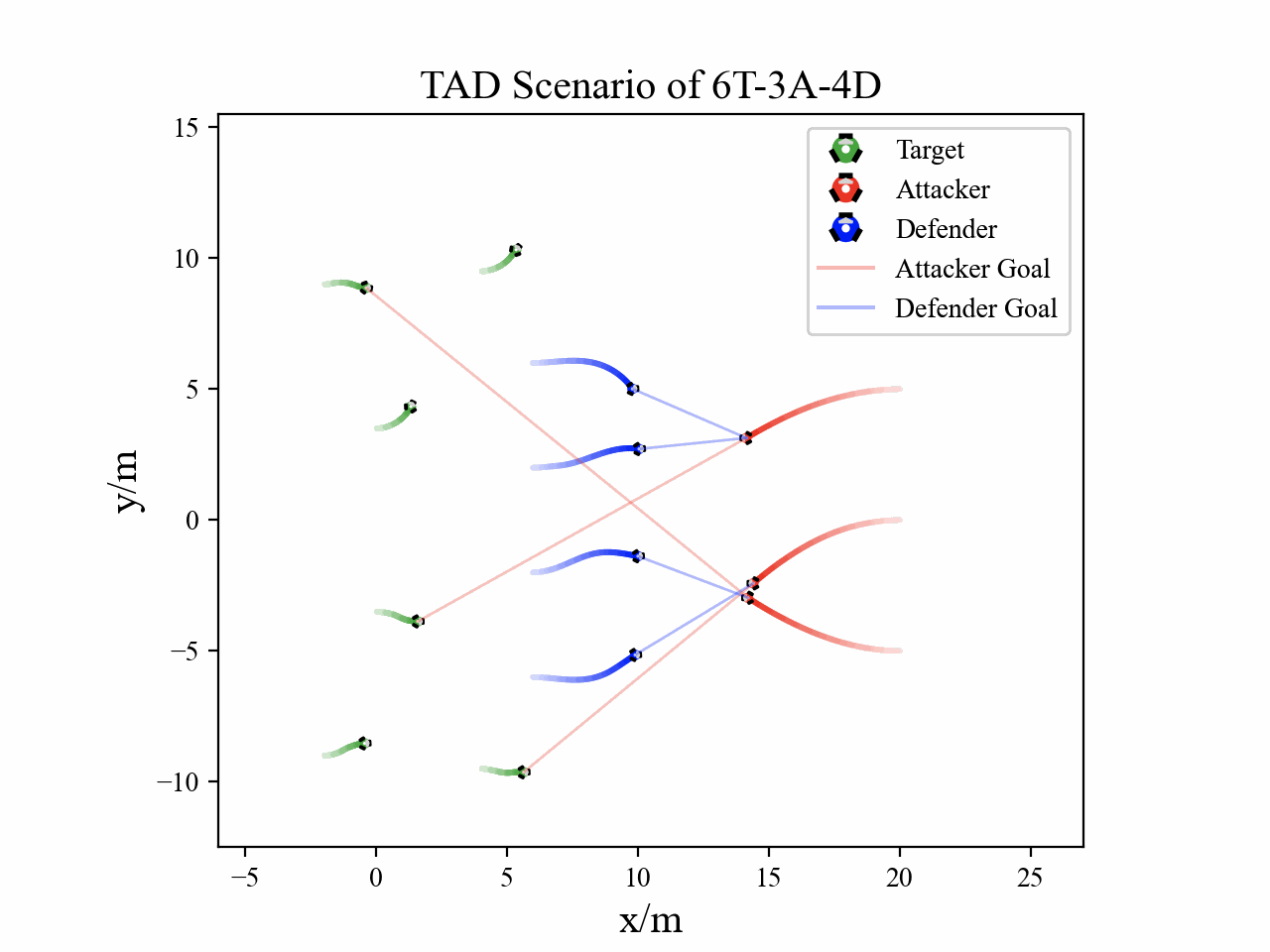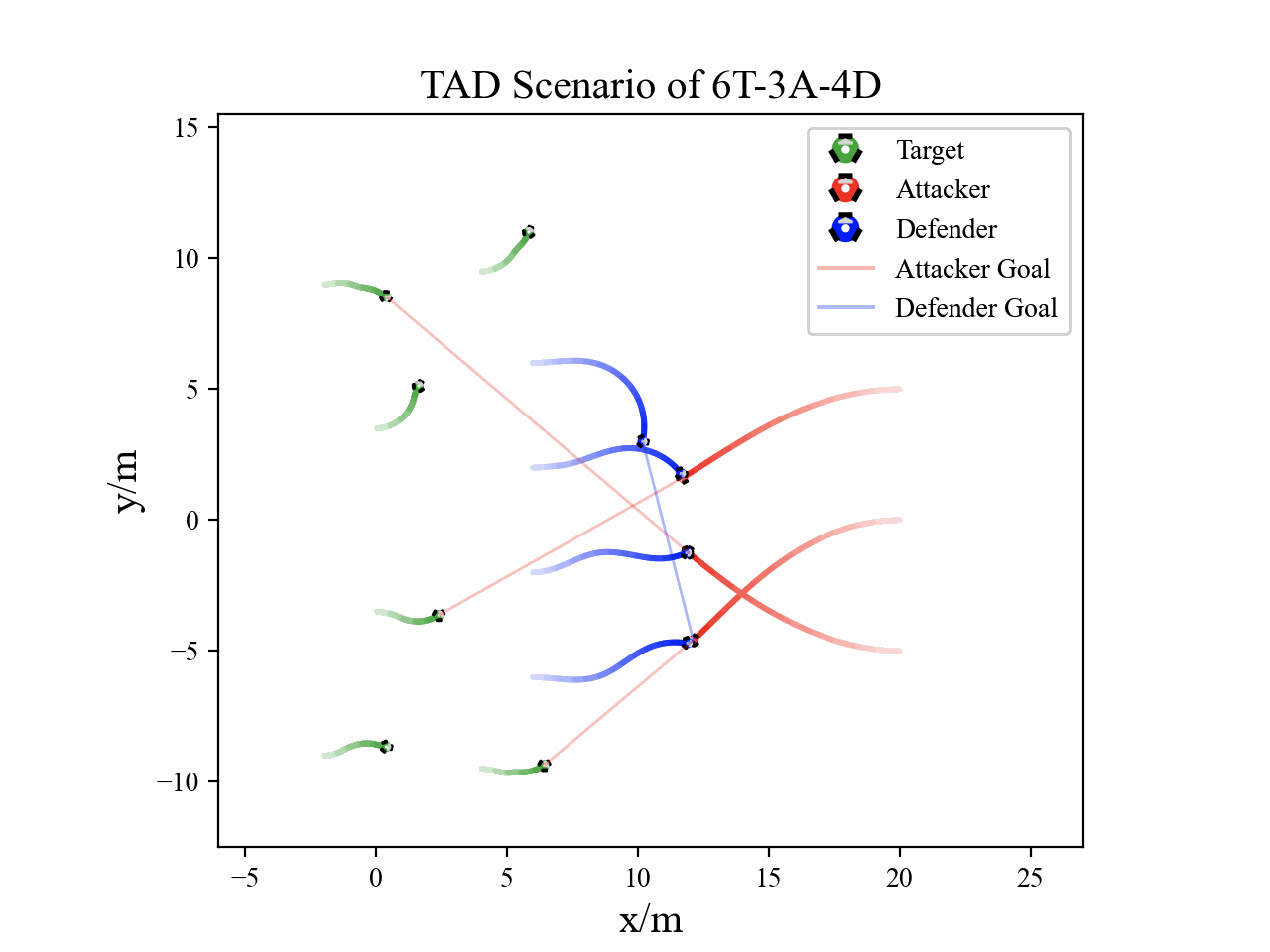
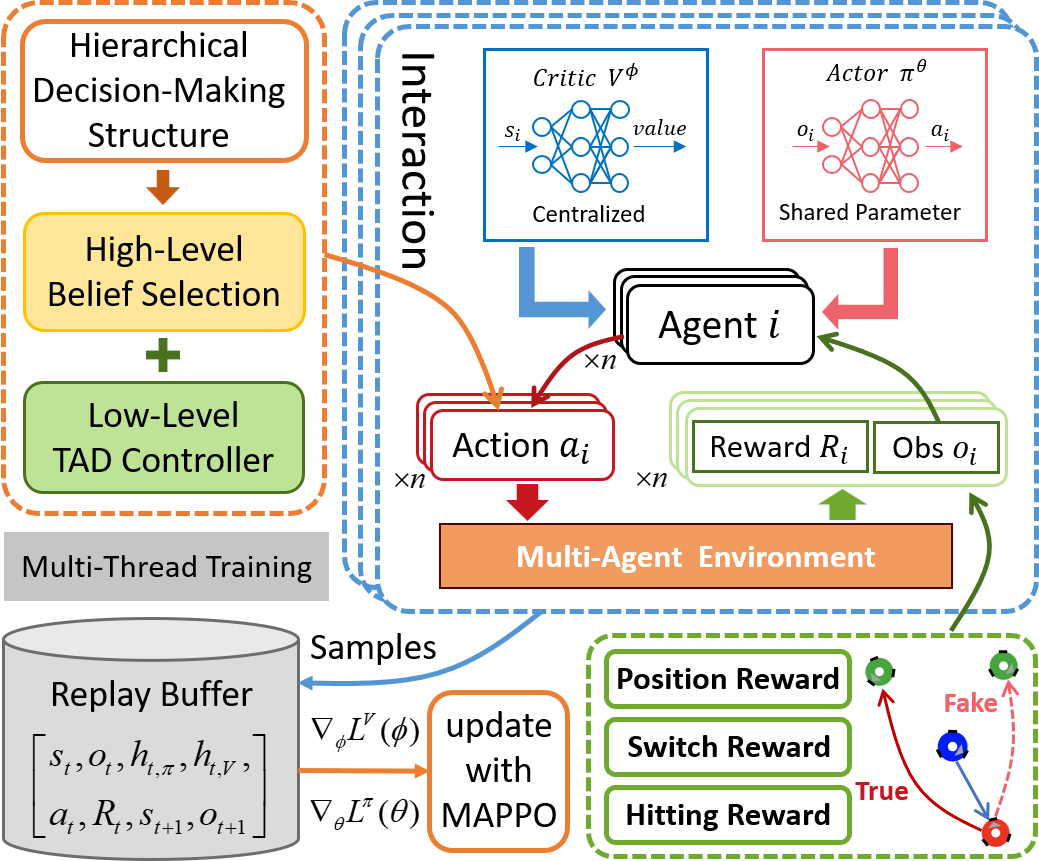
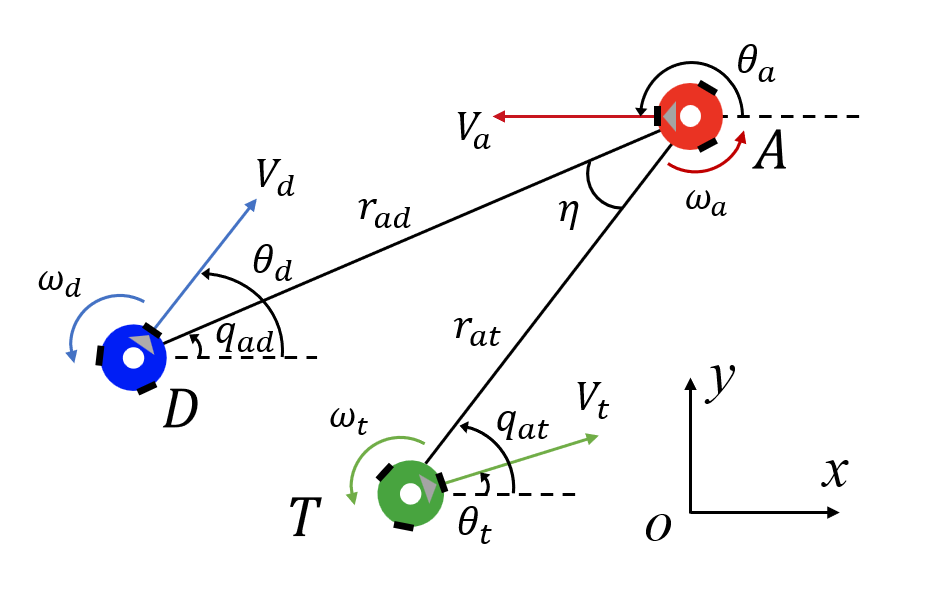
Visualization
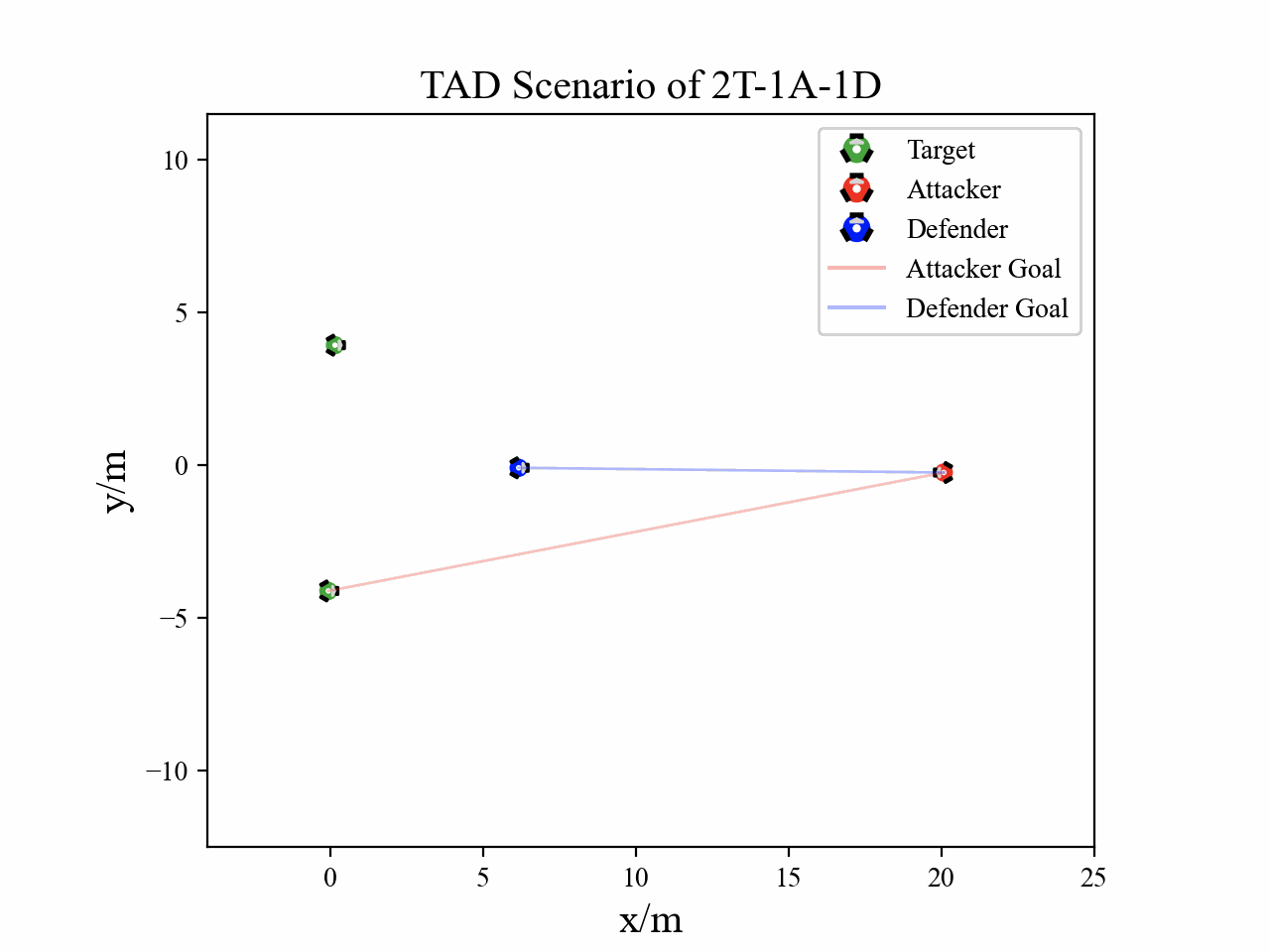