Guide Policy Assisted Reinforcement Learning for Multi-agent Tasks under Restricted Communication
Abstract
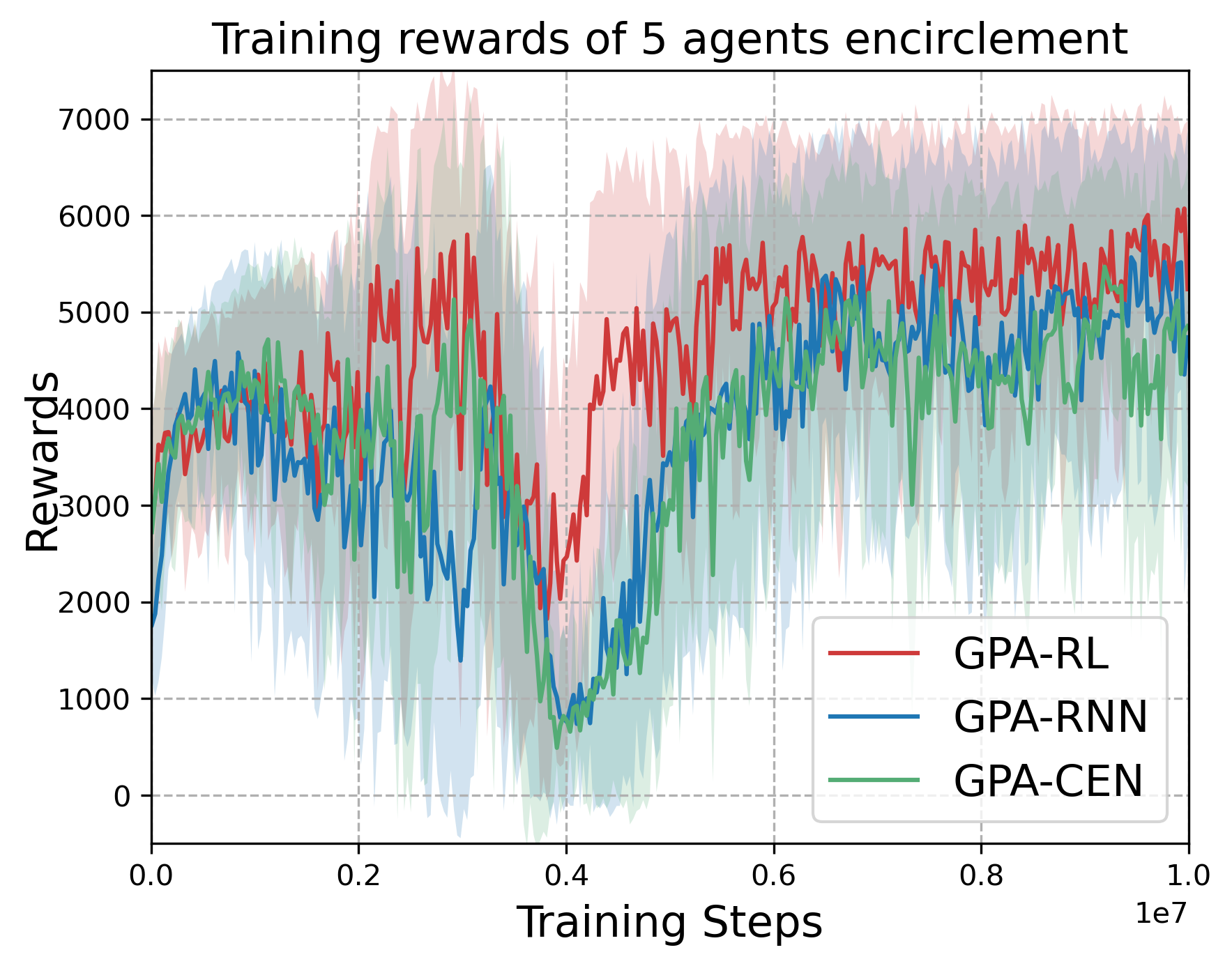
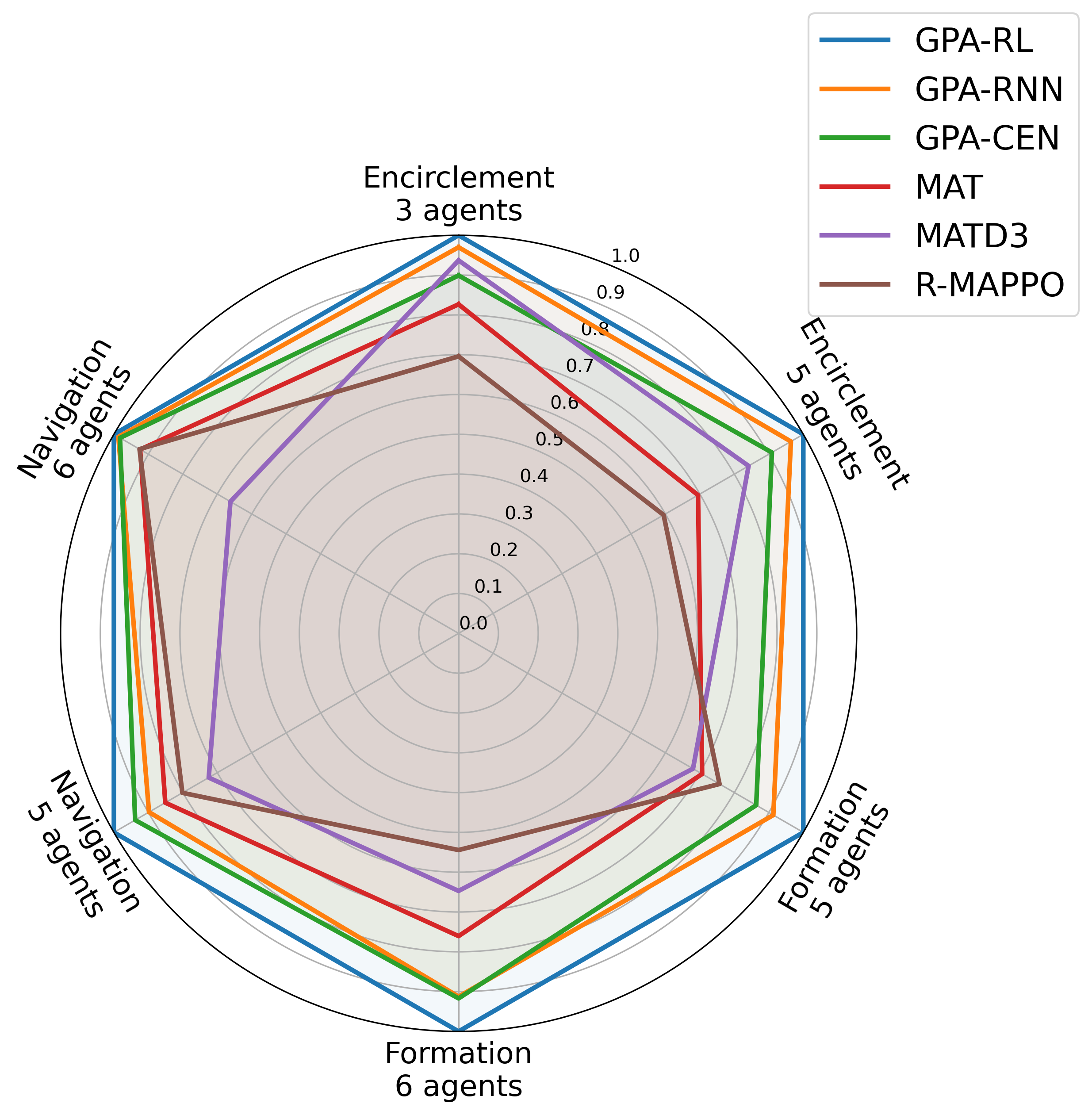
The restricted communication and environmental complexity are major challenges in multi-agent reinforcement learning (MARL), as they limit agent cooperation and result