
A Policy-Guided Reinforcement Learning Method for Encirclement Control in Multi-obstacle Environment
Abstract
The problem of multiagent encirclement with multiobstacle collision avoidance (EMOCA) has been challenging since it is difficult to balance the trade-off between surrounding a mobile target and avoiding obstacles simultaneously. To address the EMOCA problem, we proposed a novel policy-guided reinforcement learning (RL) method, namely, multiregulator-assisted RL for encirclement control (MRA-RLEC) which leverages the jump-start learning and curriculum learning (CL) mechanism to enhance training efficiency. MRA-RLEC divides the complex encirclement task into a sequence of subtasks, progressively increasing in difficulty. In this process, multiple regulators are utilized to adjust various training aspects, including encirclement condition, obstacle avoidance, and the transition from guide to learned policy execution. Besides, a global encirclement reward decomposition (GERD) method is presented to alleviate reward sparsity, and we design a bidirectional communication protocol to reduce communication. Extensive experiments are carried out to showcase the robustness and superiority of our method, and the practical applicability of MRA-RLEC is demonstrated through experiments conducted in the robot operating system 2 (ROS2)-based simulation platform, Gazebo, using a self-designed omnidirectional vehicle model.
Index Terms—Curriculum learning (CL), encirclement control, multiagent reinforcement learning (MARL), multiobstacle collision avoidance.
Contributions
- A novel multiregulator-assisted RL for encirclement control (MRA-RLEC) scheme is proposed to tackle the encirclement problem of a moving target in an unbounded, multiobstacle environment. The training efficiency and convergence are improved through multiple regulators and the guide policy.
- A global encirclement reward decomposition (GERD) method is presented to alleviate reward sparsity, encouraging