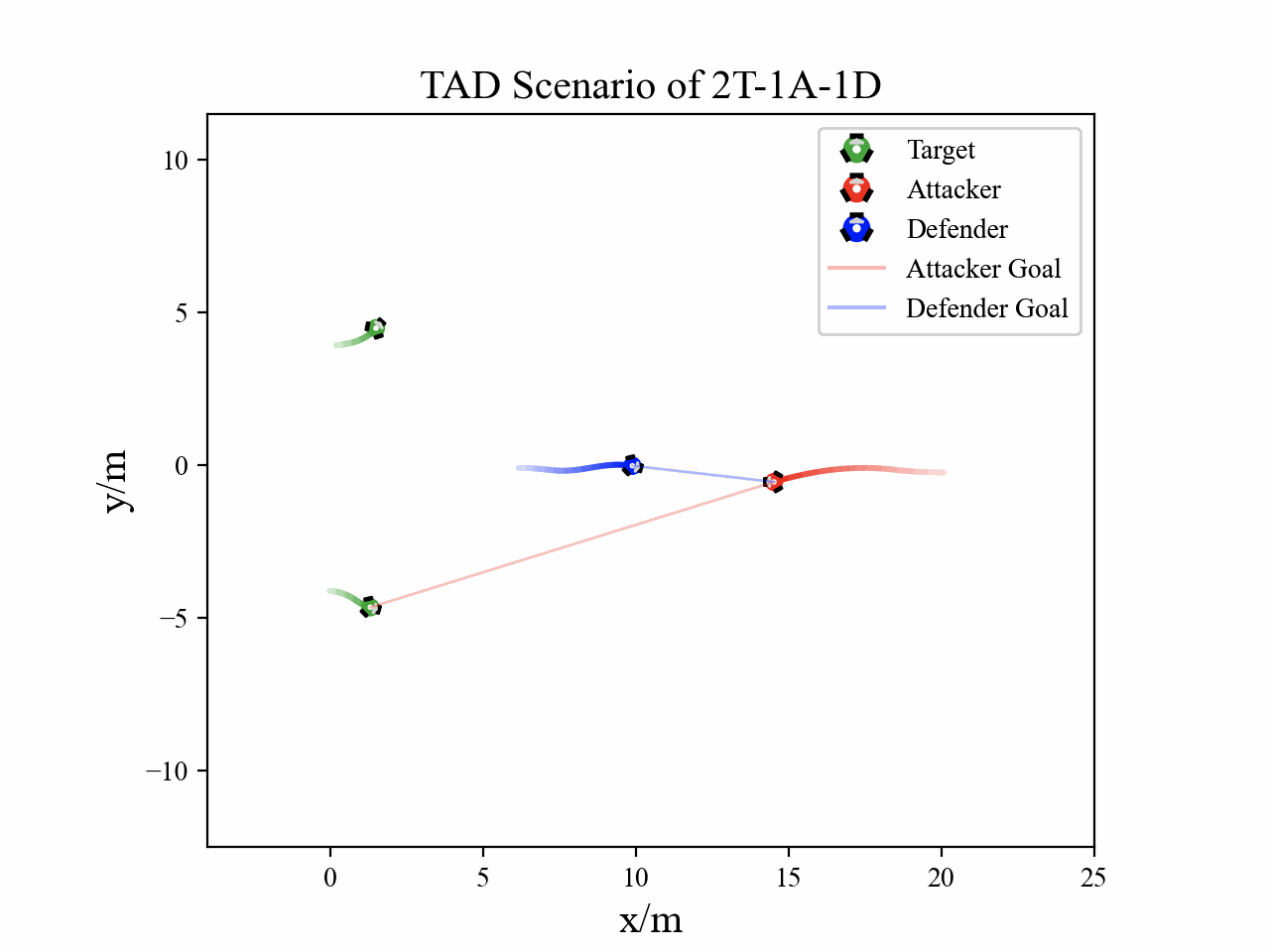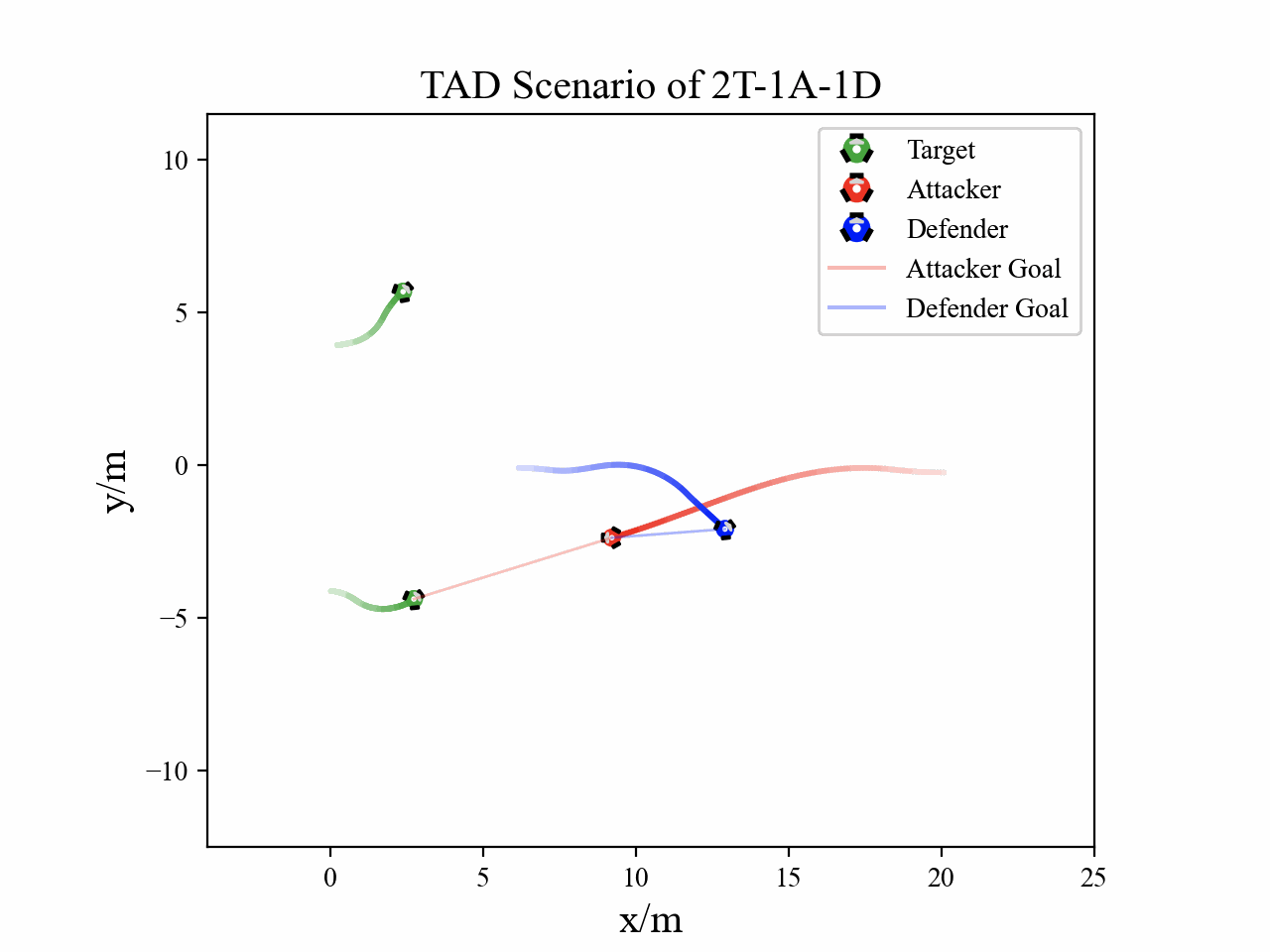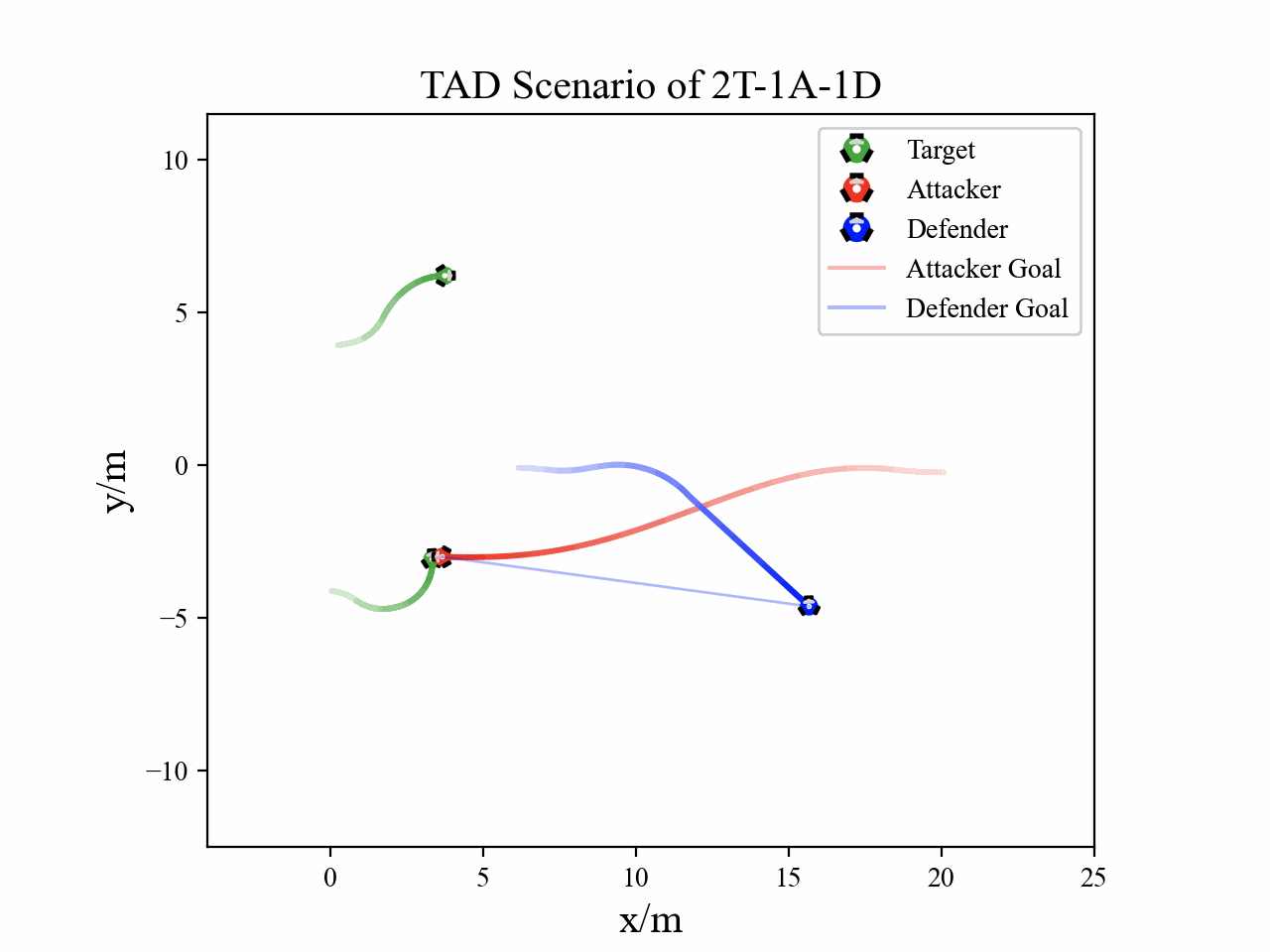
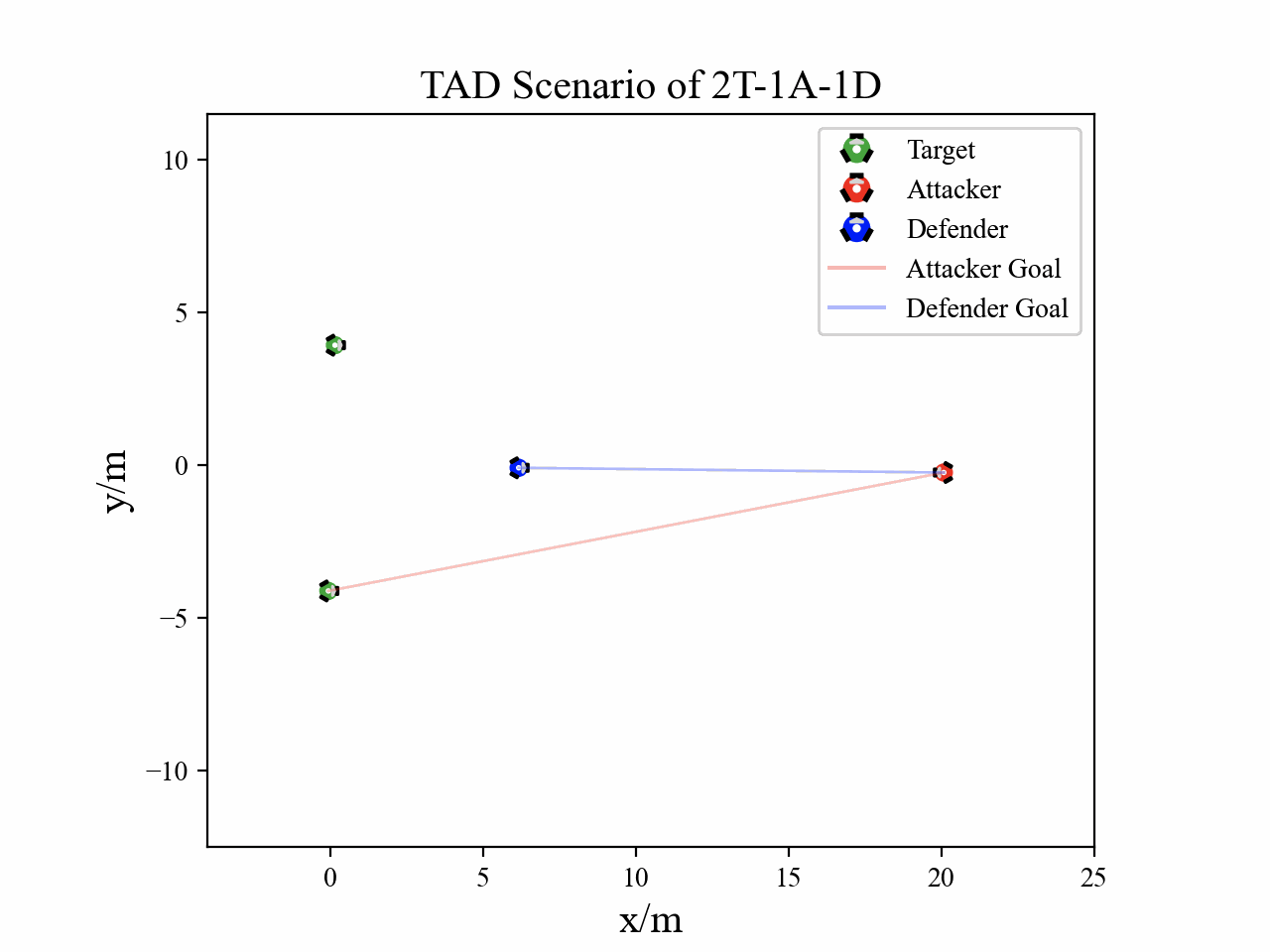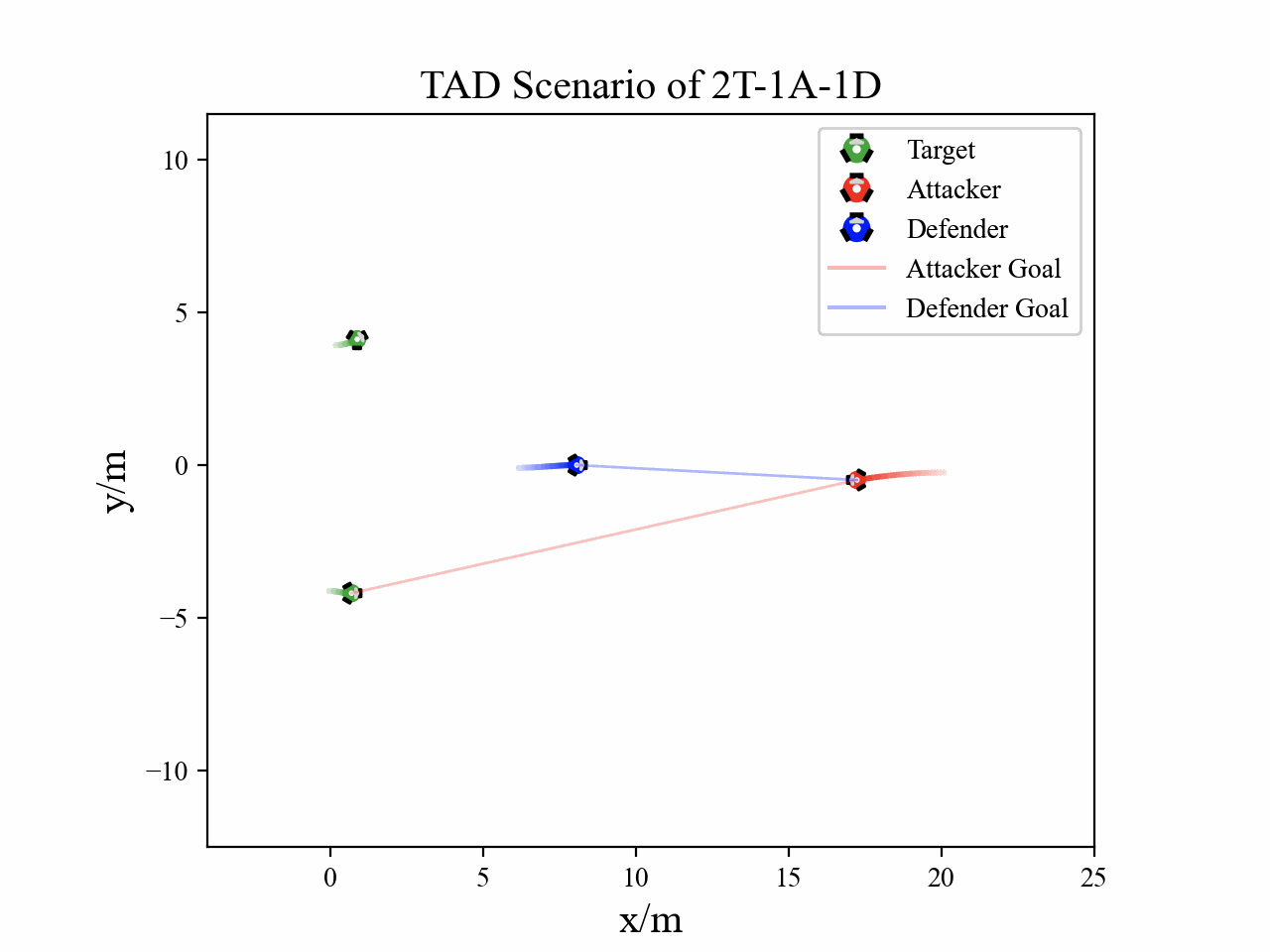