in low sample efficiency. To address these issues, we propose a novel, generalizable paradigm that combines model-based methods with deep reinforcement learning (DRL), named Guide Policy Assisted Reinforcement Learning (GPA-RL). In GPARL, a Transformer-based graph attention network (GAT) is designed to aggregate local information, which enhances the agent interactions and improves the representation of dynamic environments. Besides, the key innovation of GPA-RL lies in the use of a gradually withdrawn guide policy, which significantly reduces the exploration space for cooperative behaviors and improves sample efficiency. To further facilitate training, multiple curriculum learning regulators are devised to manage the retreat of guide policy and control the task difficulty from simple to hard. Additionally, to validate the effectiveness and robustness of GPA-RL, extensive experiments are conducted across three typical multi-agent tasks in complex environments: encirclement control, formation control, and navigation control, with each task involving both static and dynamic obstacles. The experimental results demonstrate that GPA-RL not only outperforms comparative methods but also adapts well to various training frameworks and different guide policies.
Index Terms—Multi-agent reinforcement learning, graph attention network, curriculum learning, guide policy, multi-agent control.
Contributions
-
We design a Transformer-based GAT to aggregate the information for agents under restricted communication, and provide representation for various entities in the task environment.
-
A guide policy is incorporated to assist training, and multiple curriculum learning regulators are devised to adjust the training procedure, which facilitates the convergence and improved sample efficiency.