the achievement of terminal encirclement condition. Moreover, a bidirectional communication protocol is designed to reduce communication load.
- Comparative experiments are conducted to demonstrate the scalability and robustness of our method. Besides, the model is tested in Gazebo with robot operating system 2 (ROS2), based on a self-designed omnidirectional vehicle platform to verify the probability of real-world application.
Visualization
The following GIFs illustrate the encirclement process of multiple pursuers trained using our proposed MRA-RLEC method in environments with multiple obstacles. The pursuers successfully navigate around obstacles to encircle the moving target effectively.
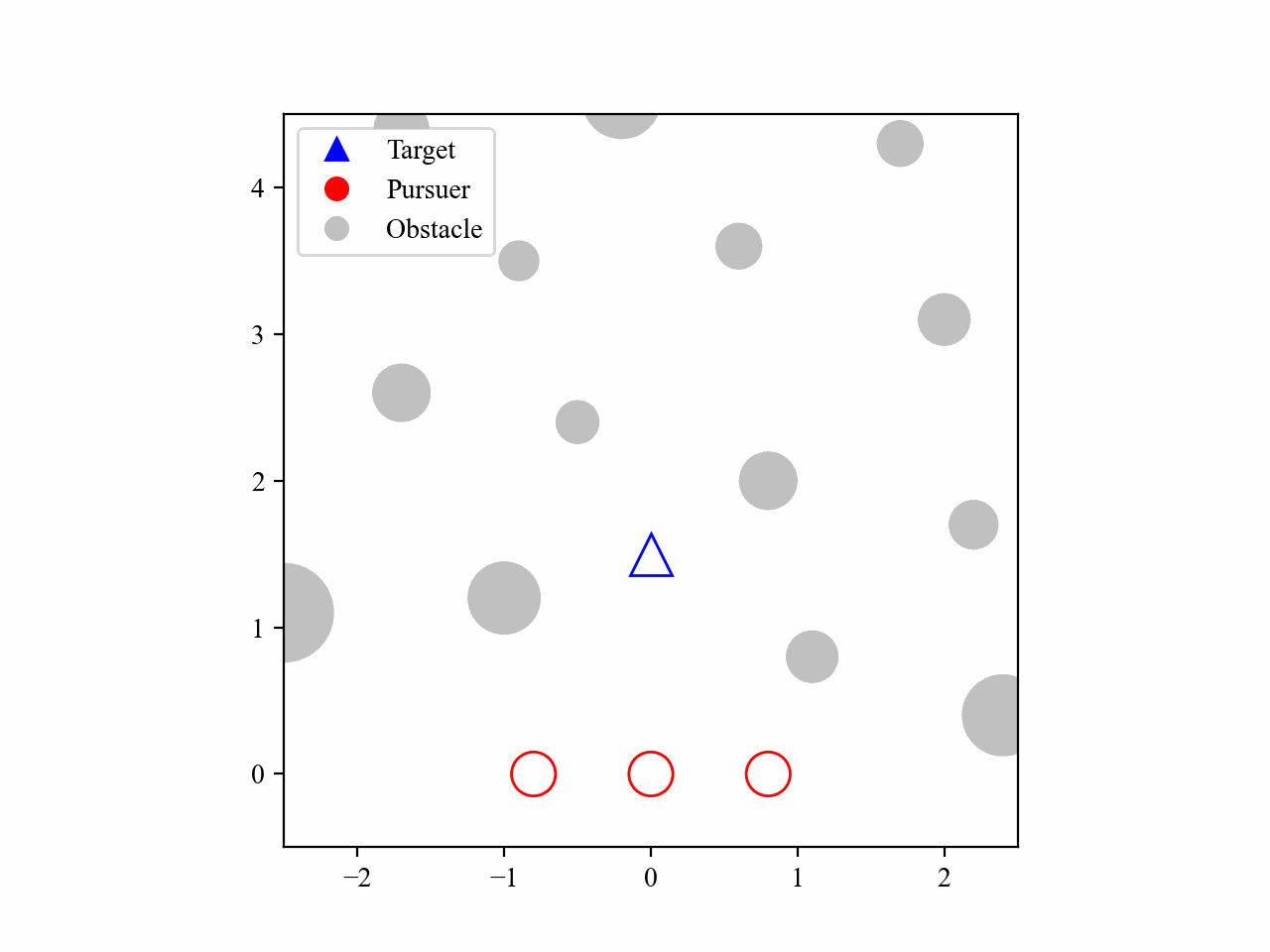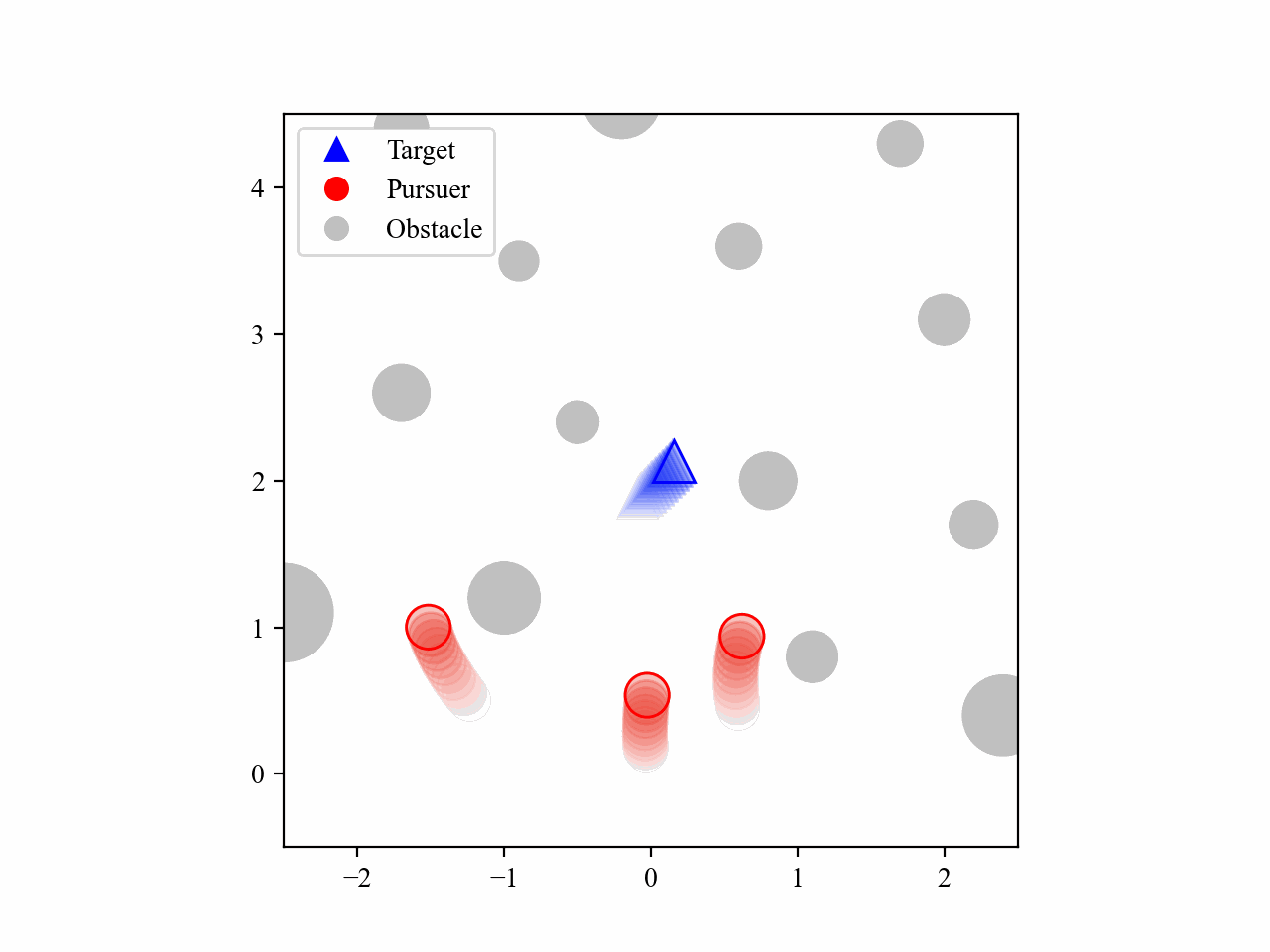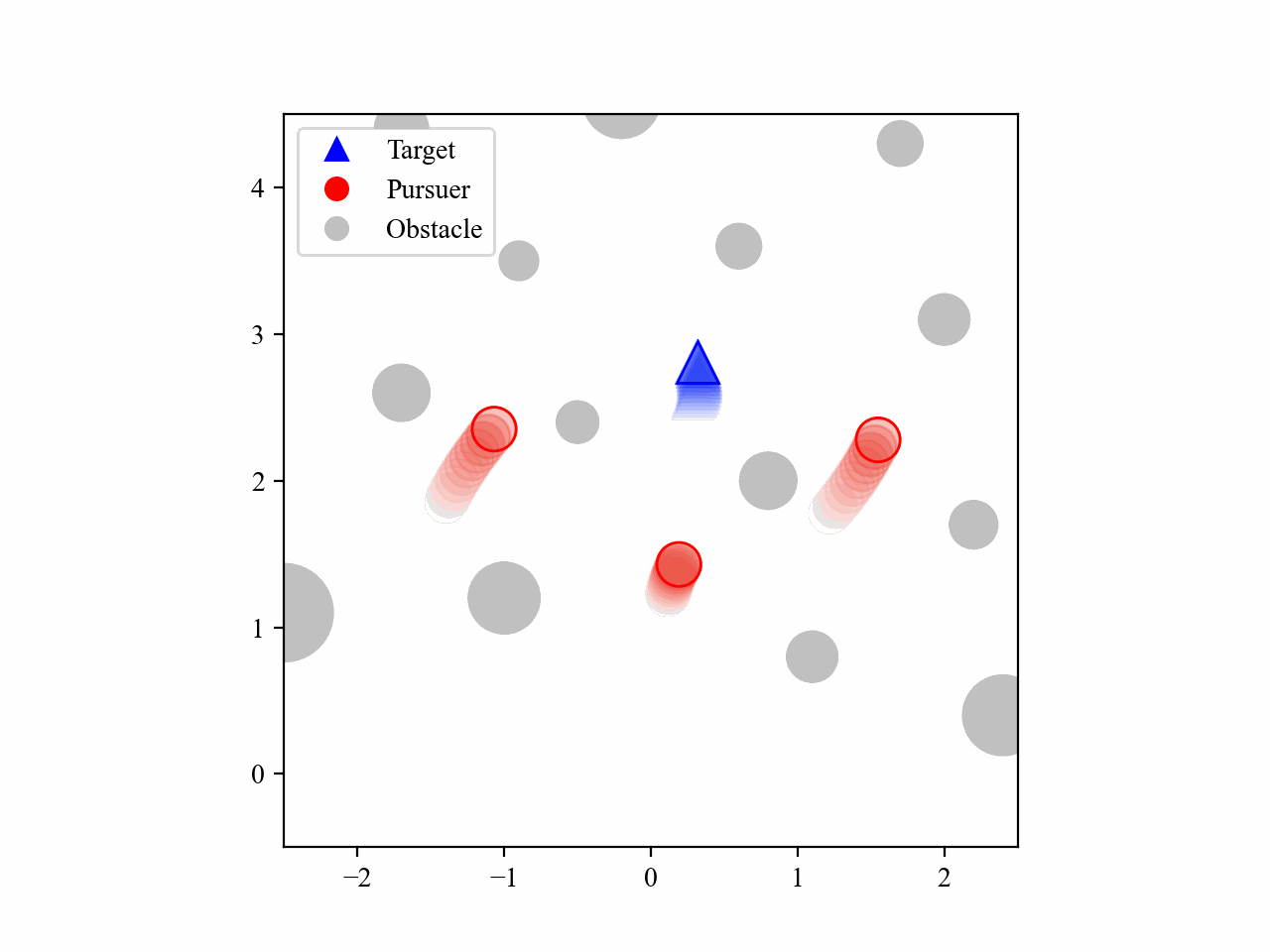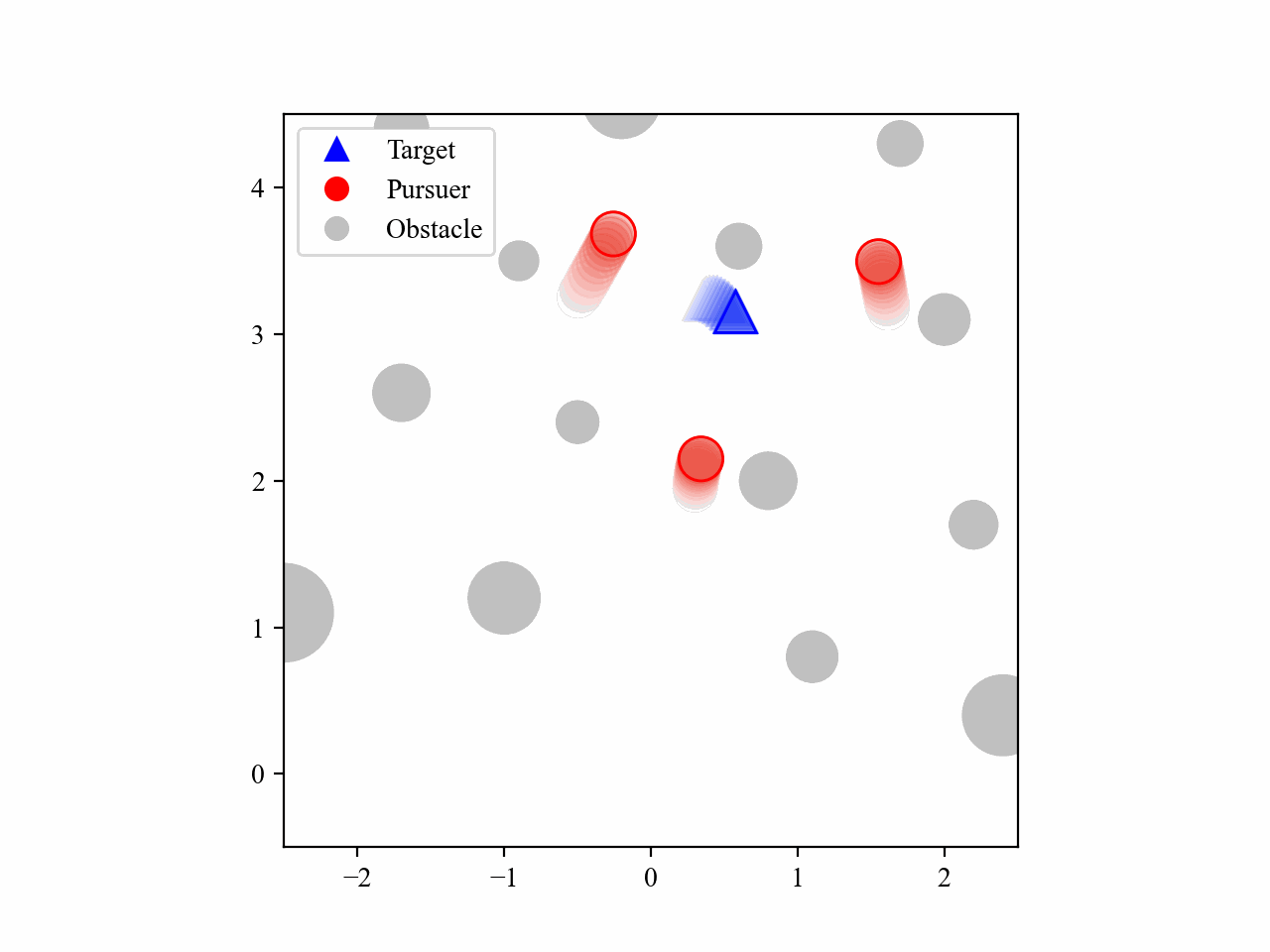
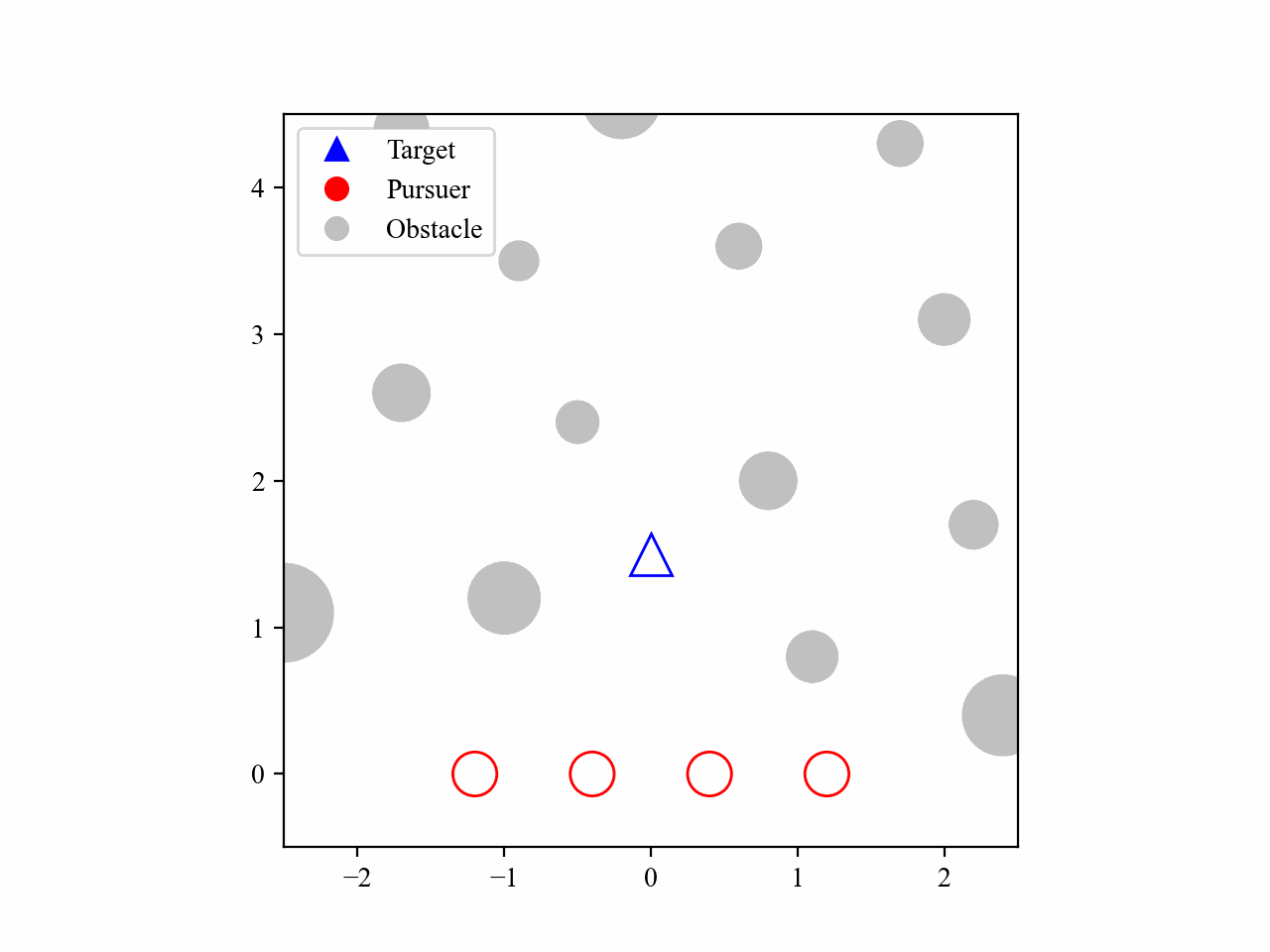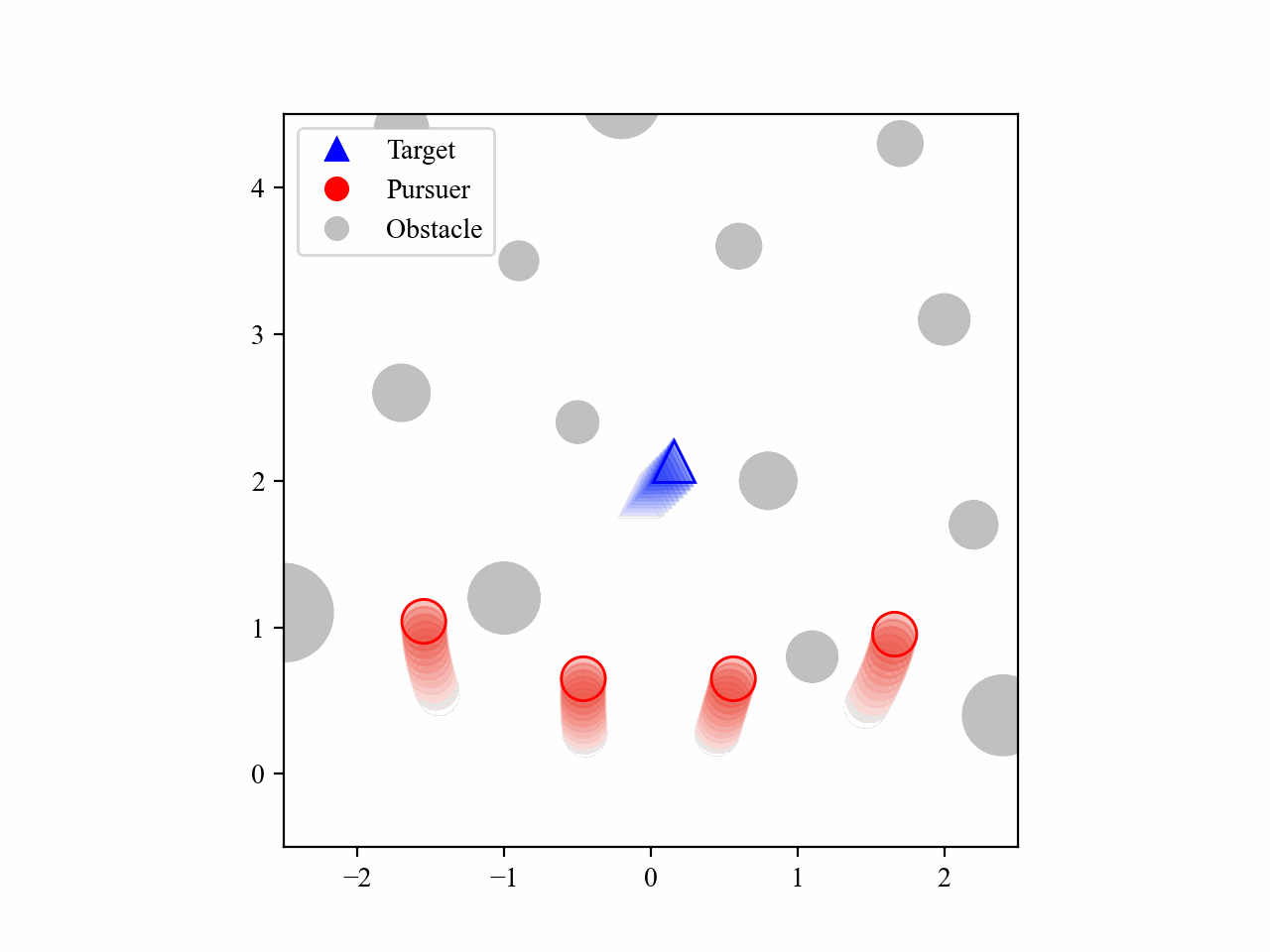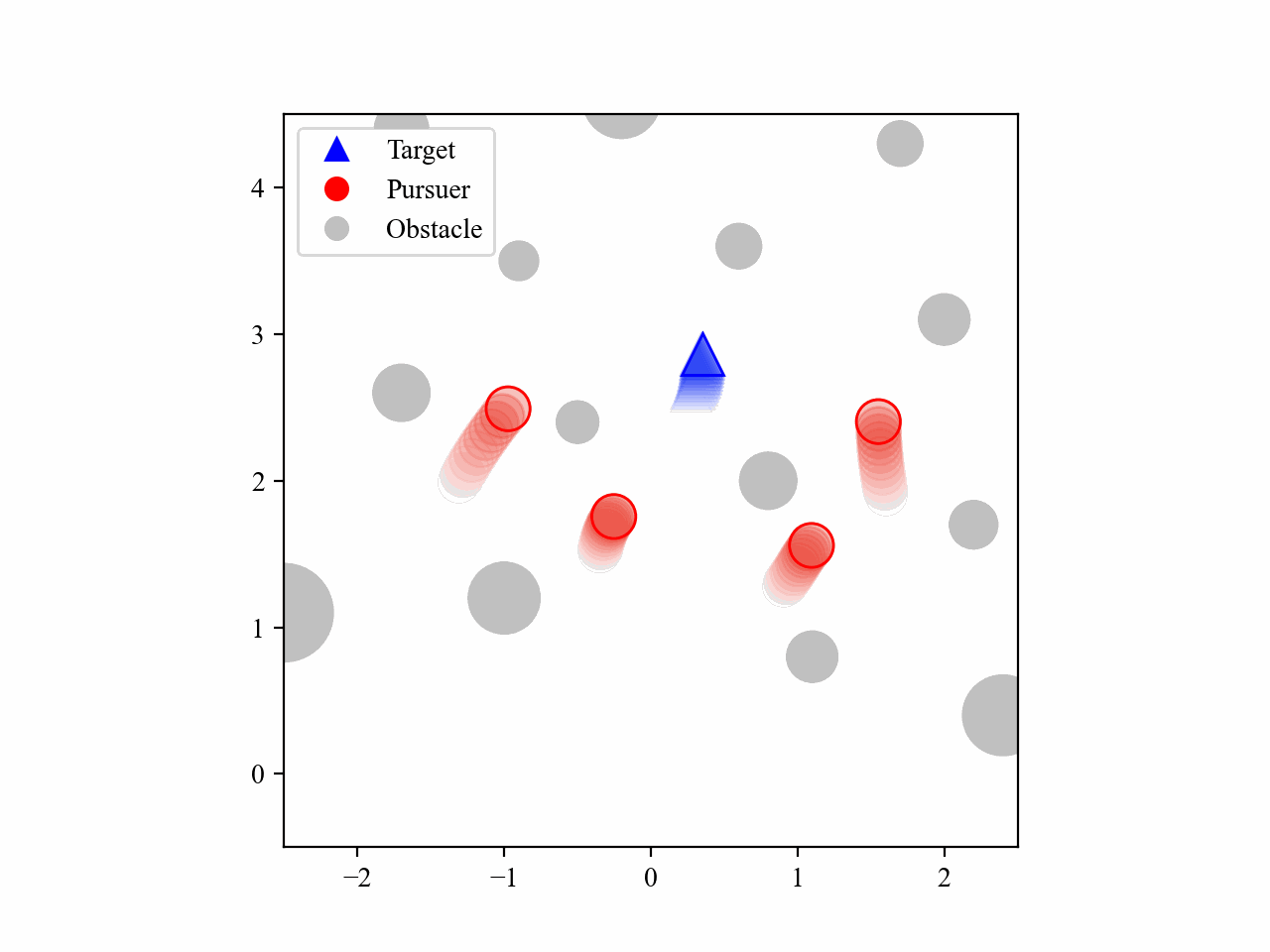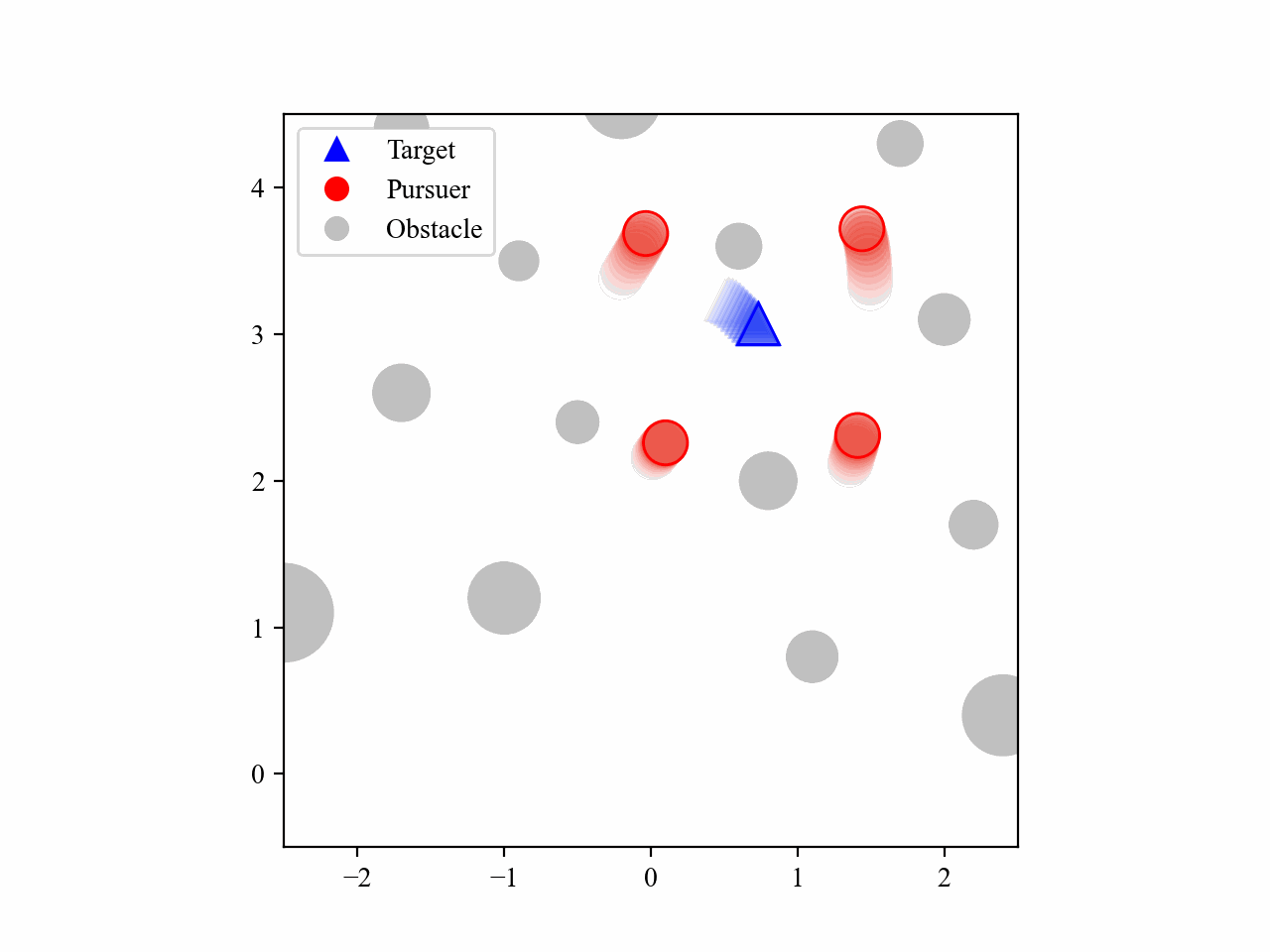