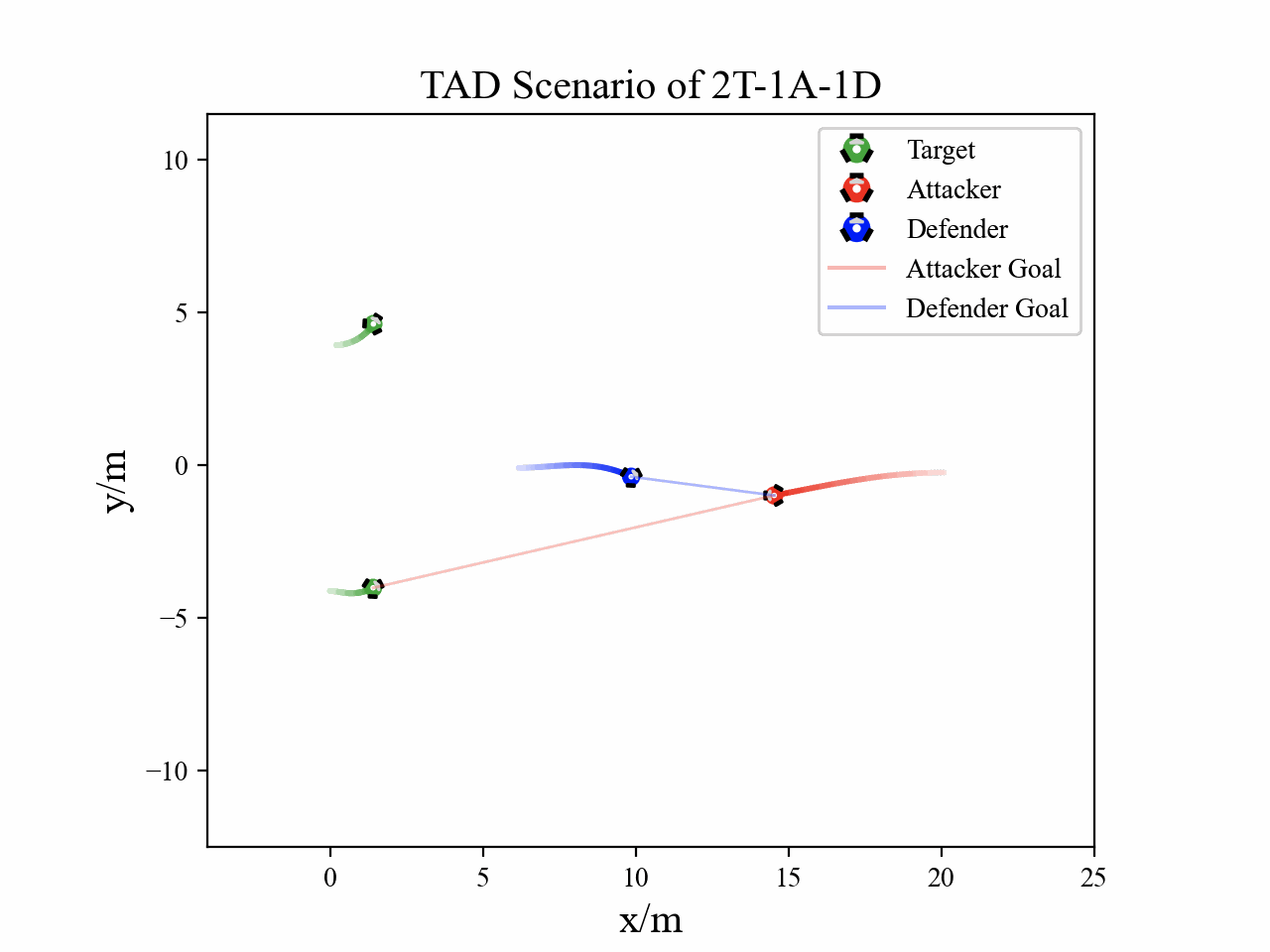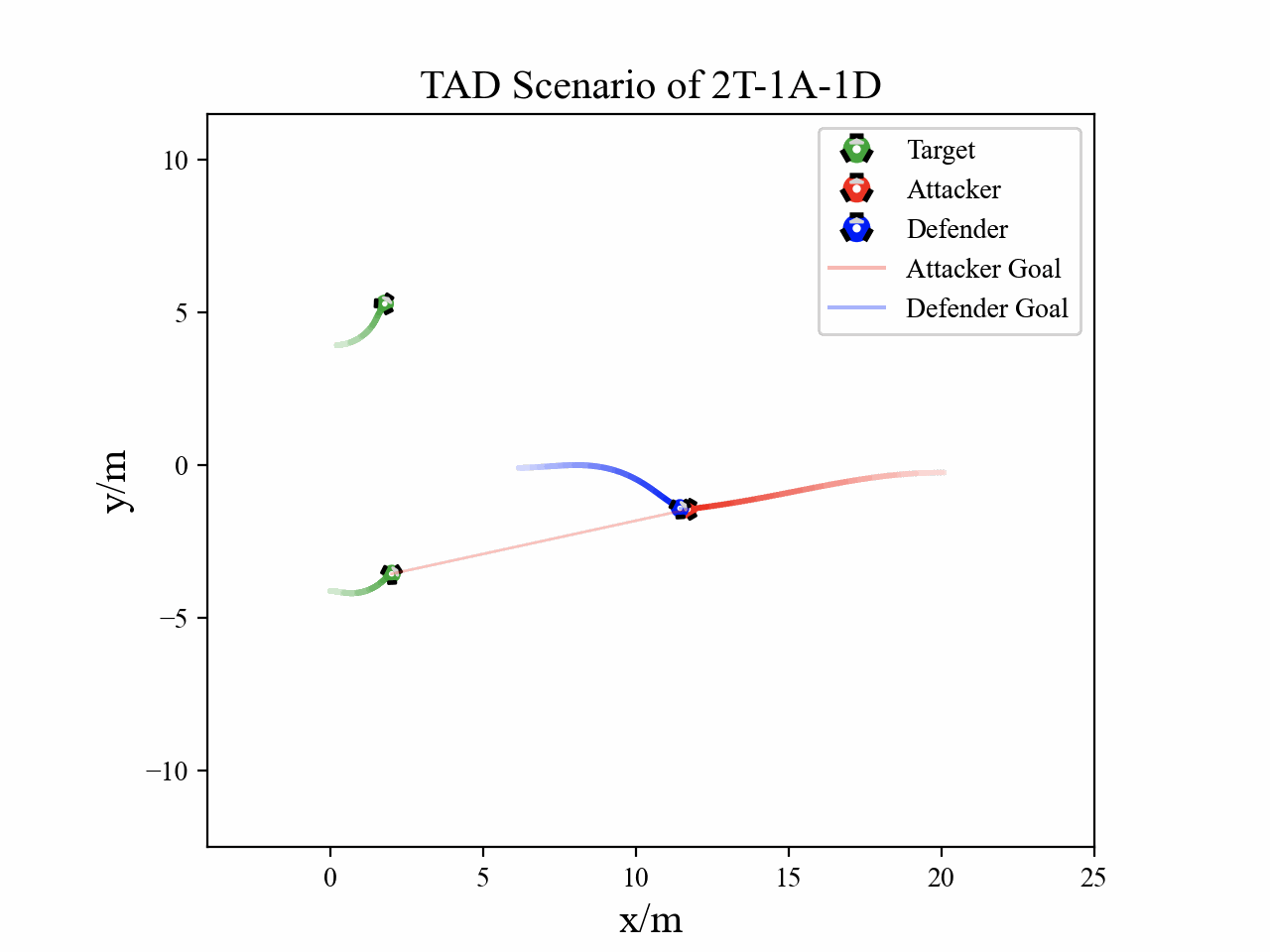
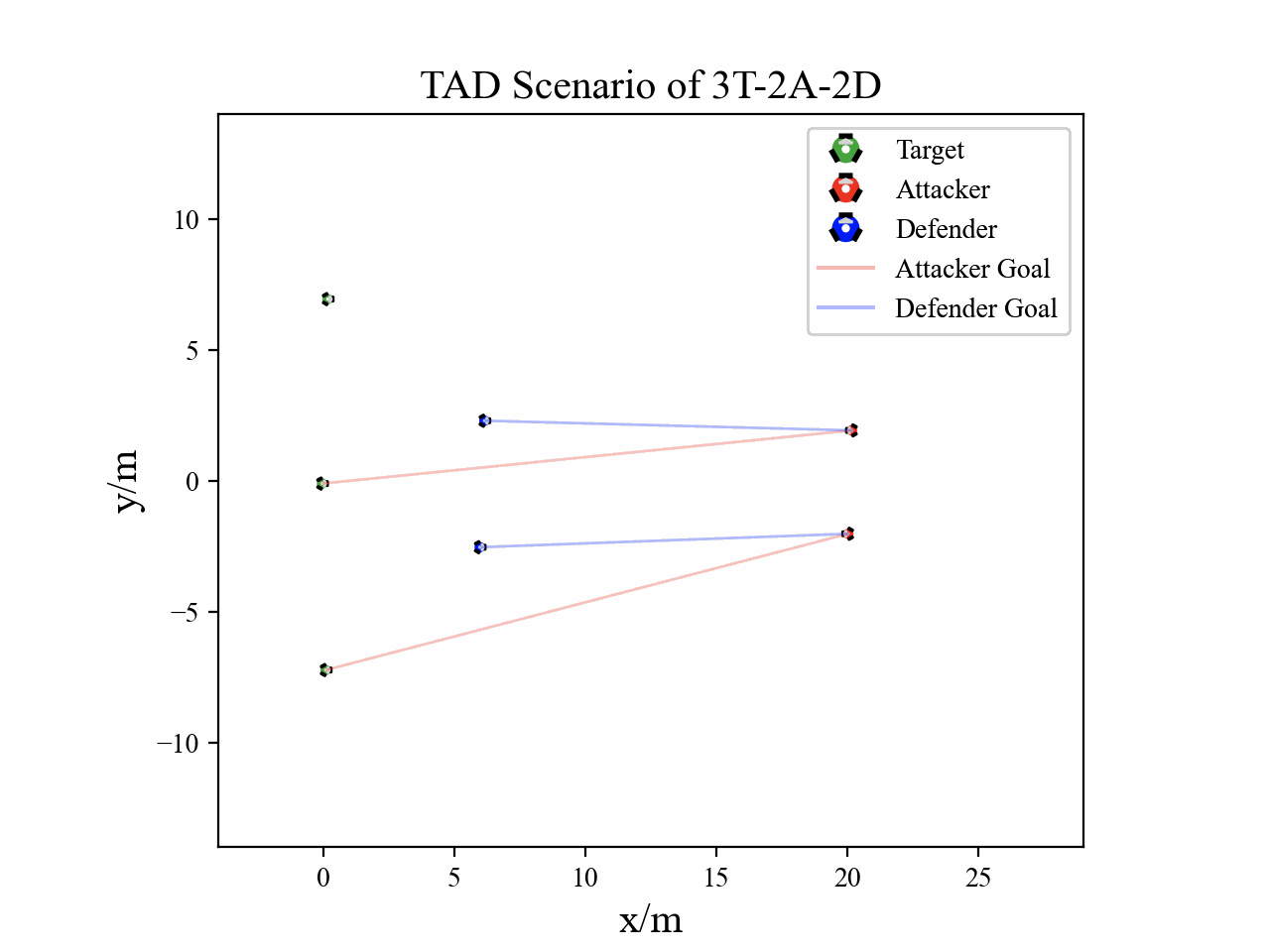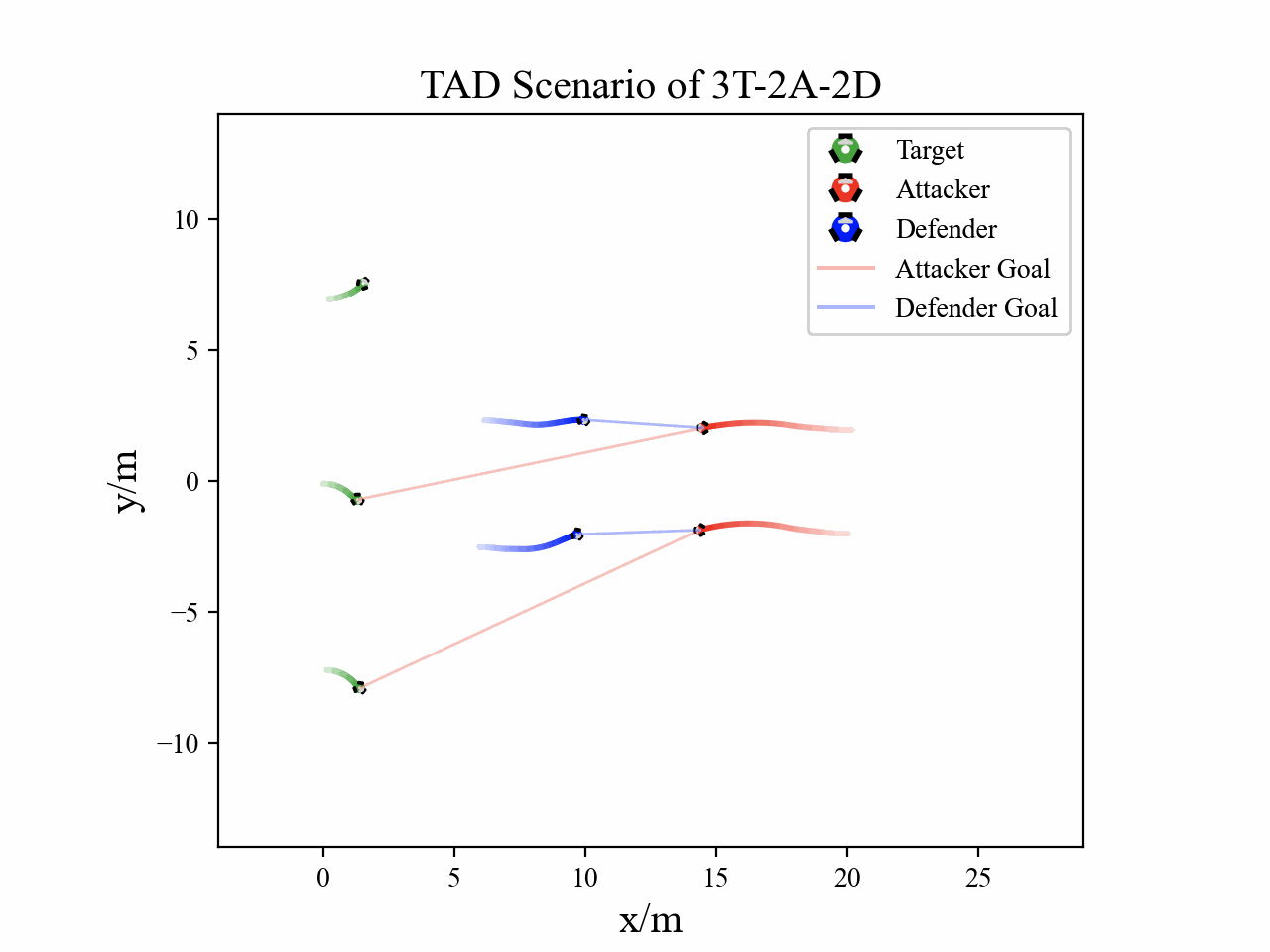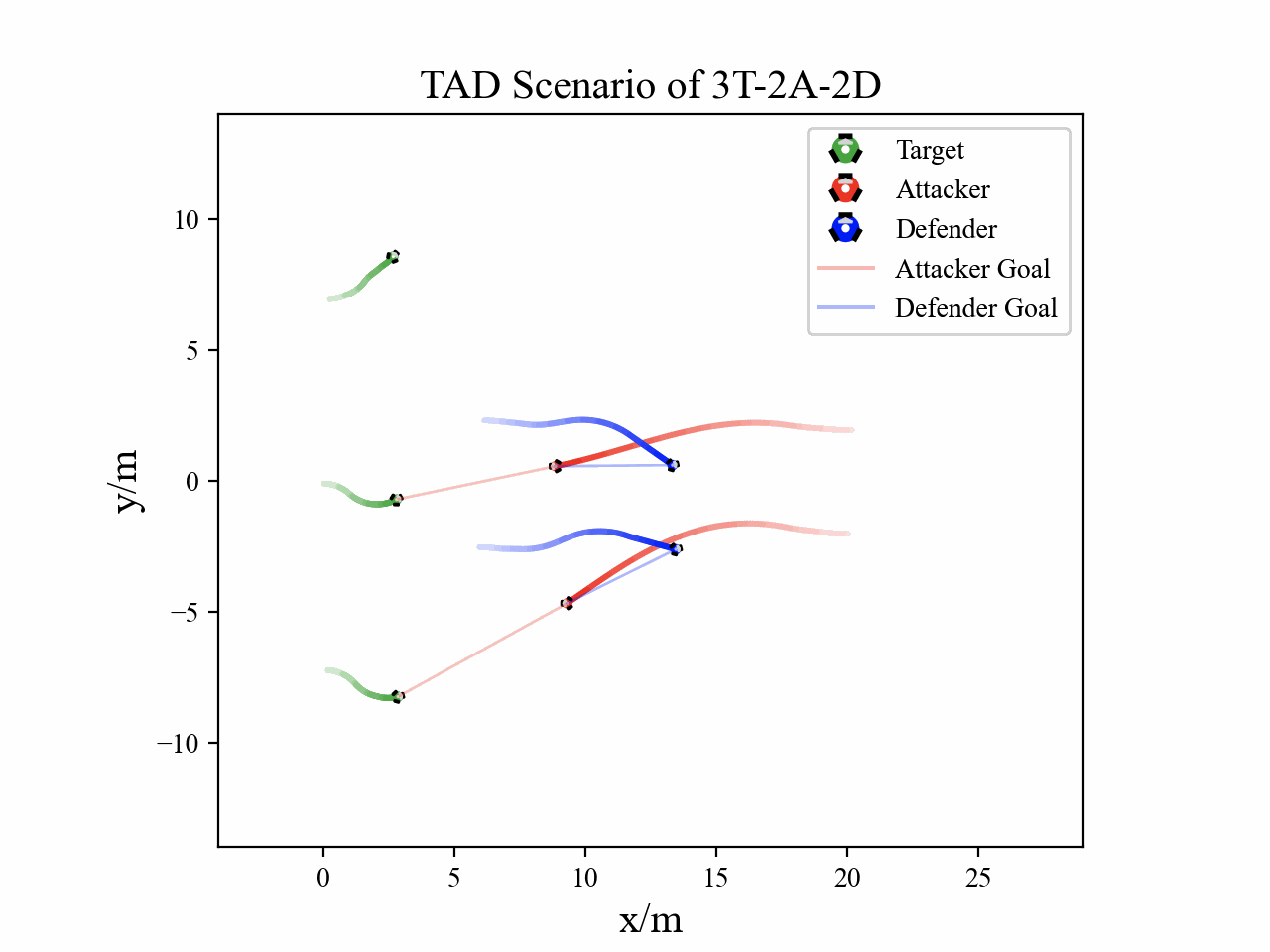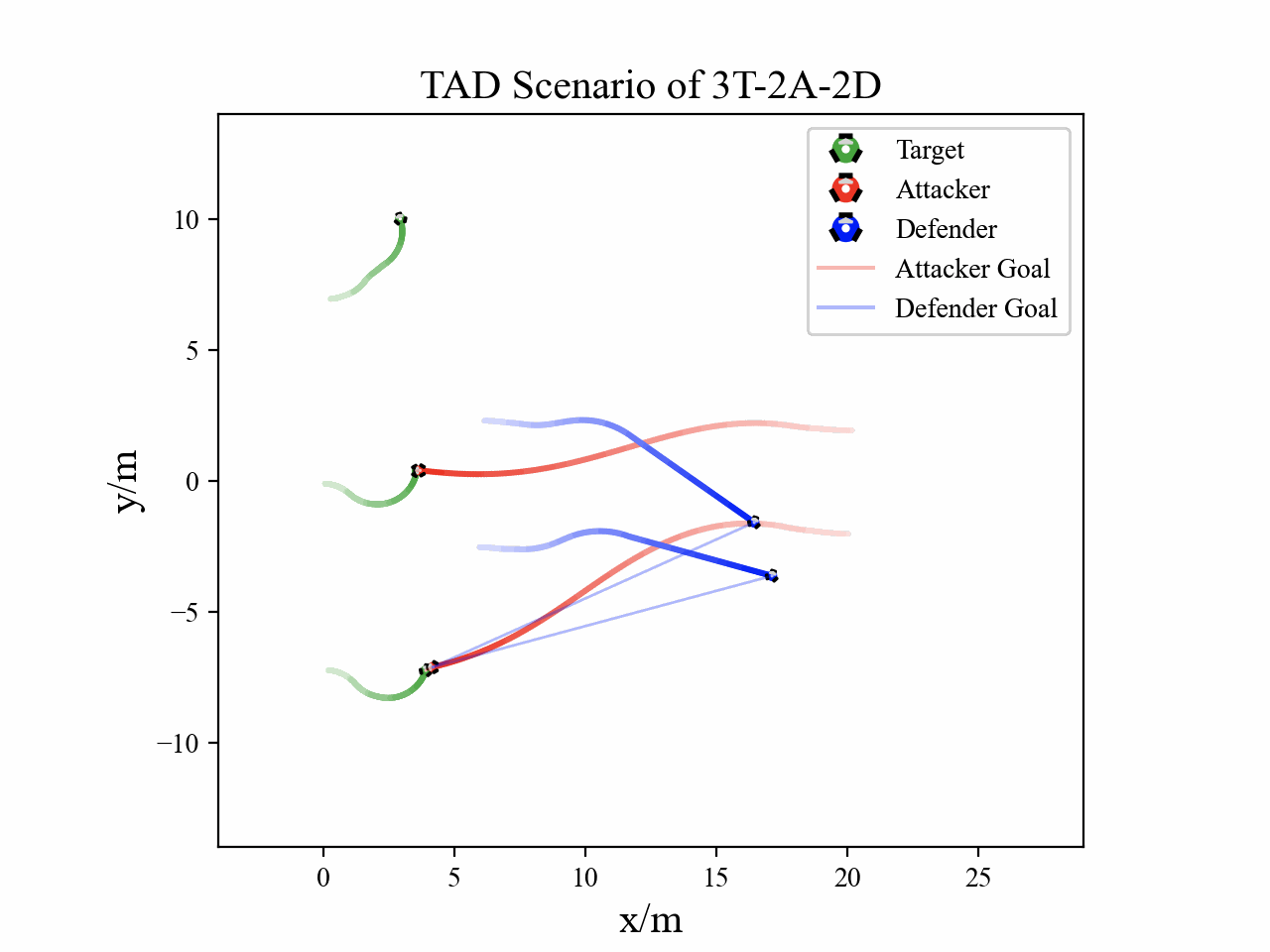