-
Extensive experiments are conducted across three distinct tasks to demonstrate the effectiveness and superiority of our method. Besides, the transferability of GPARL to various frameworks and guide policies further underscores its robustness.
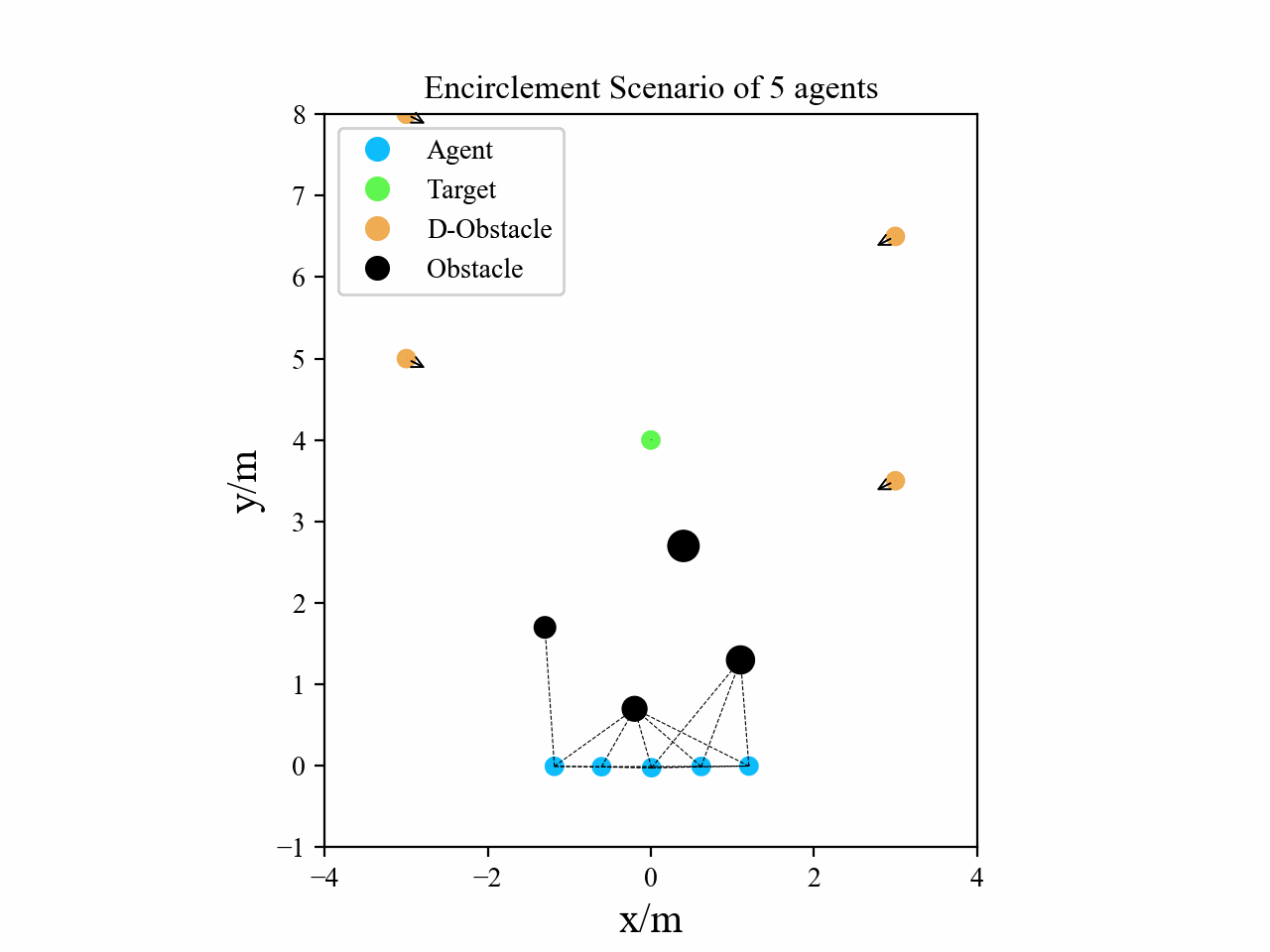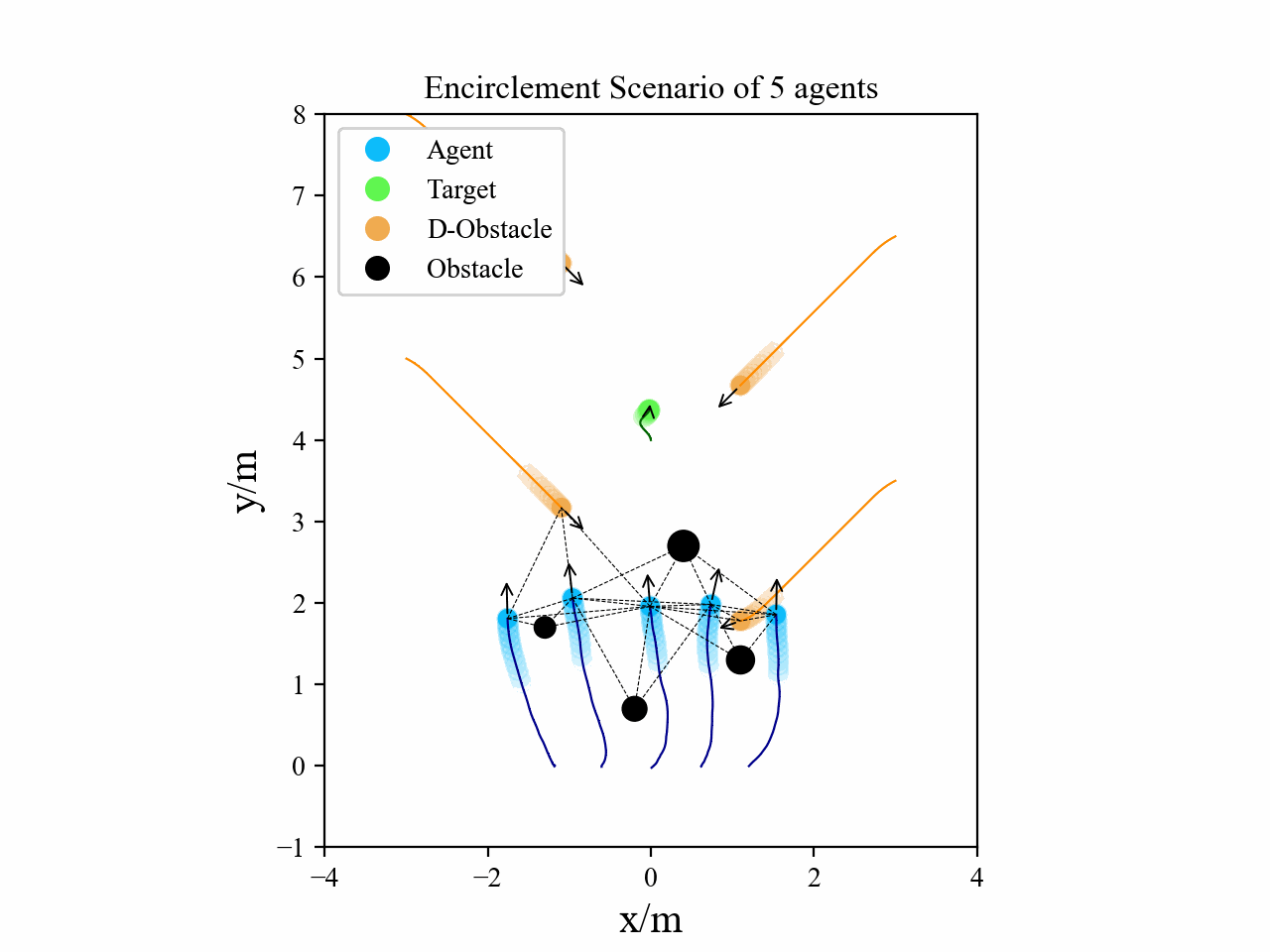