Besides, the model is capable of completing the encirclement task under different target policies, as shown below:
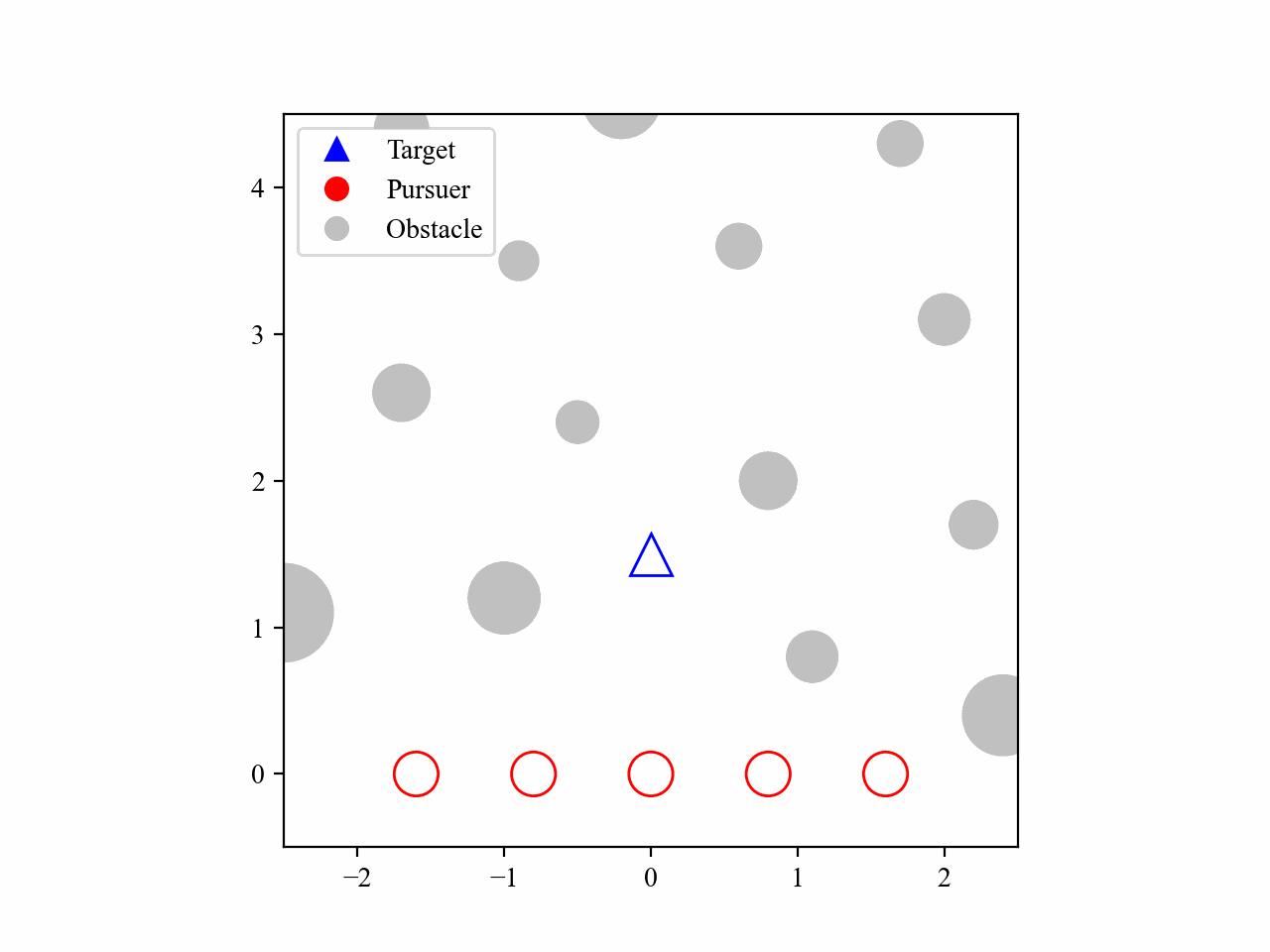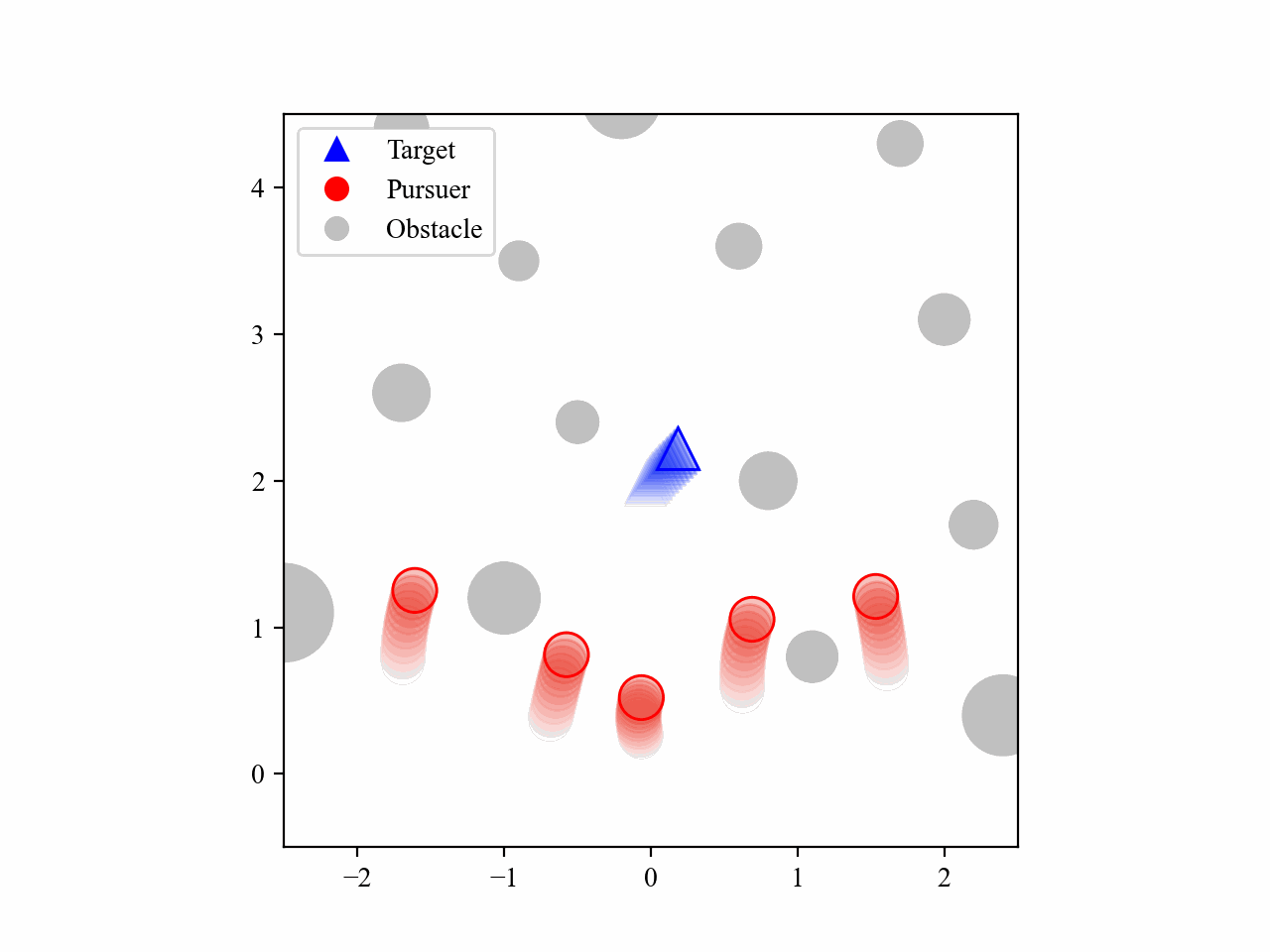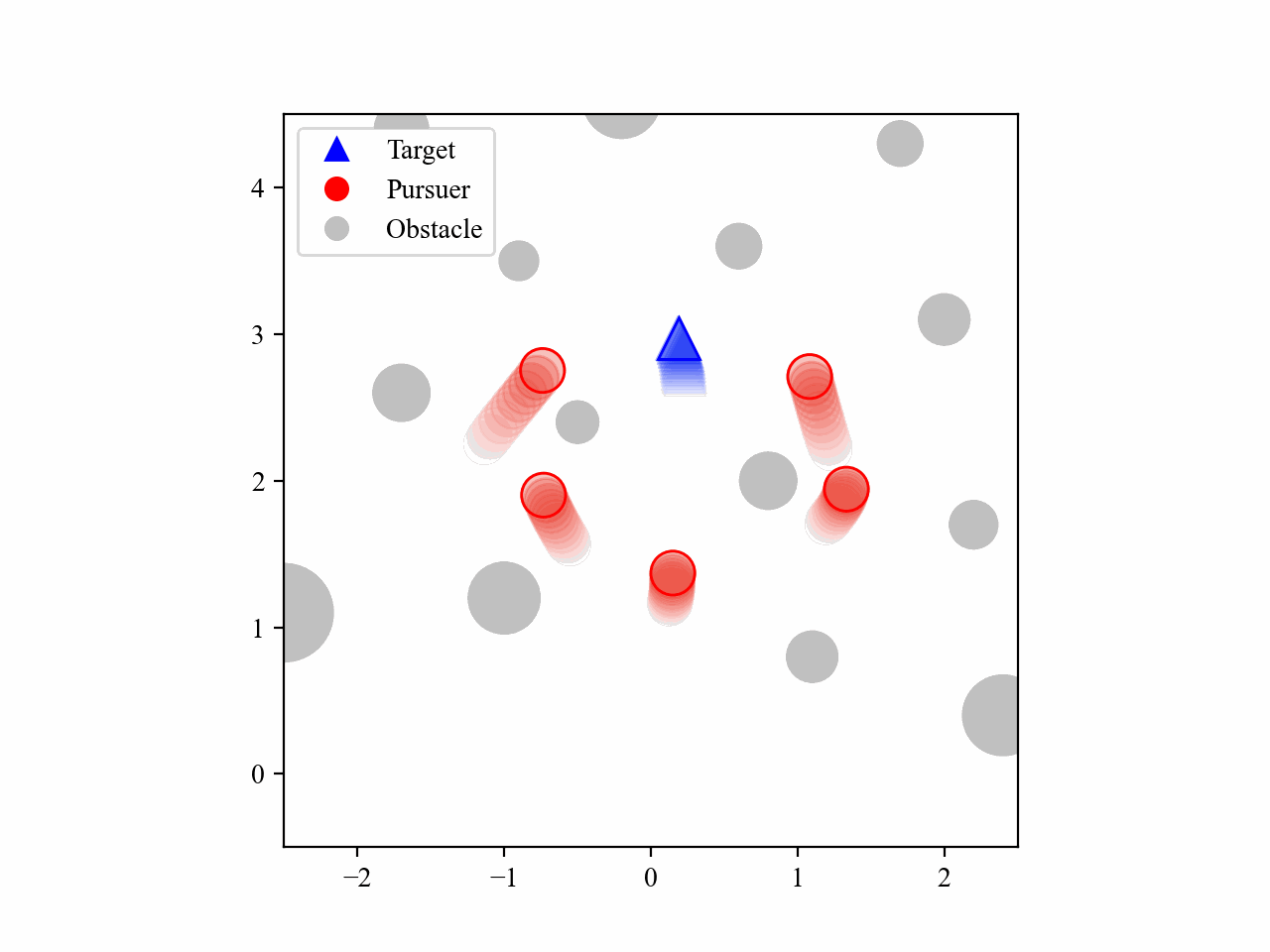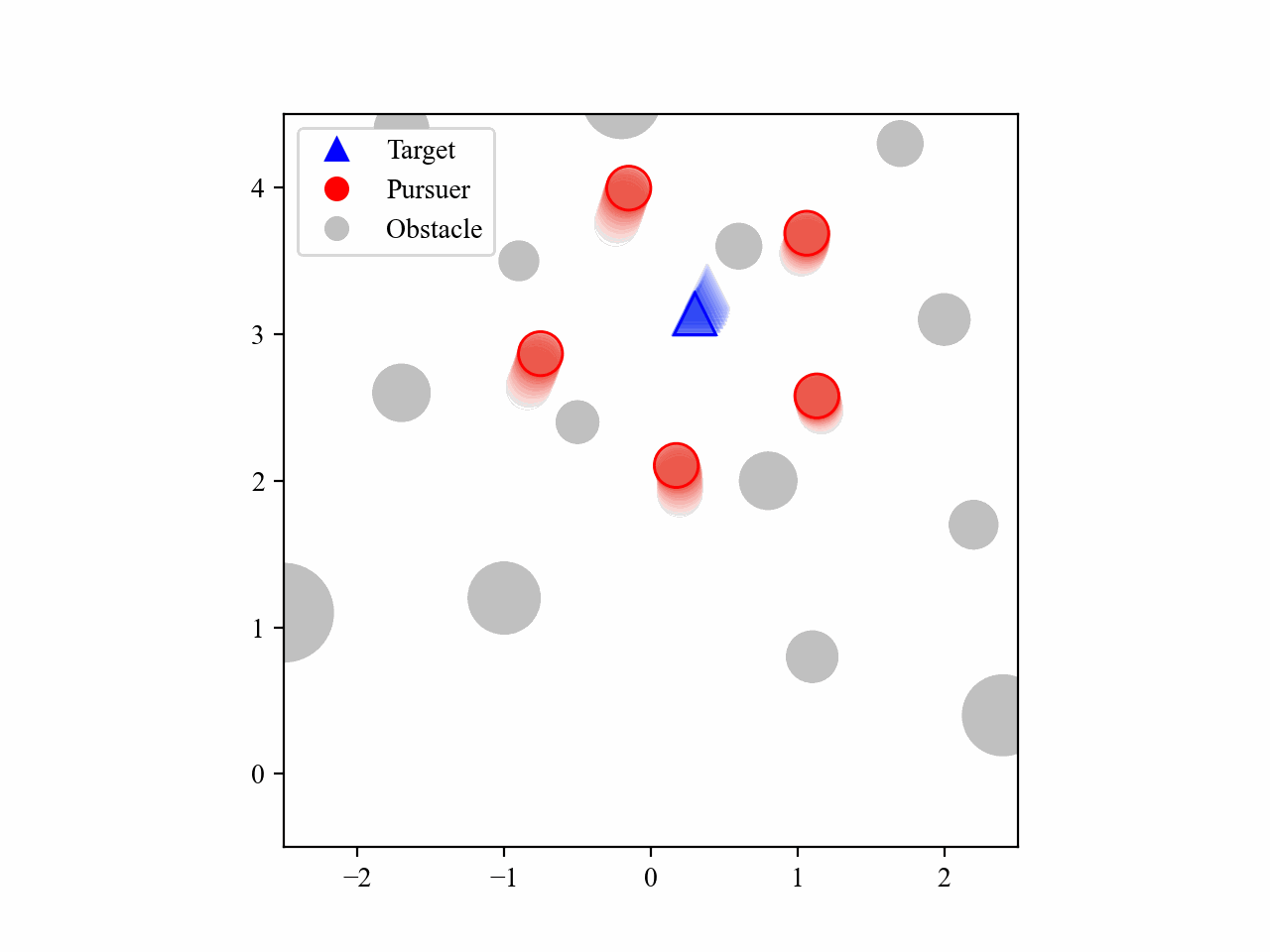
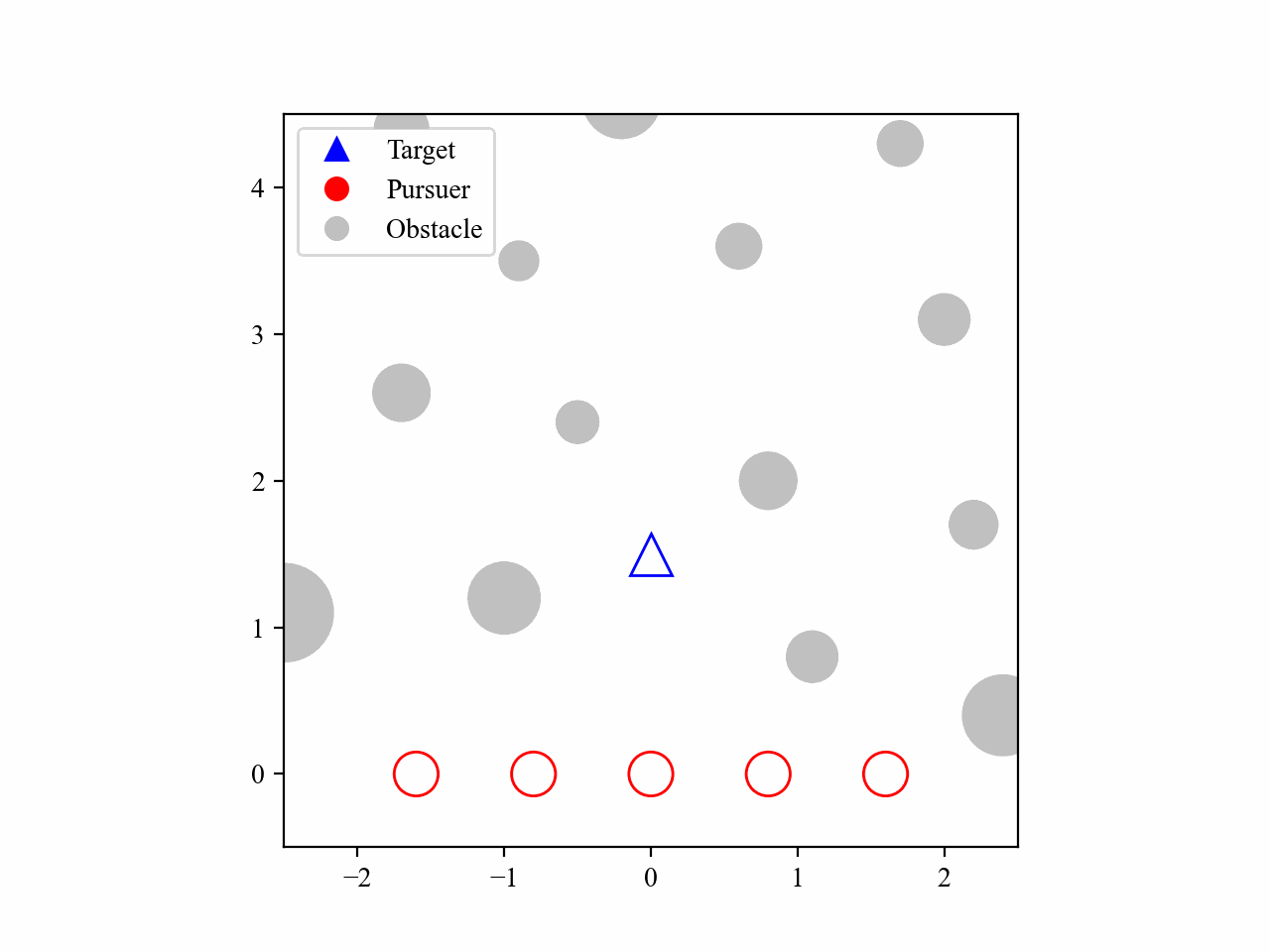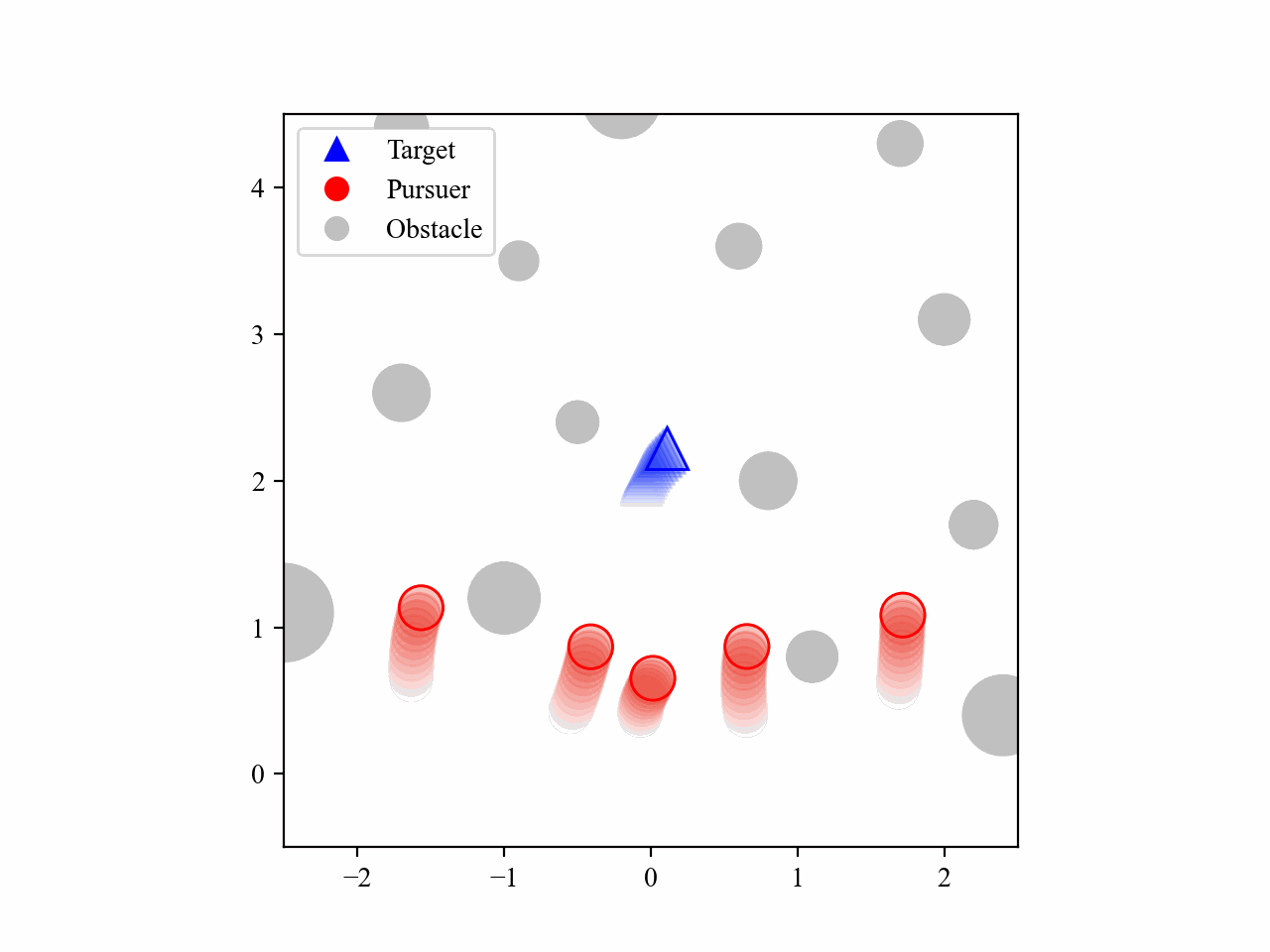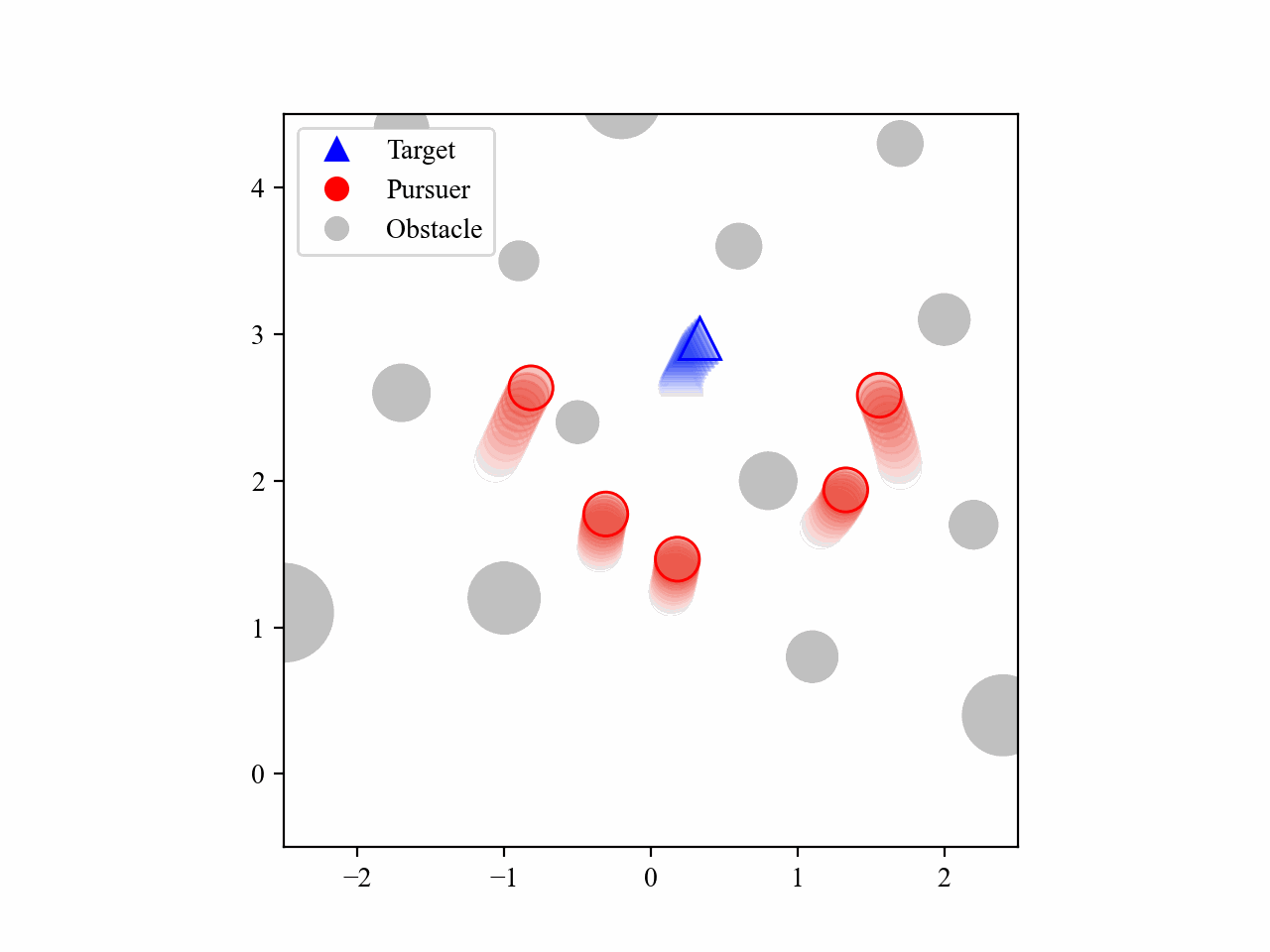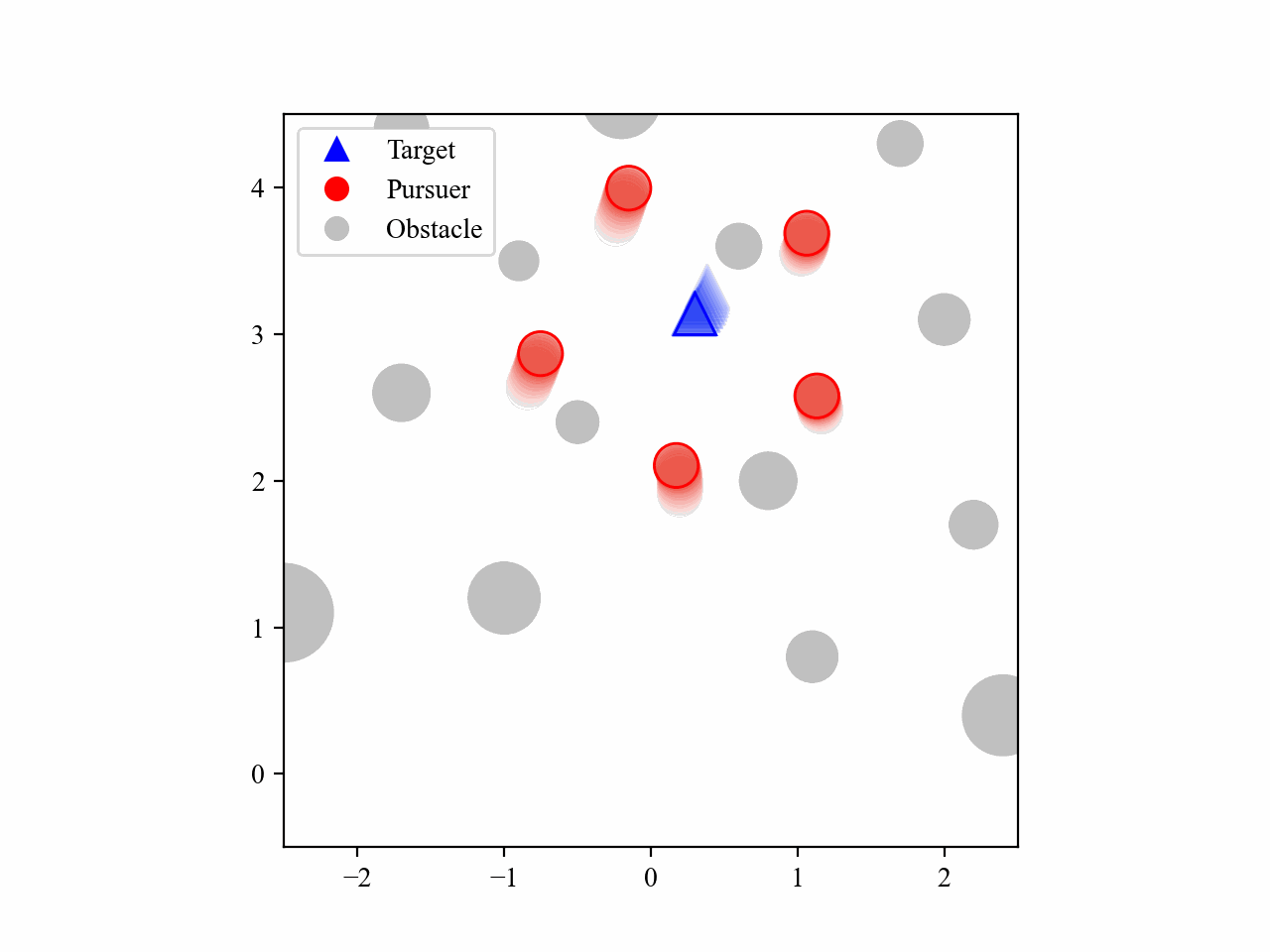