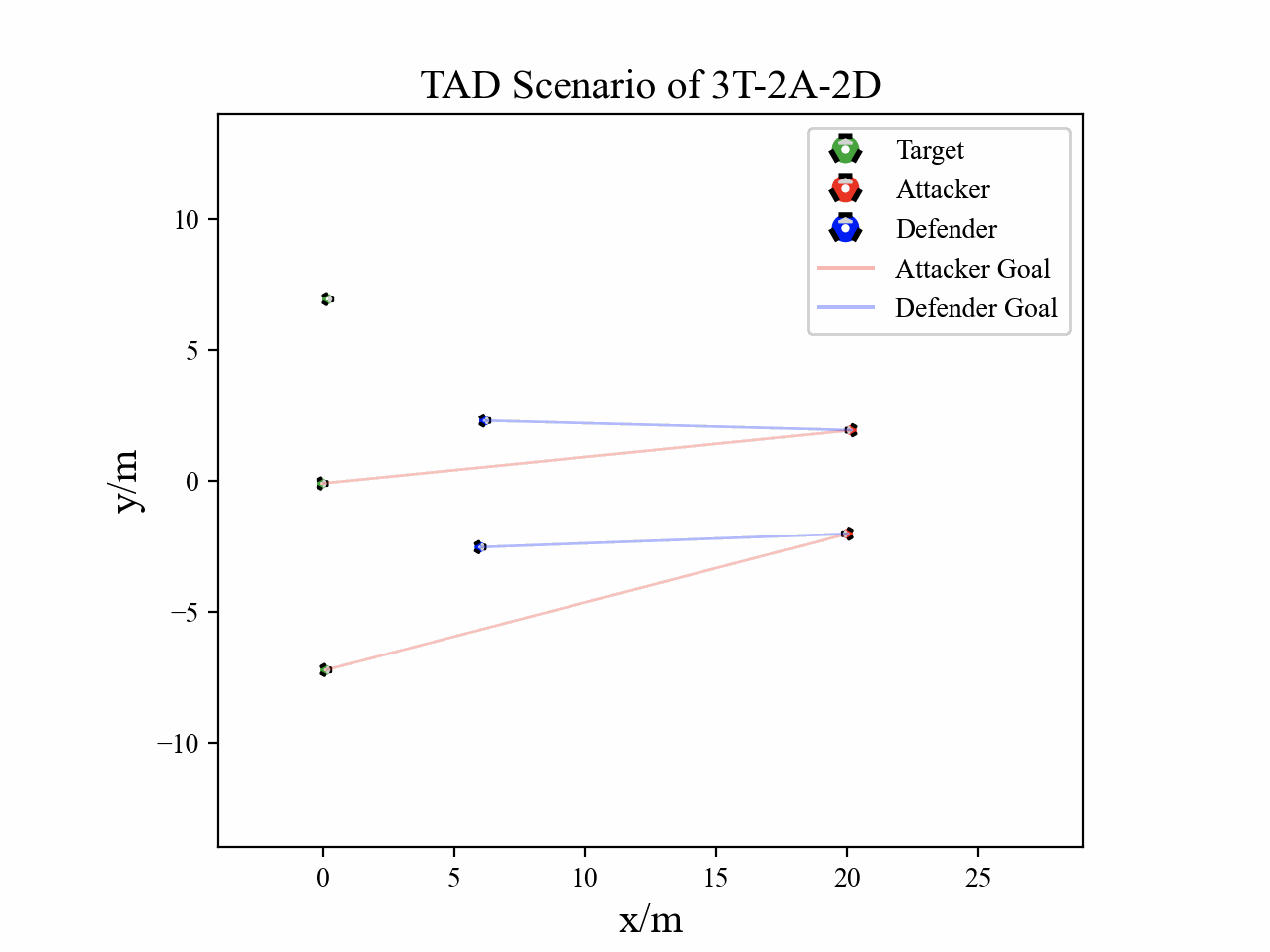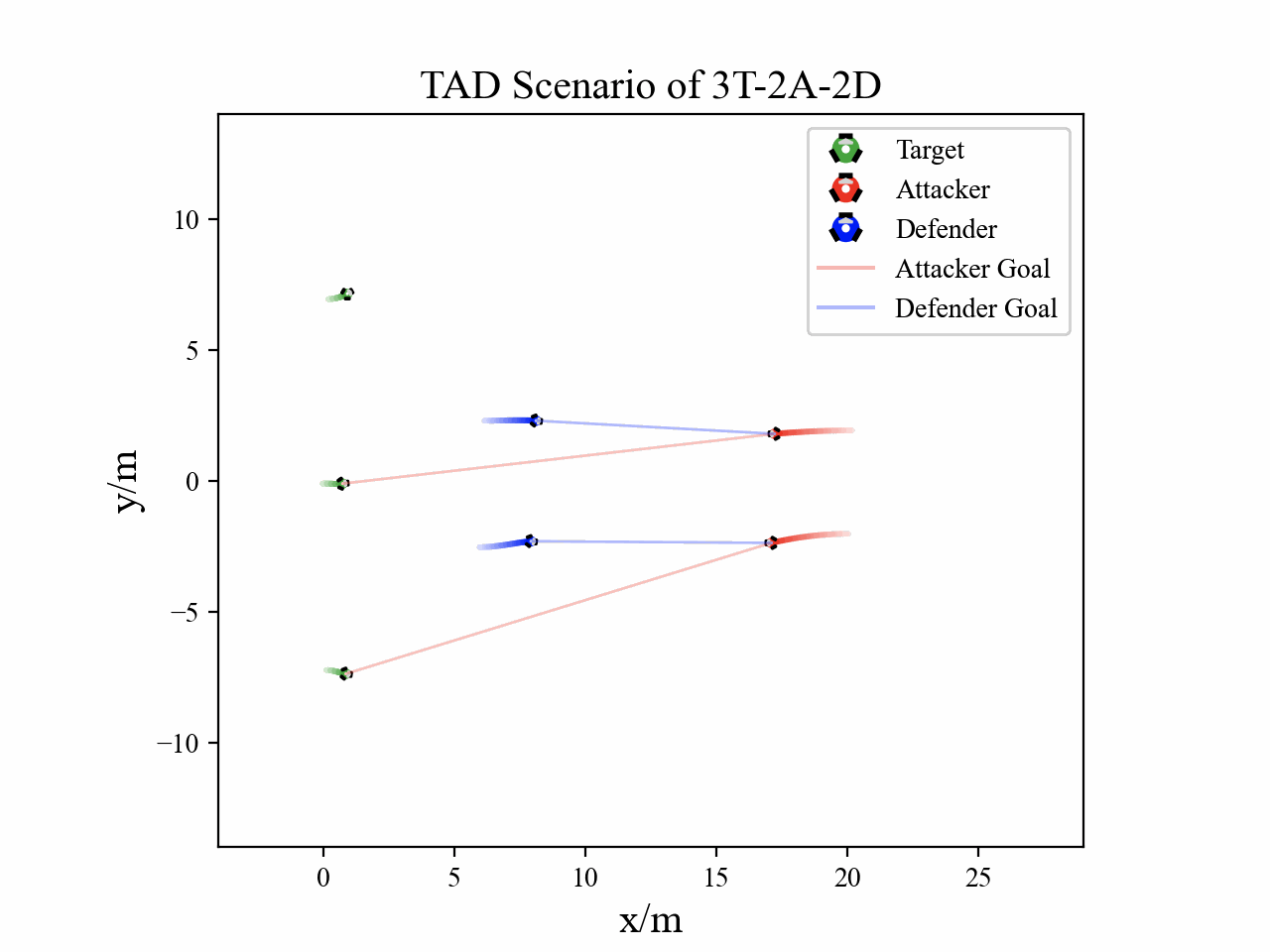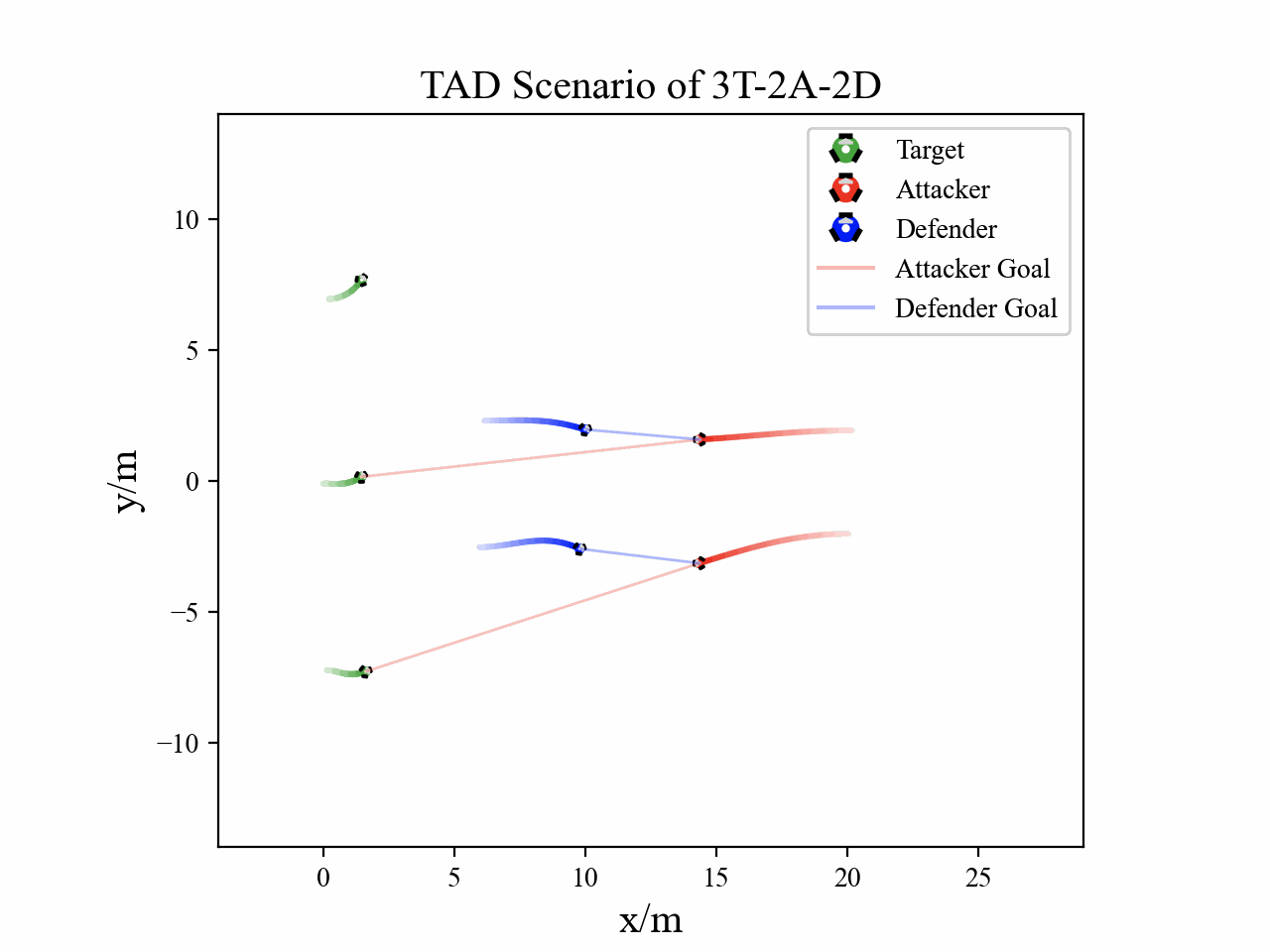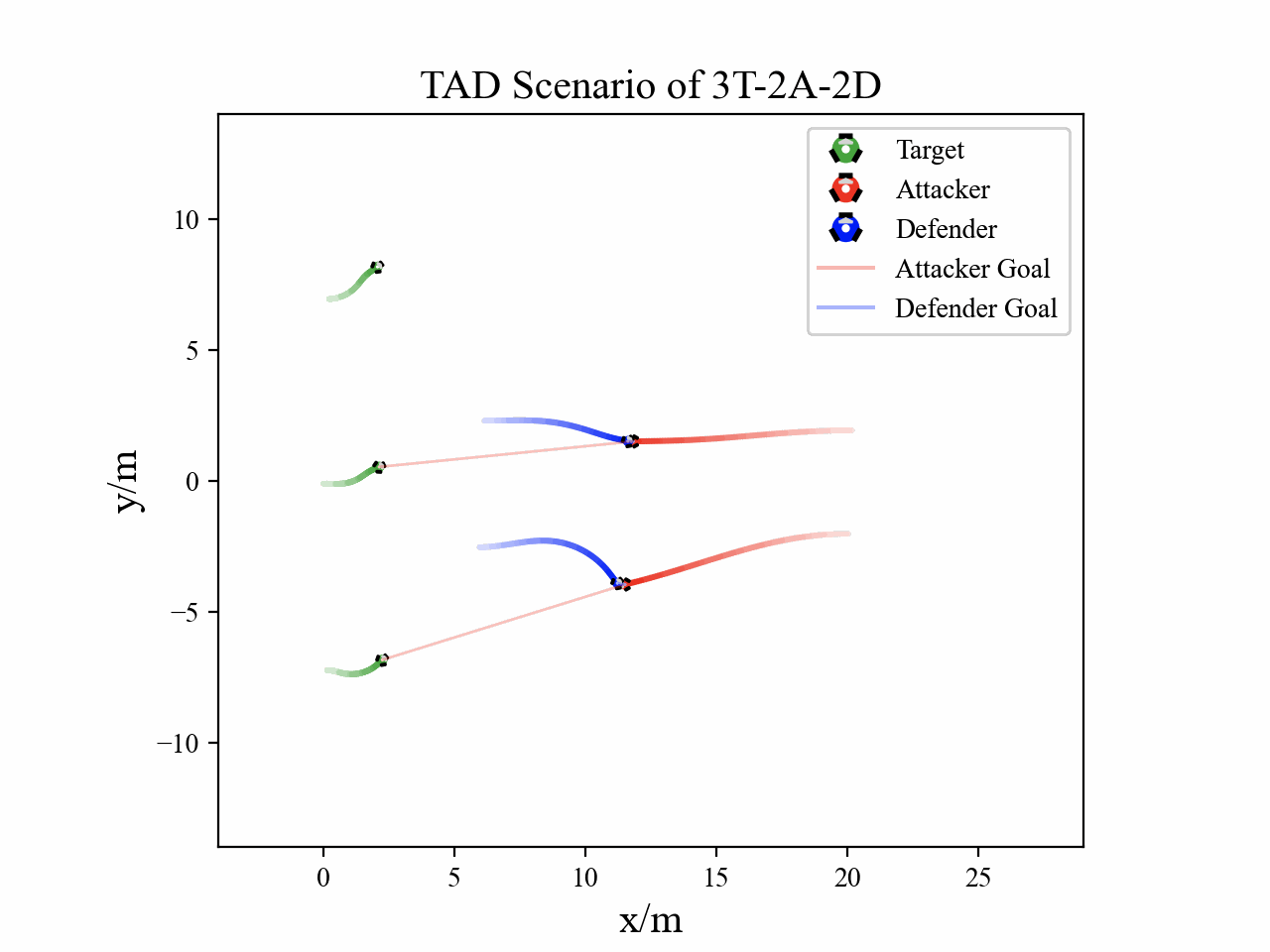
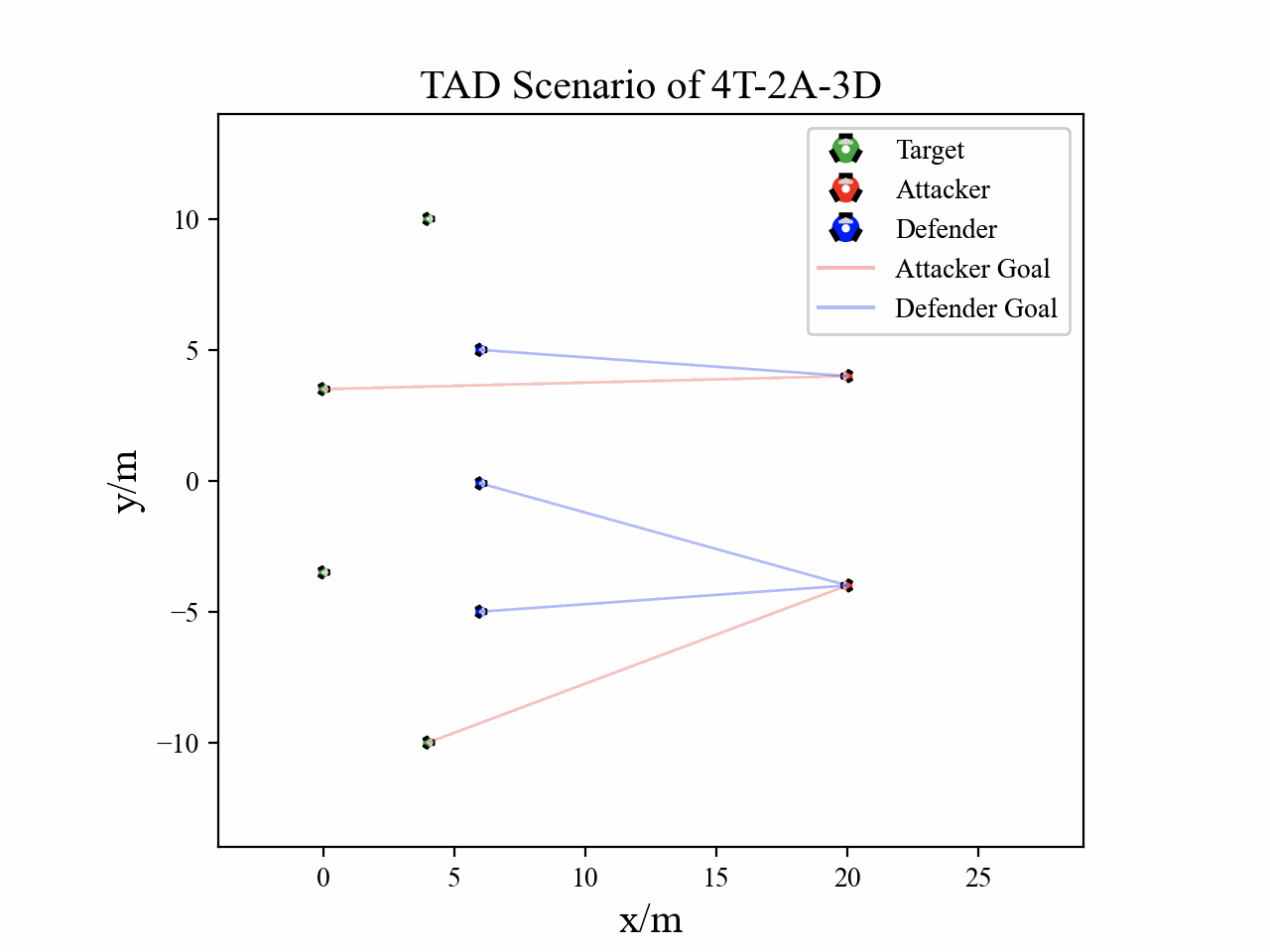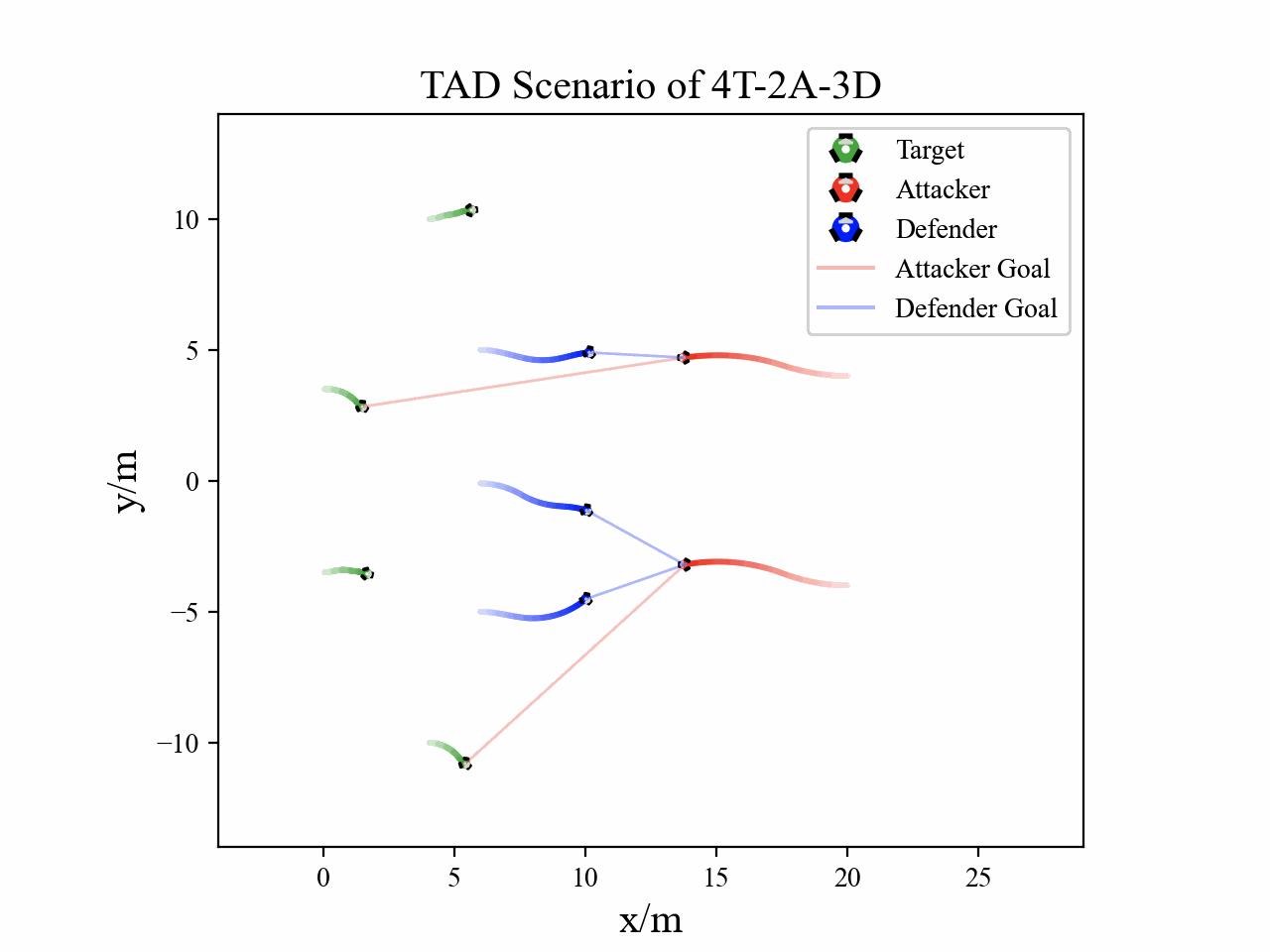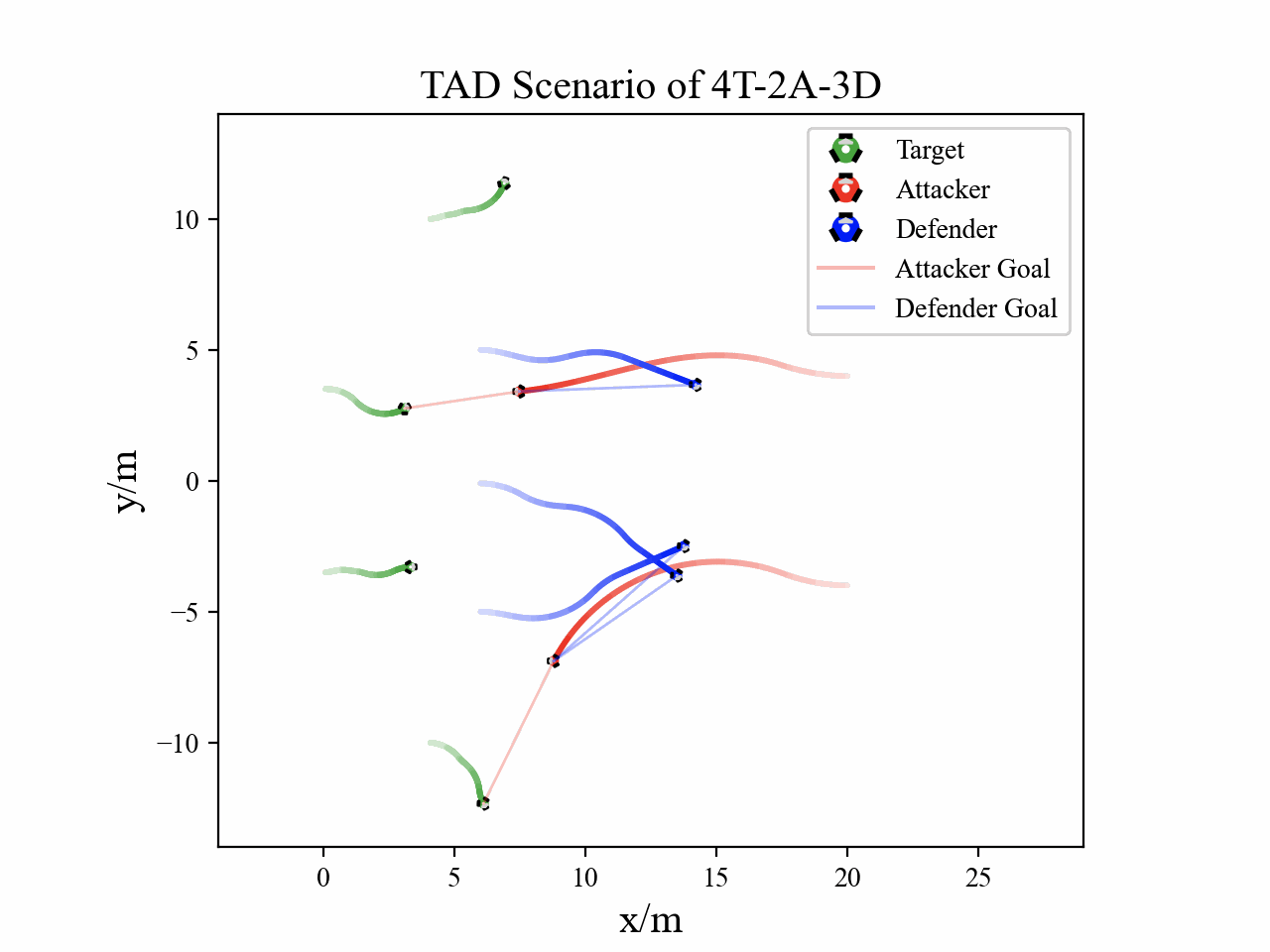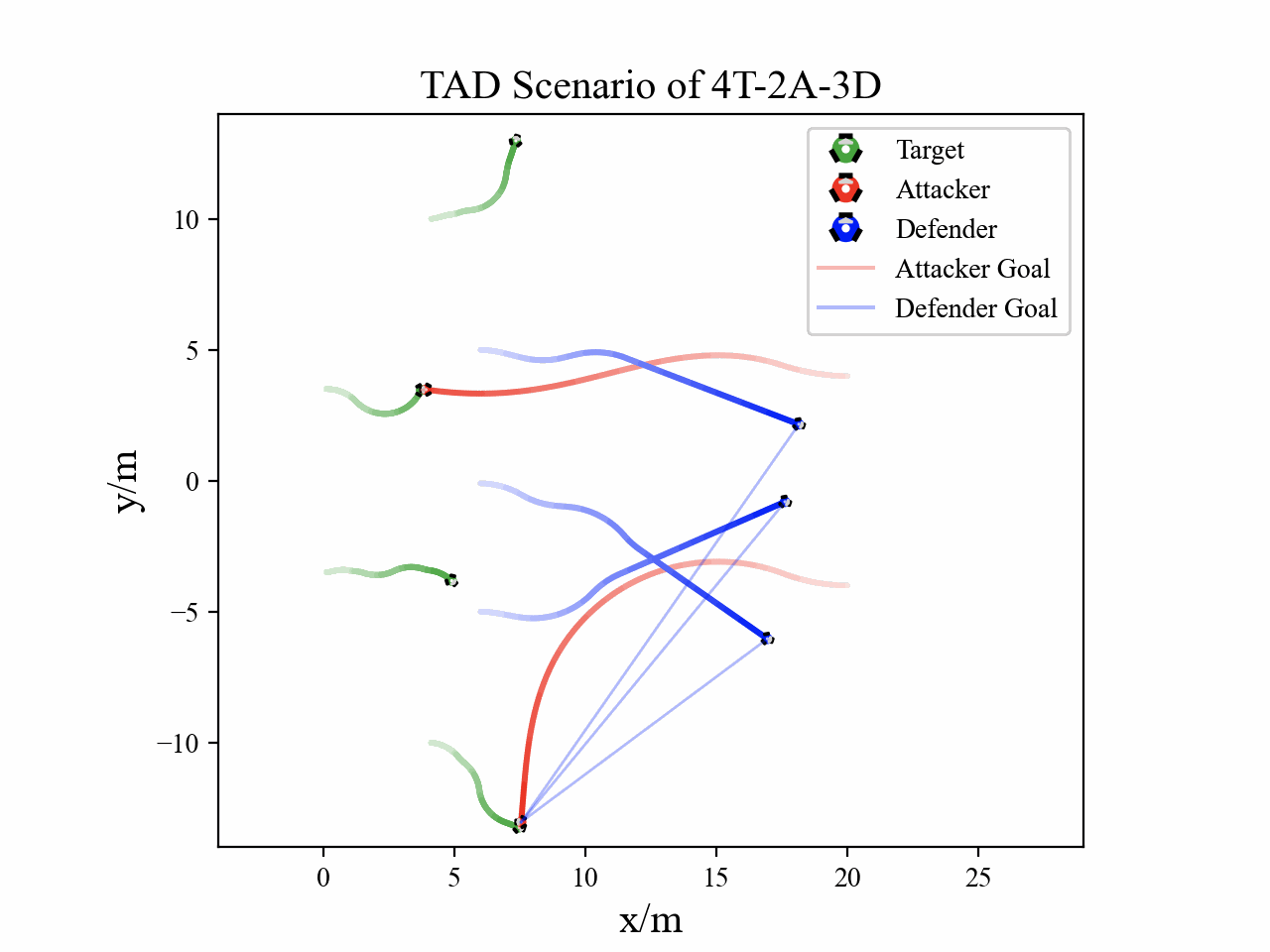
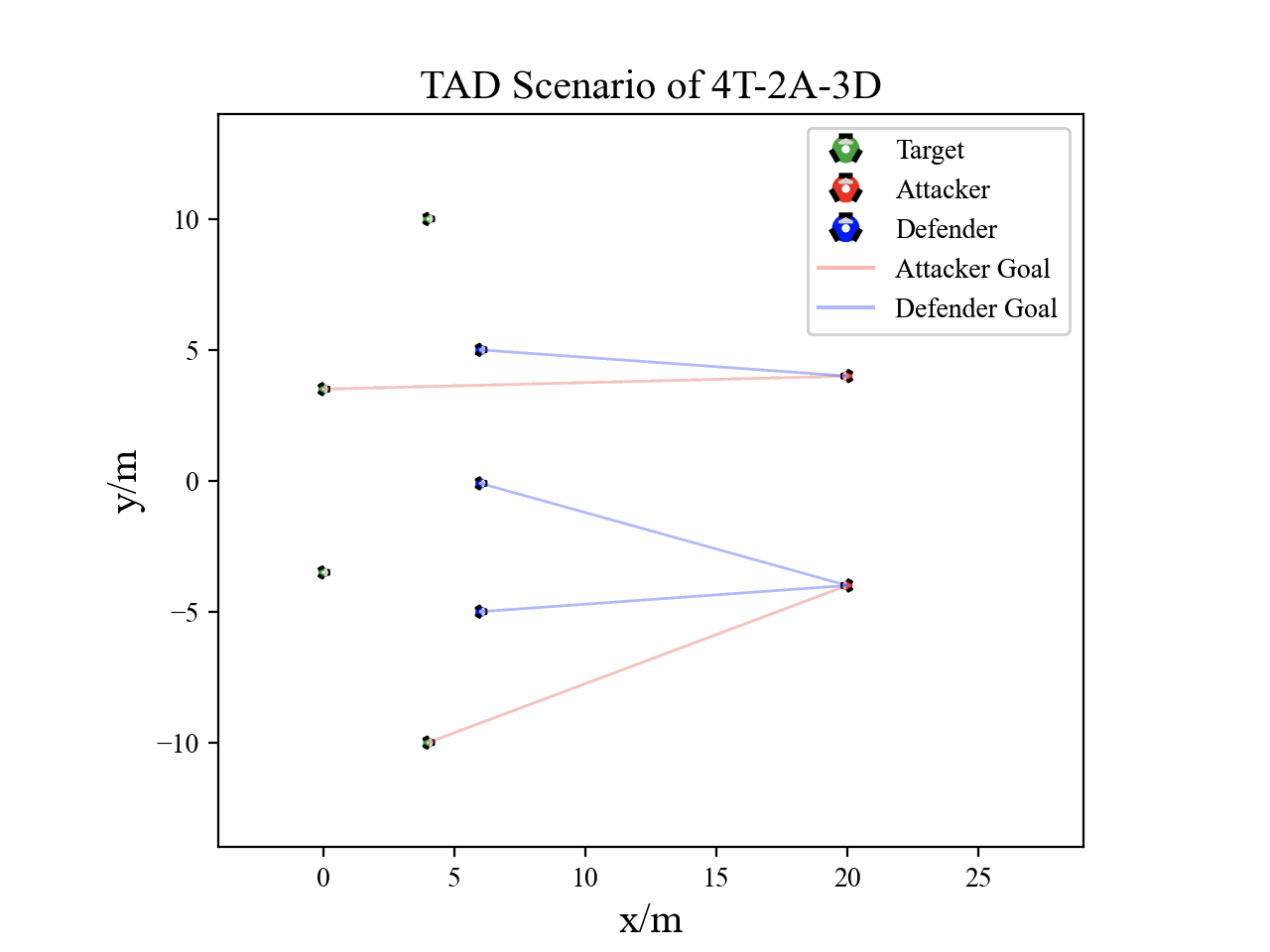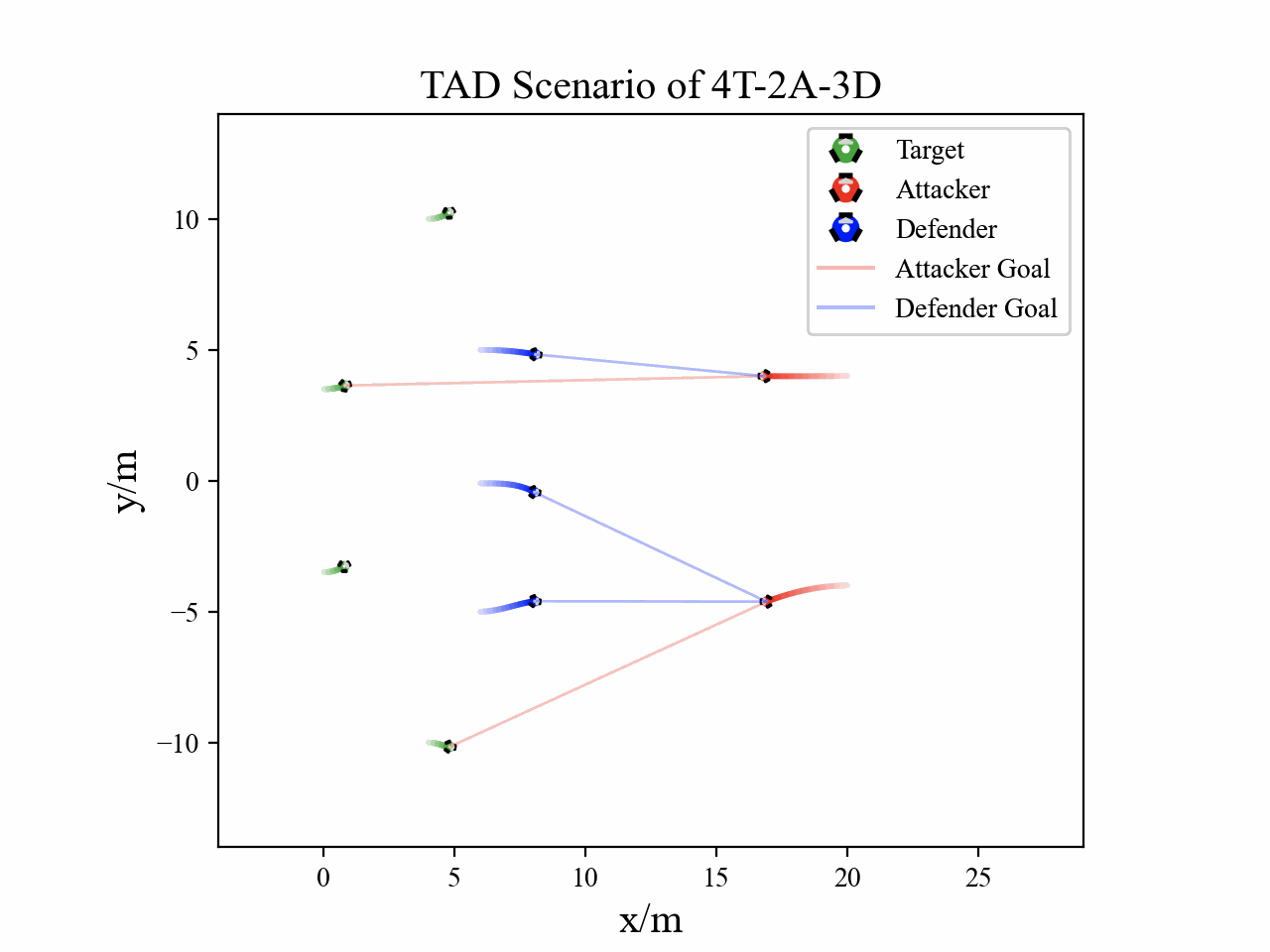