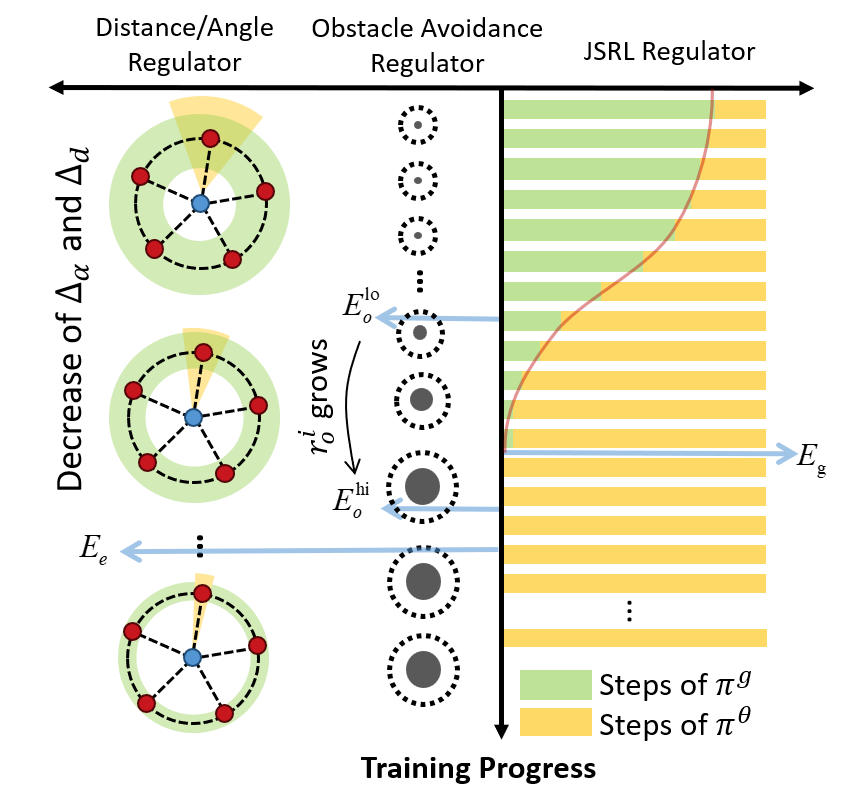
The curriculum learning process is regulated by multiple regulators, which is illustrated below. Especially for the guide policy regulator, it gradually decreases the execution steps of the guide policy during training, allowing the learned policy to take over eventually, and this is the core innovation of this work.
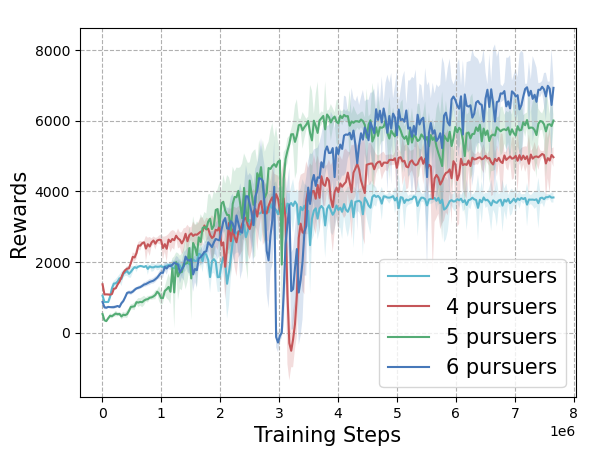
The training reward and environmental settings are illustrated below:

For more details, please refer to our paper.