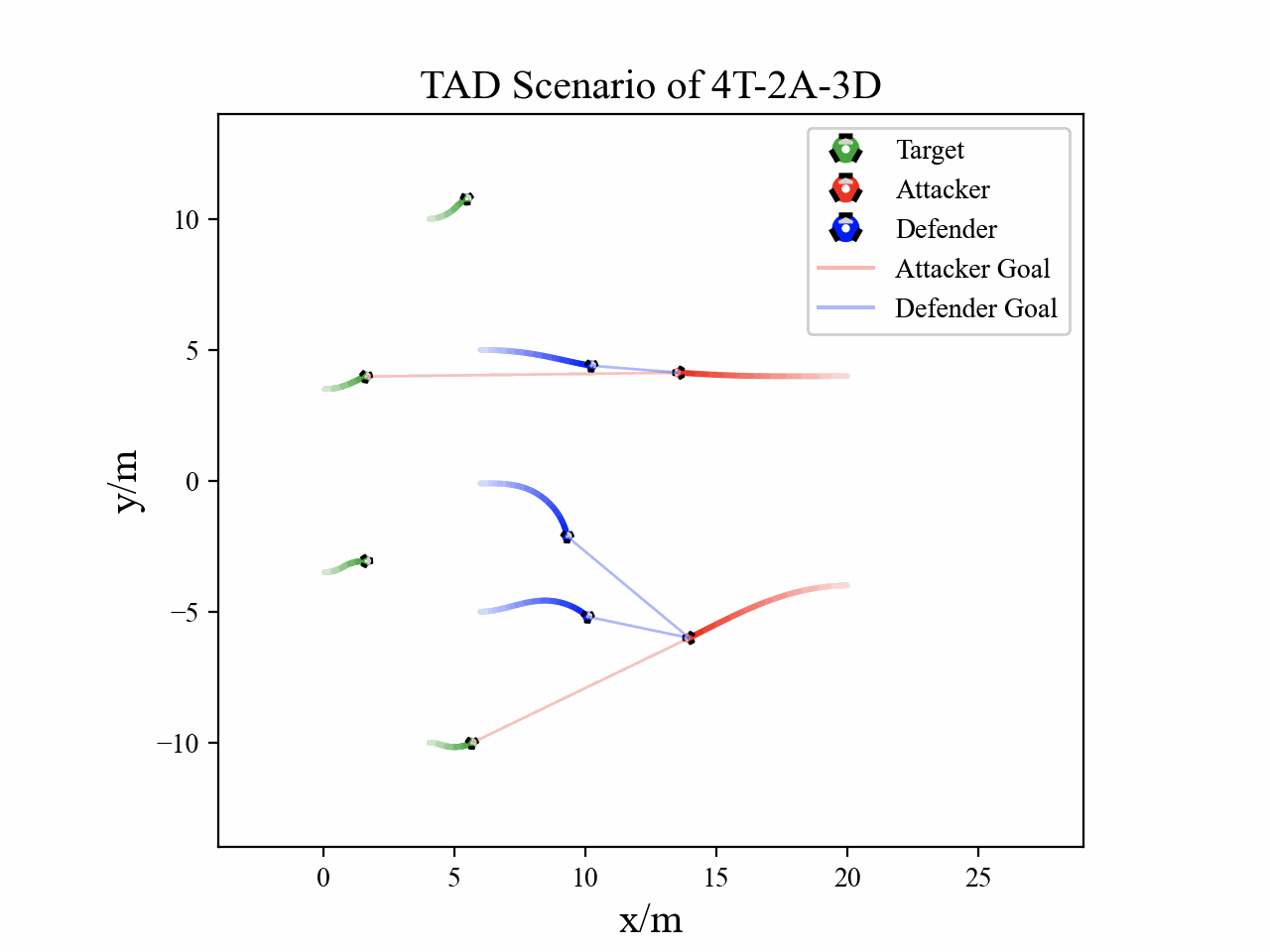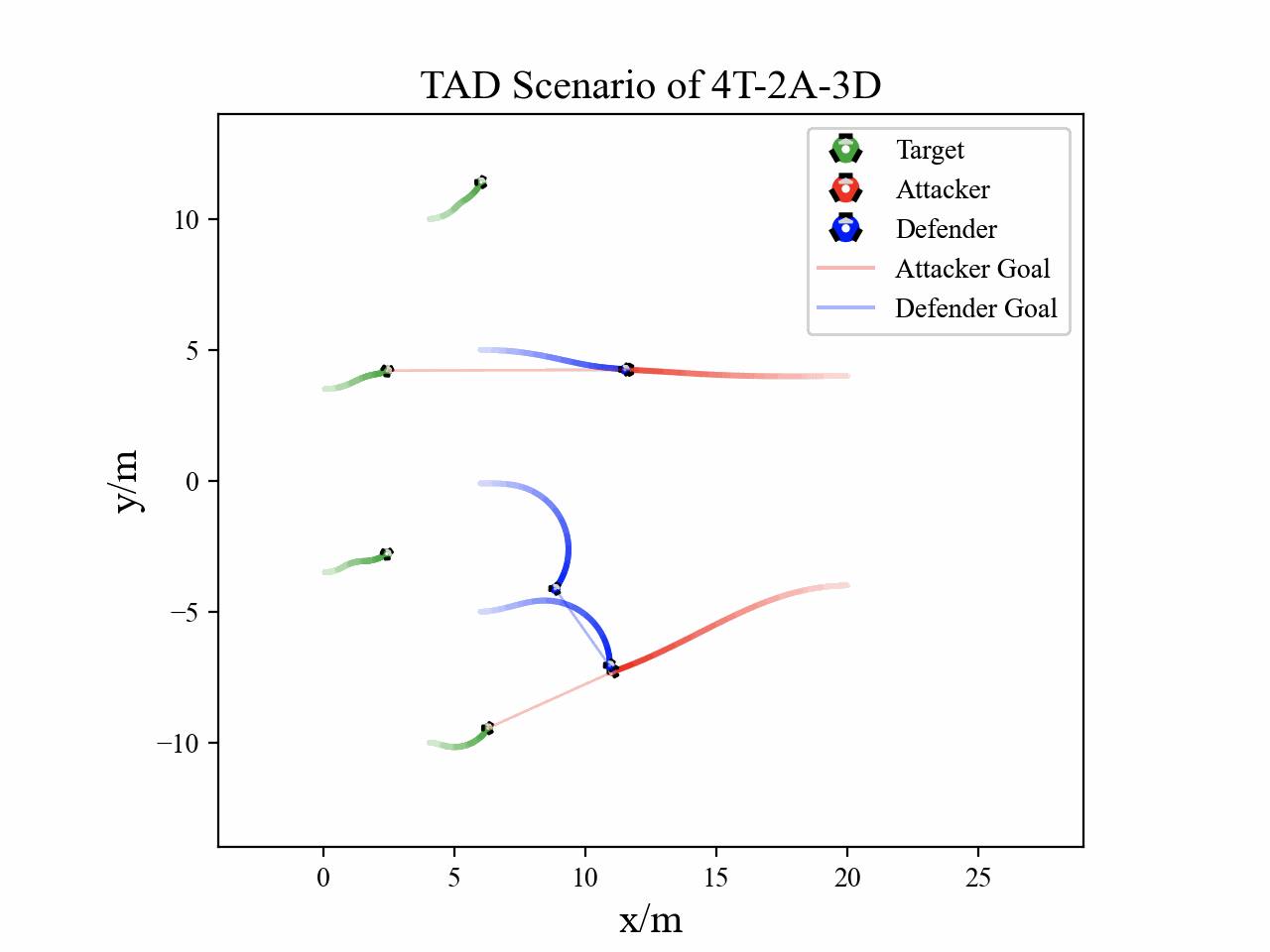
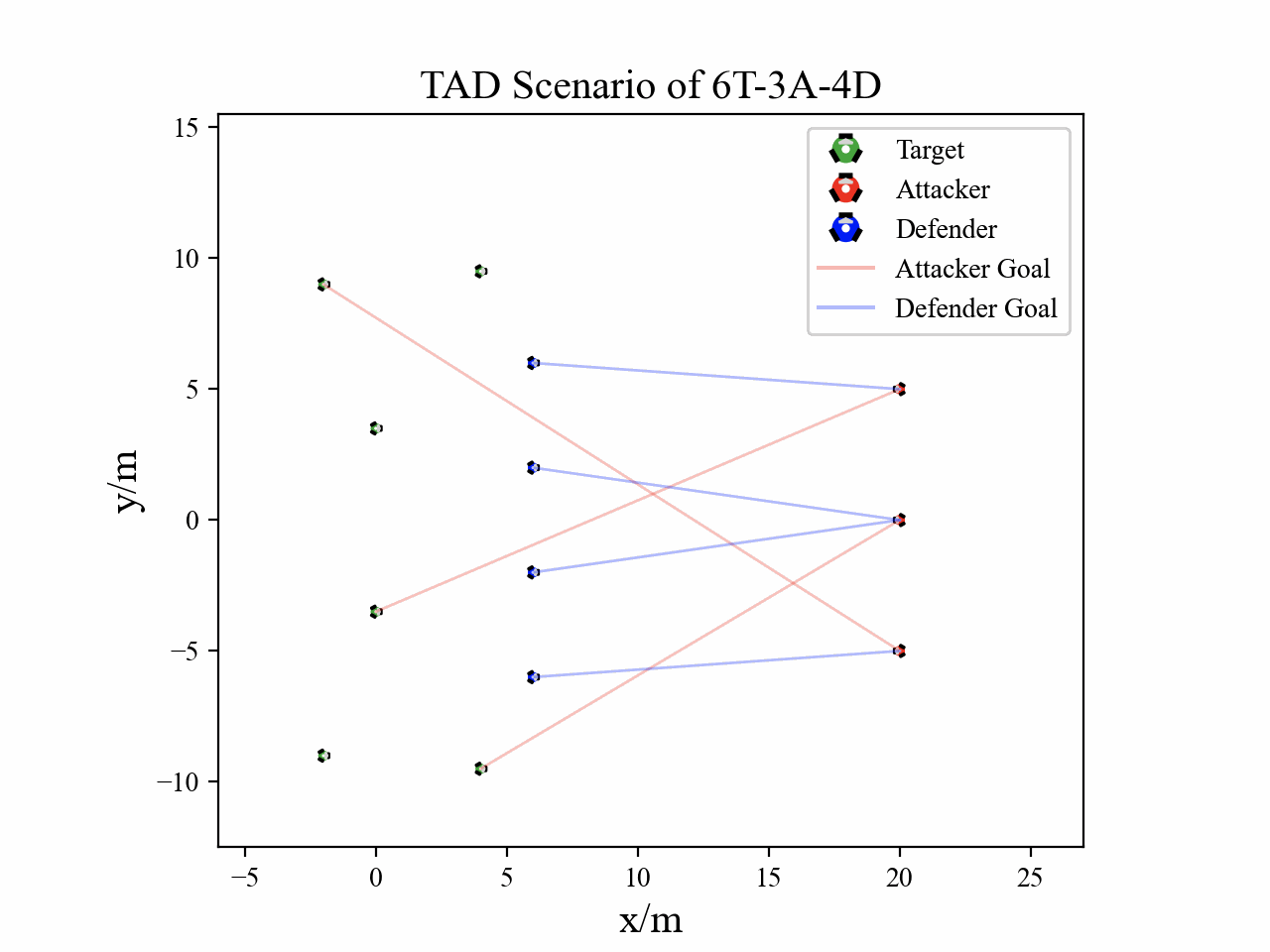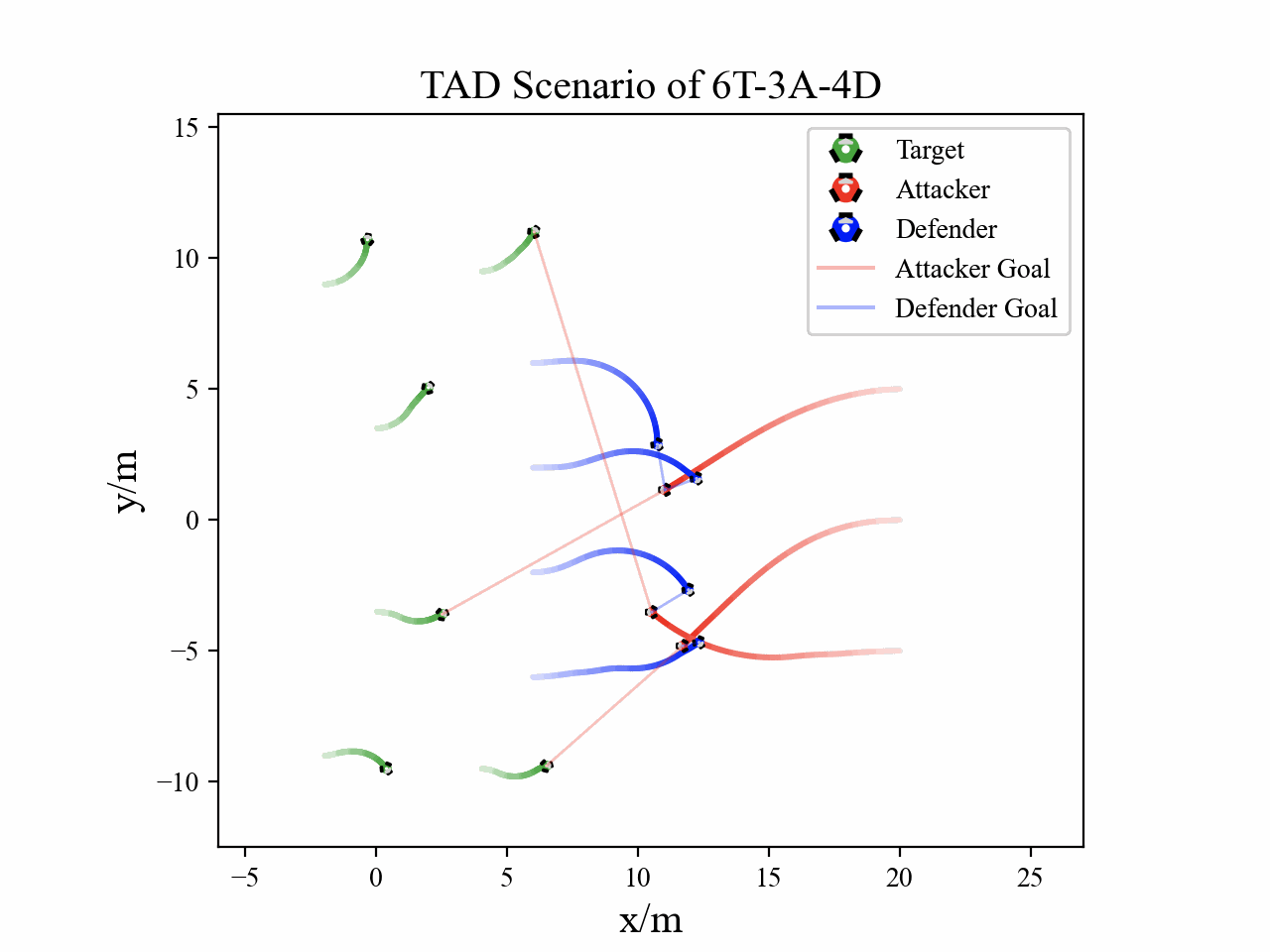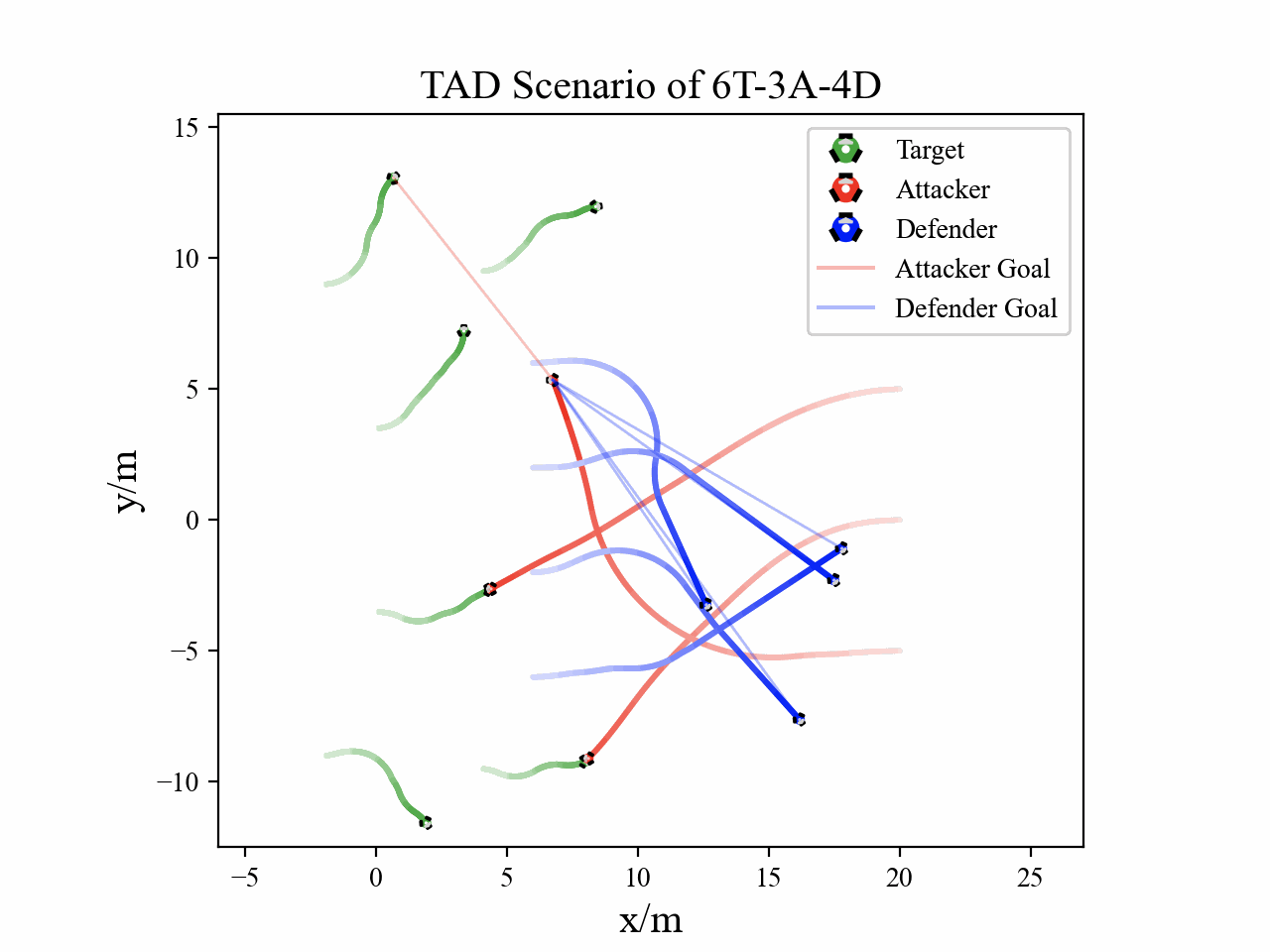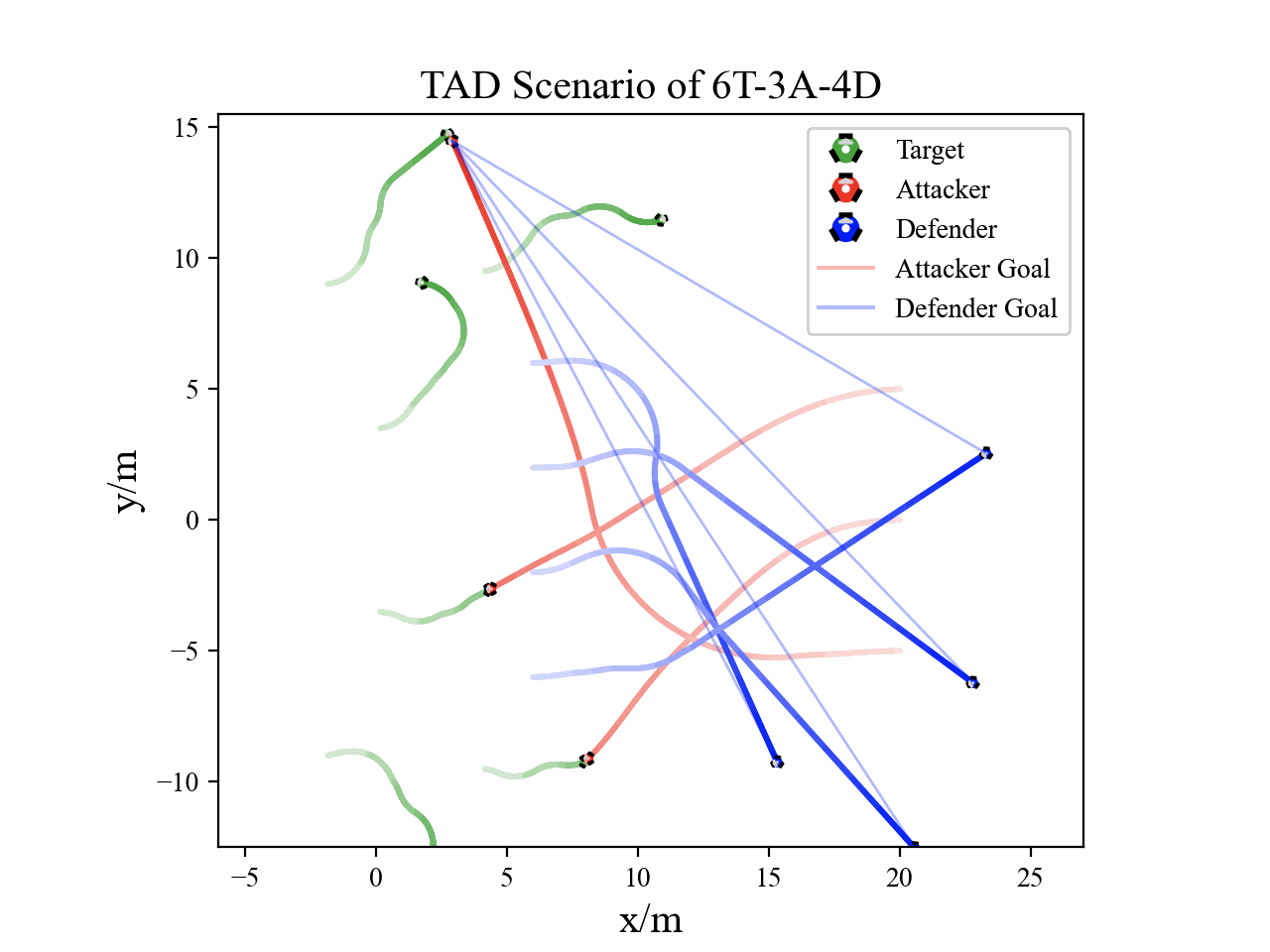
The following figures describe the overall structure of this work, and the illustration of Target-Attacker-Defender game. Use T, A, and D to denote Target, Attacker, and Defender, respectively.
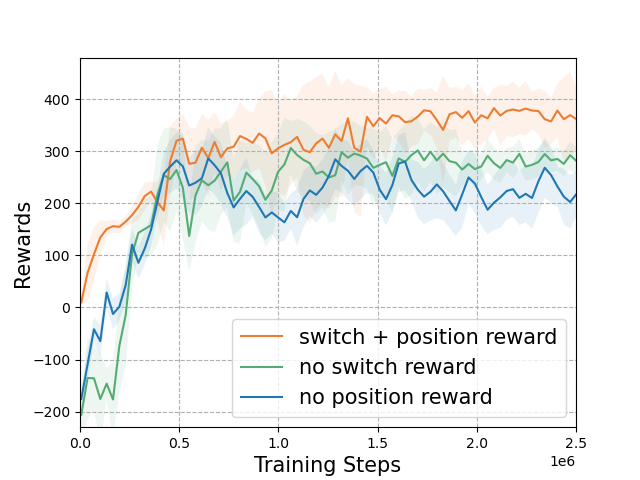
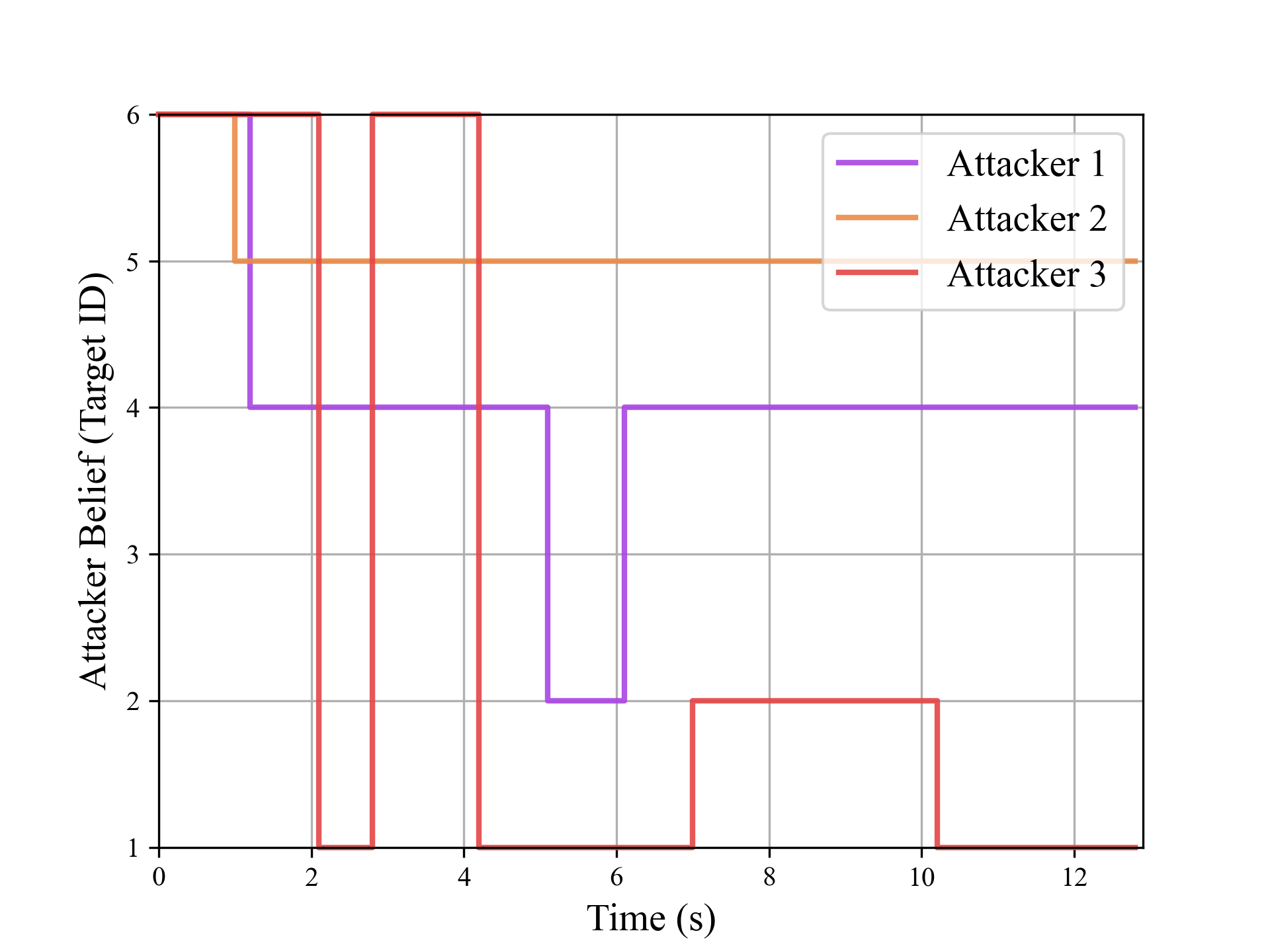
The following figures illustrate the training reward and the belief switch process in 6T-3A-4D scenario.