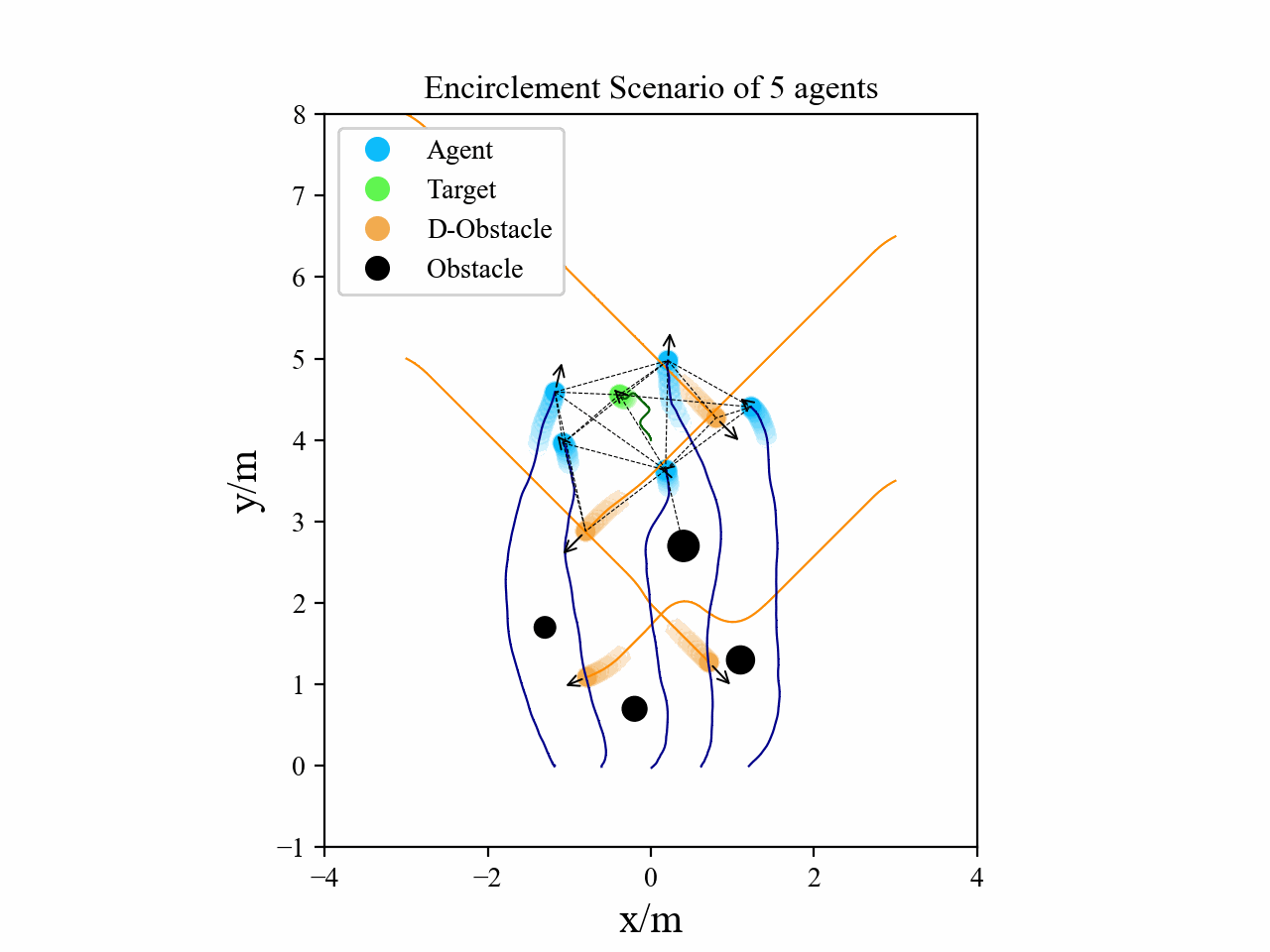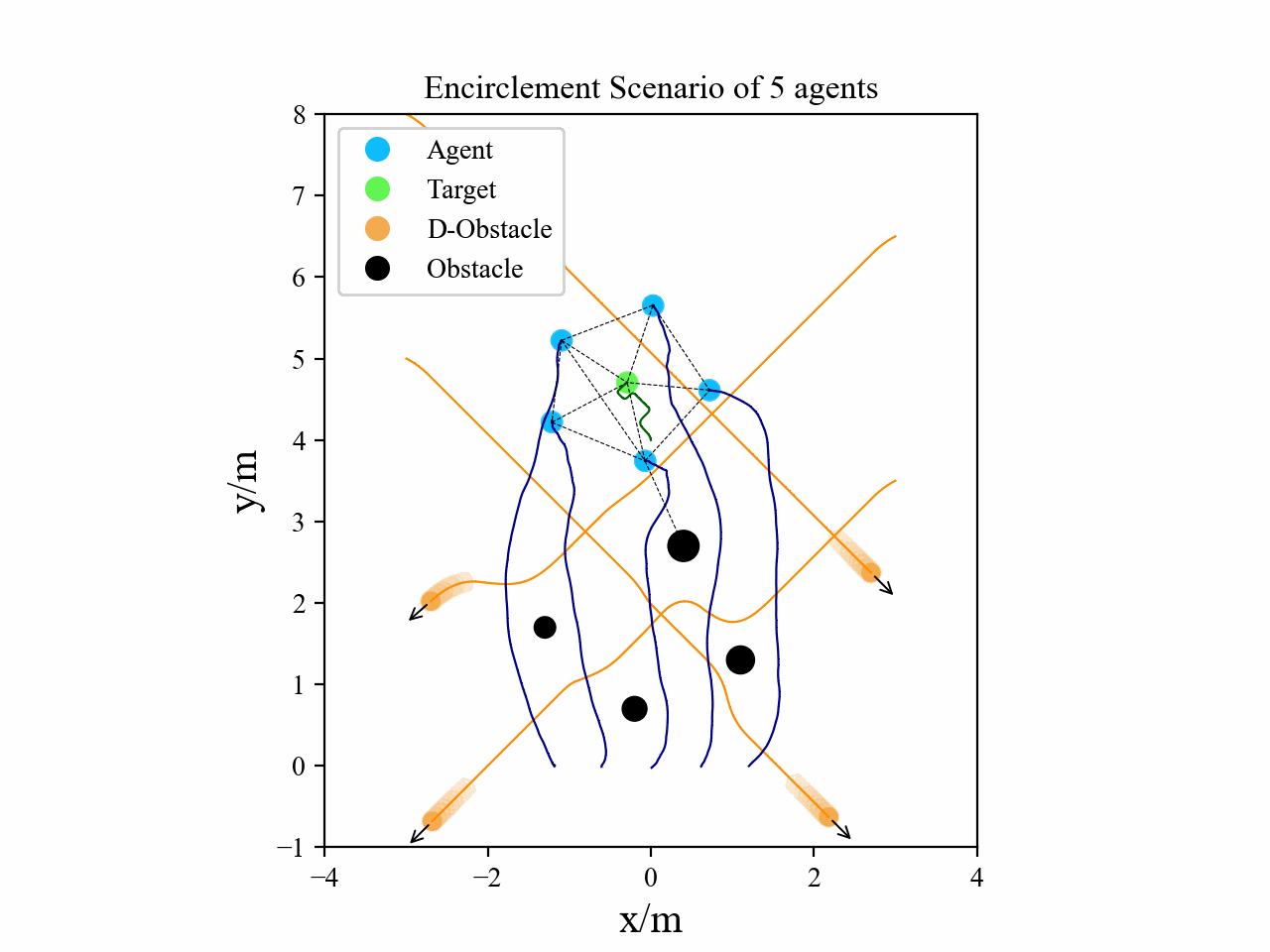
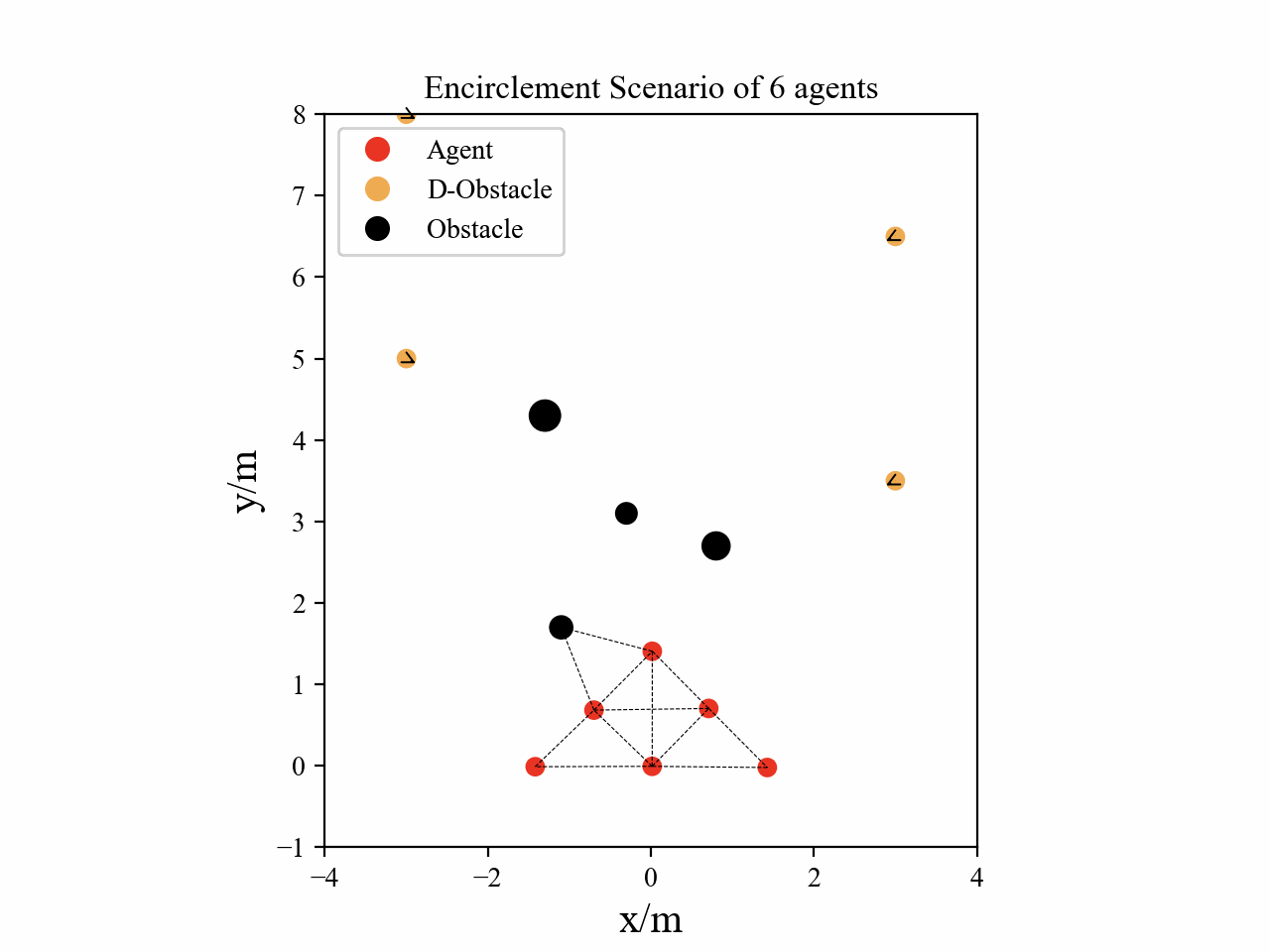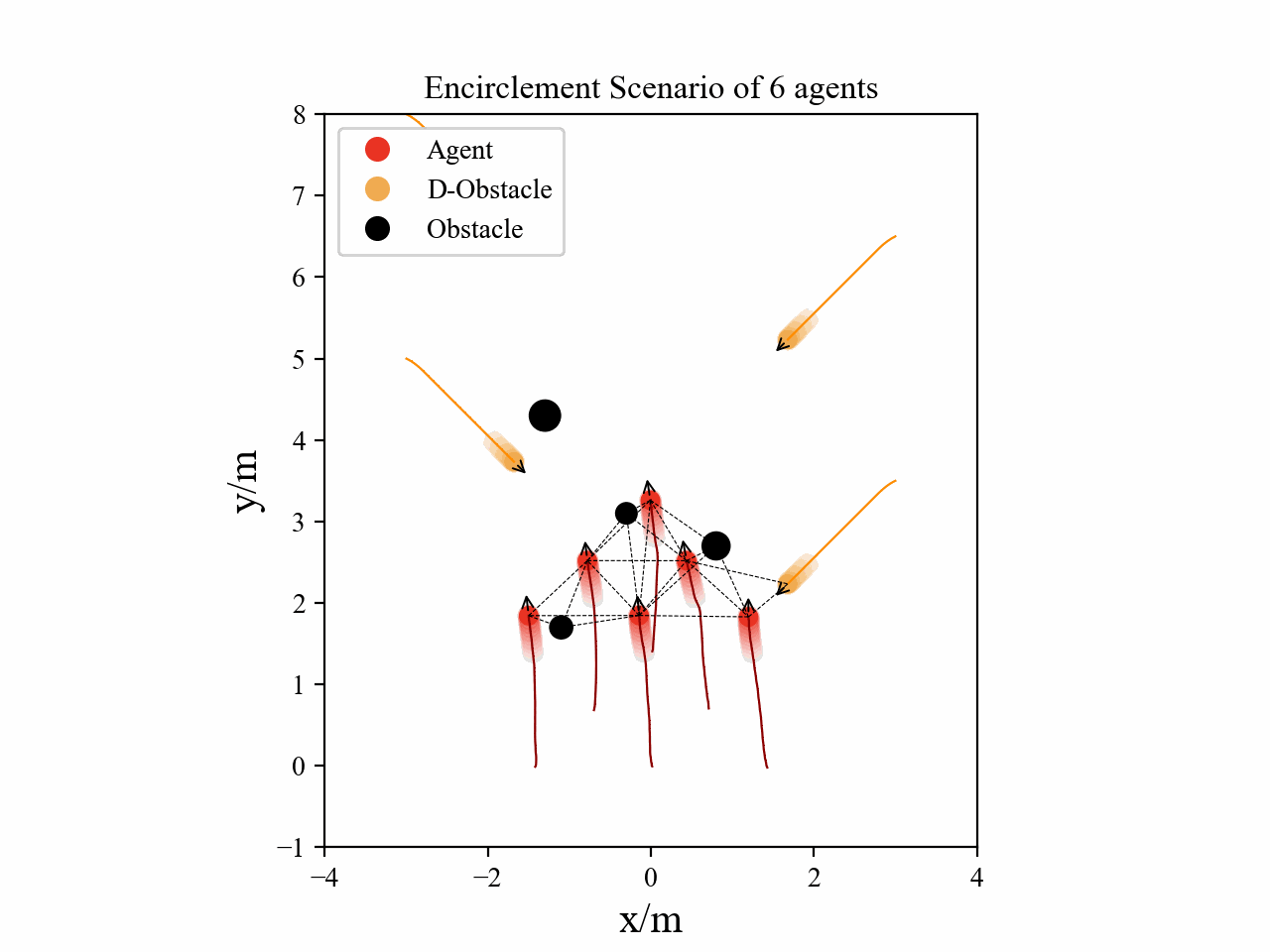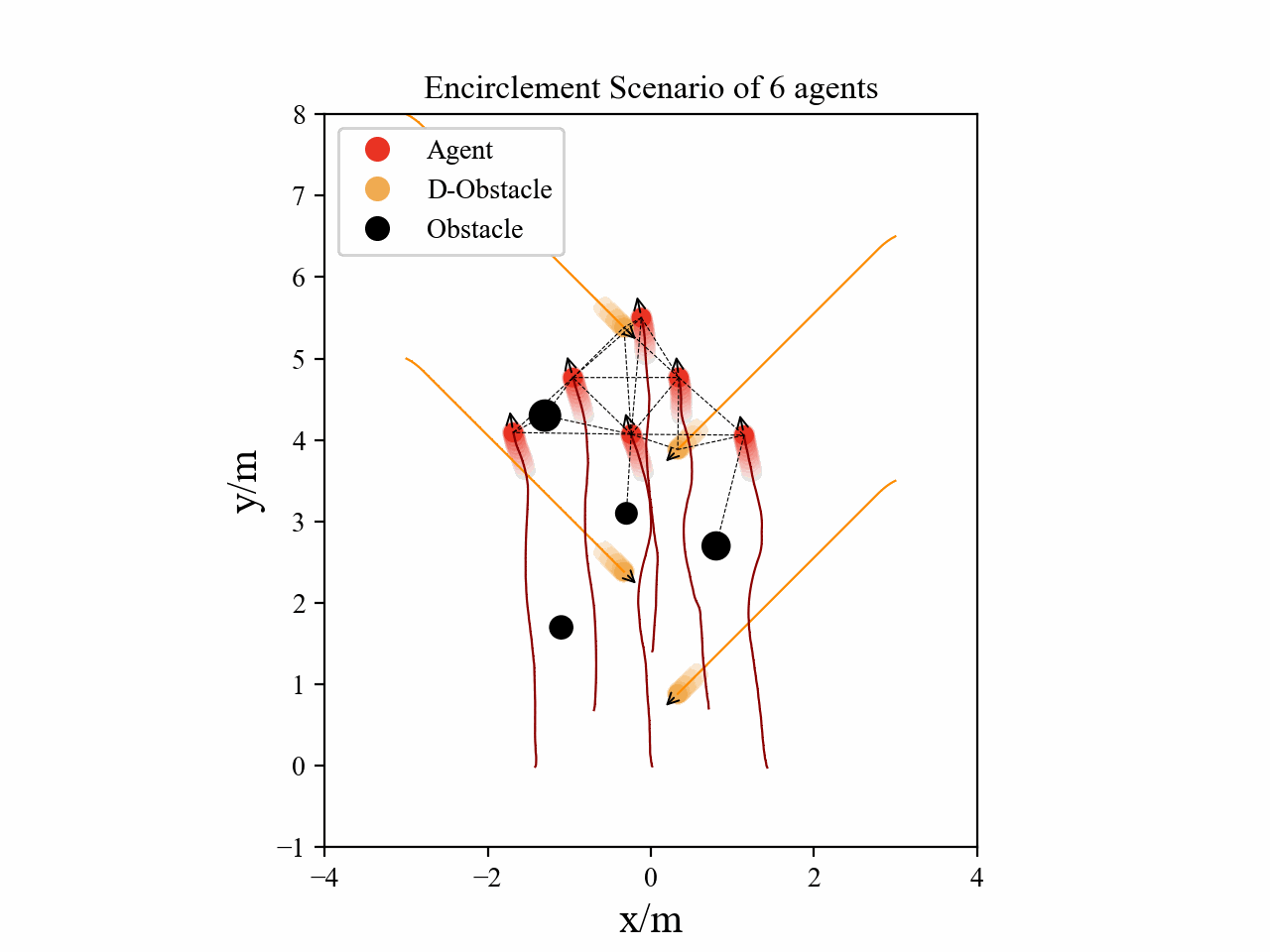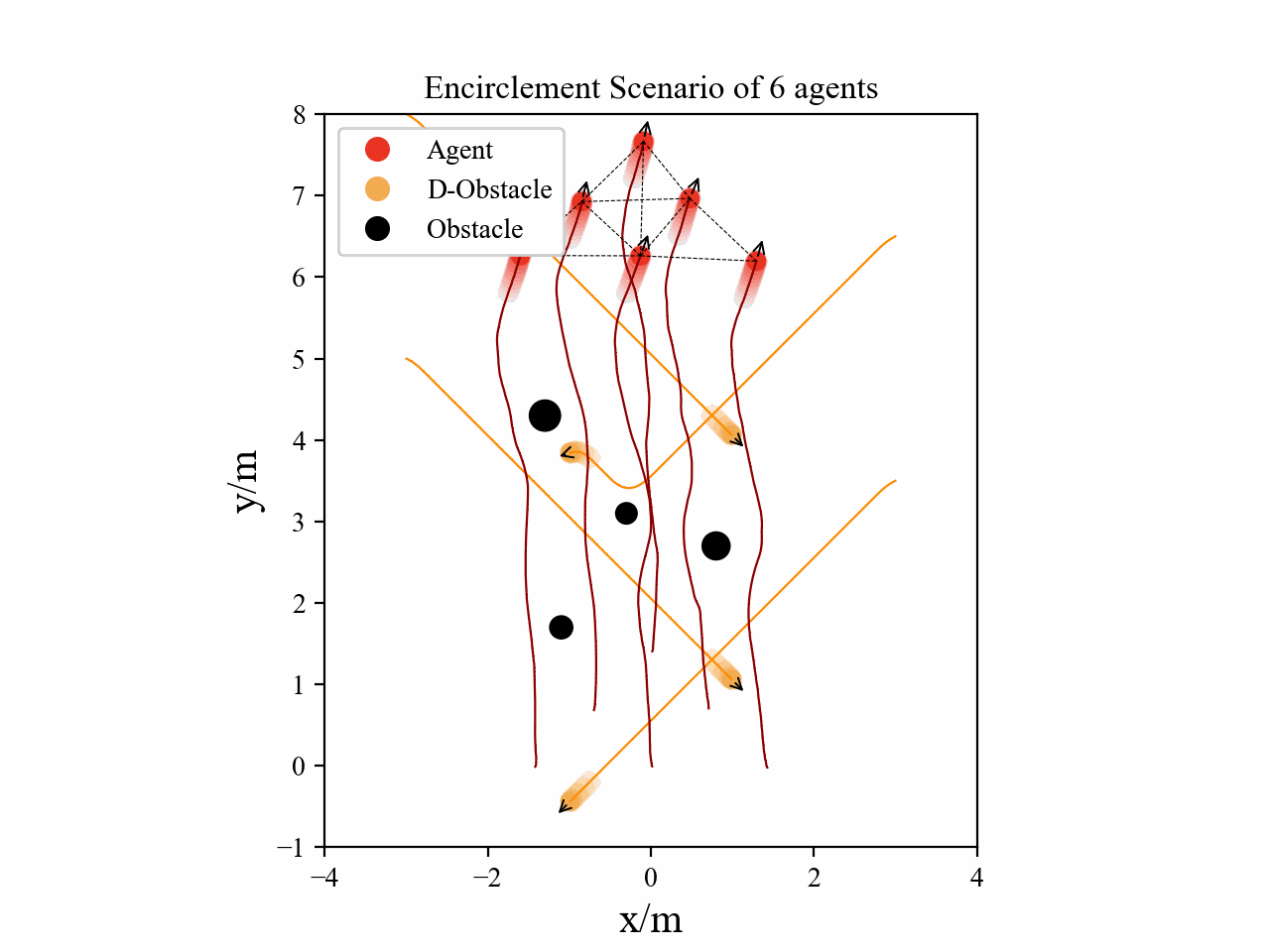
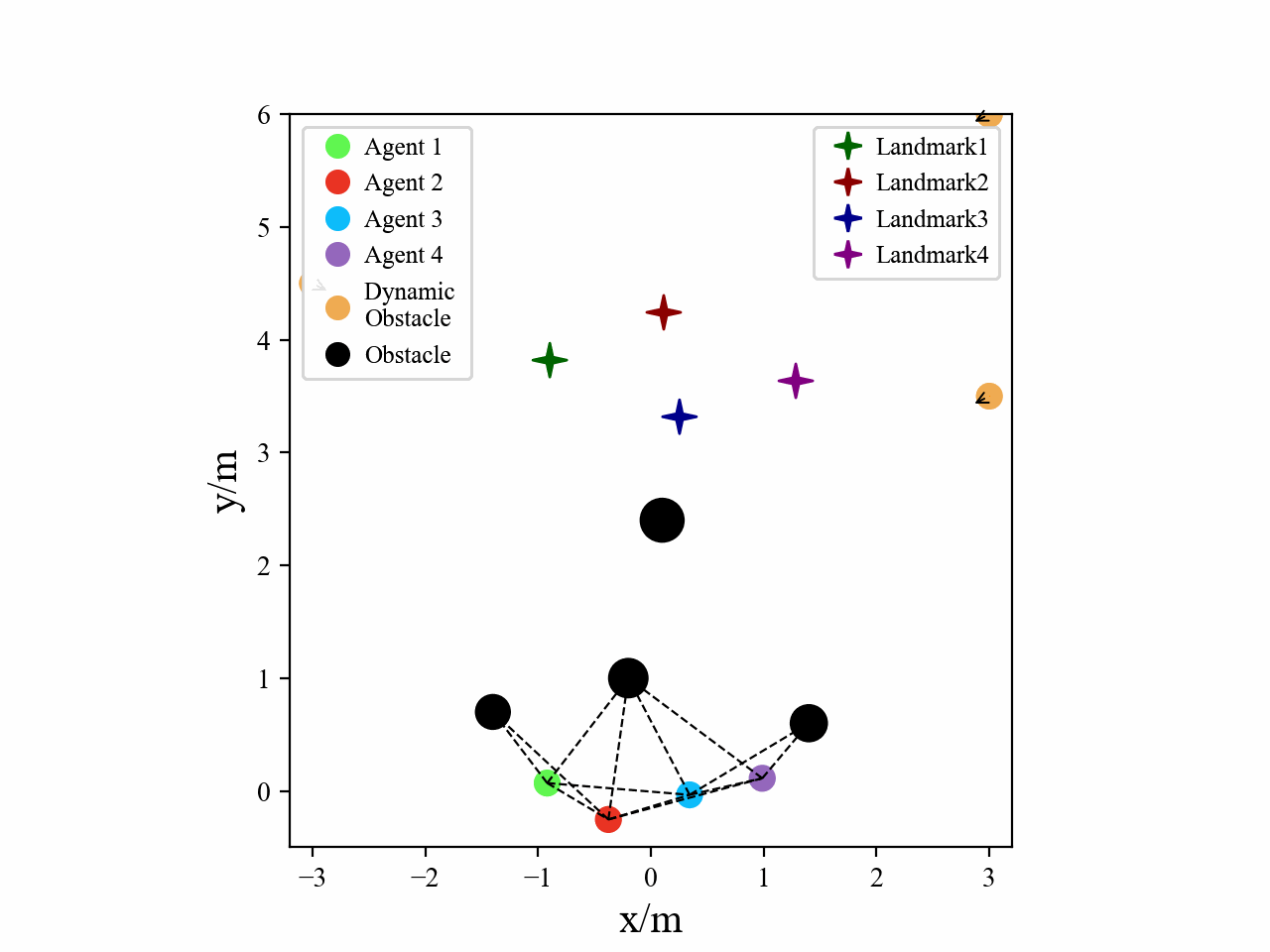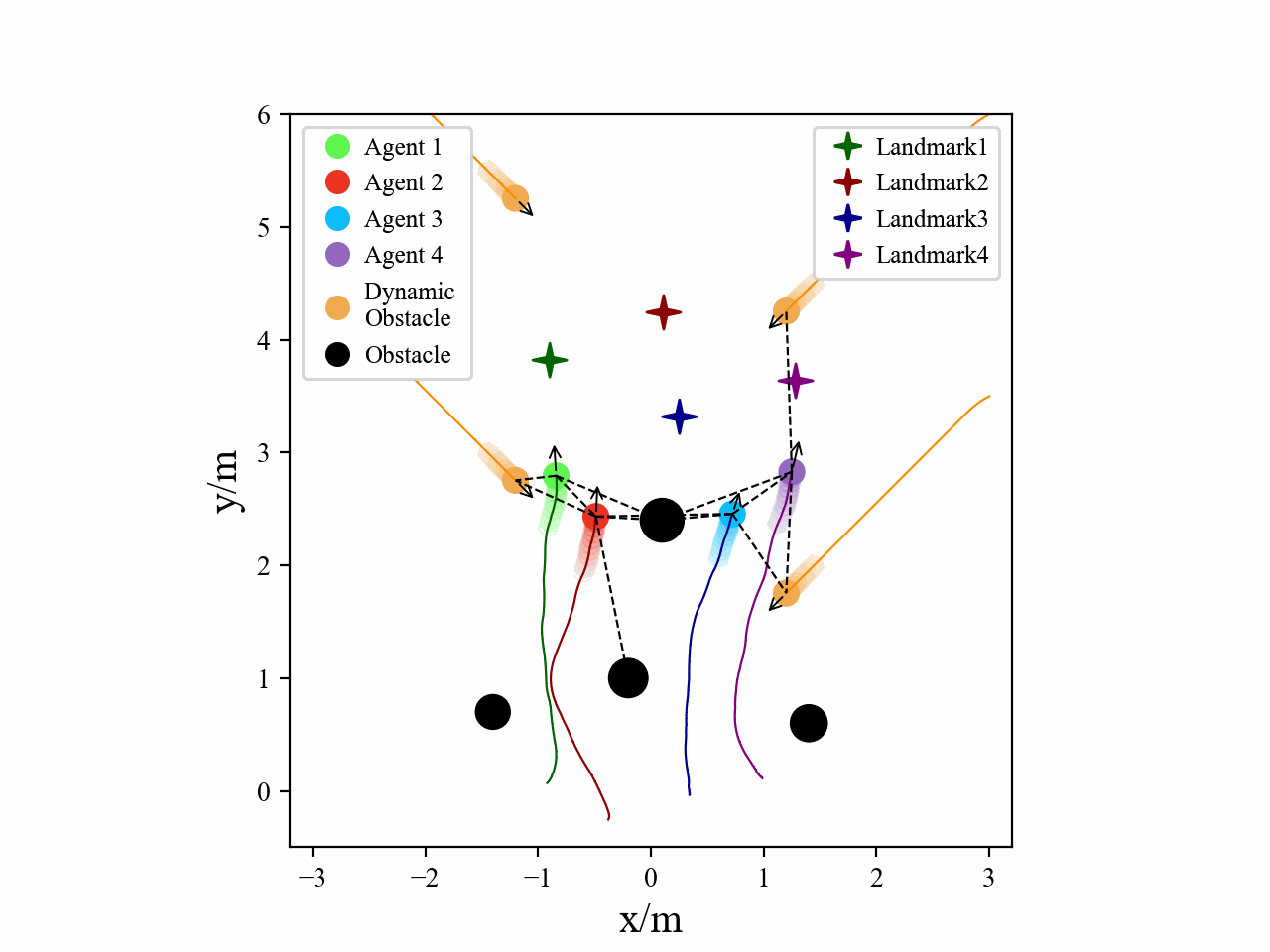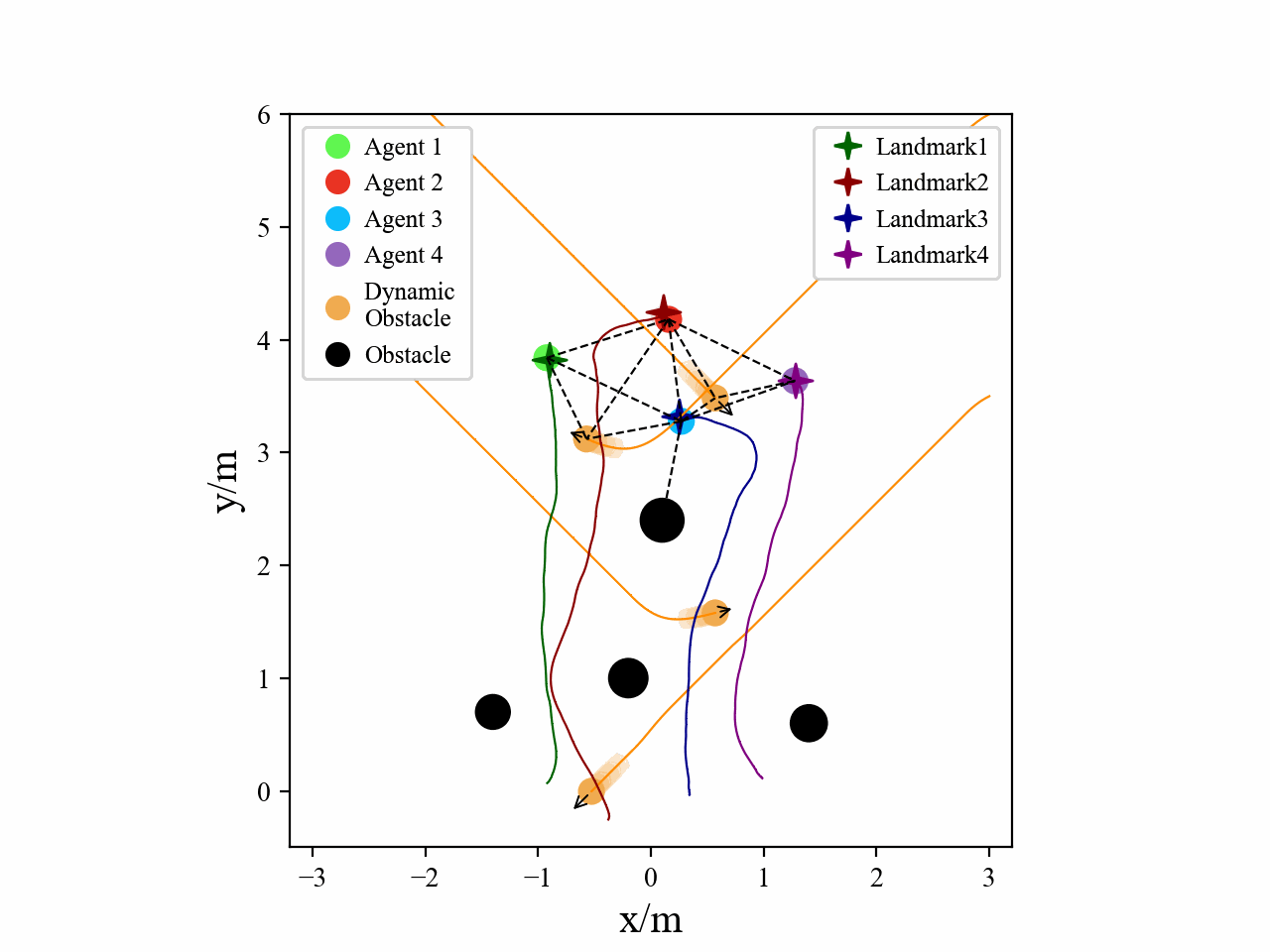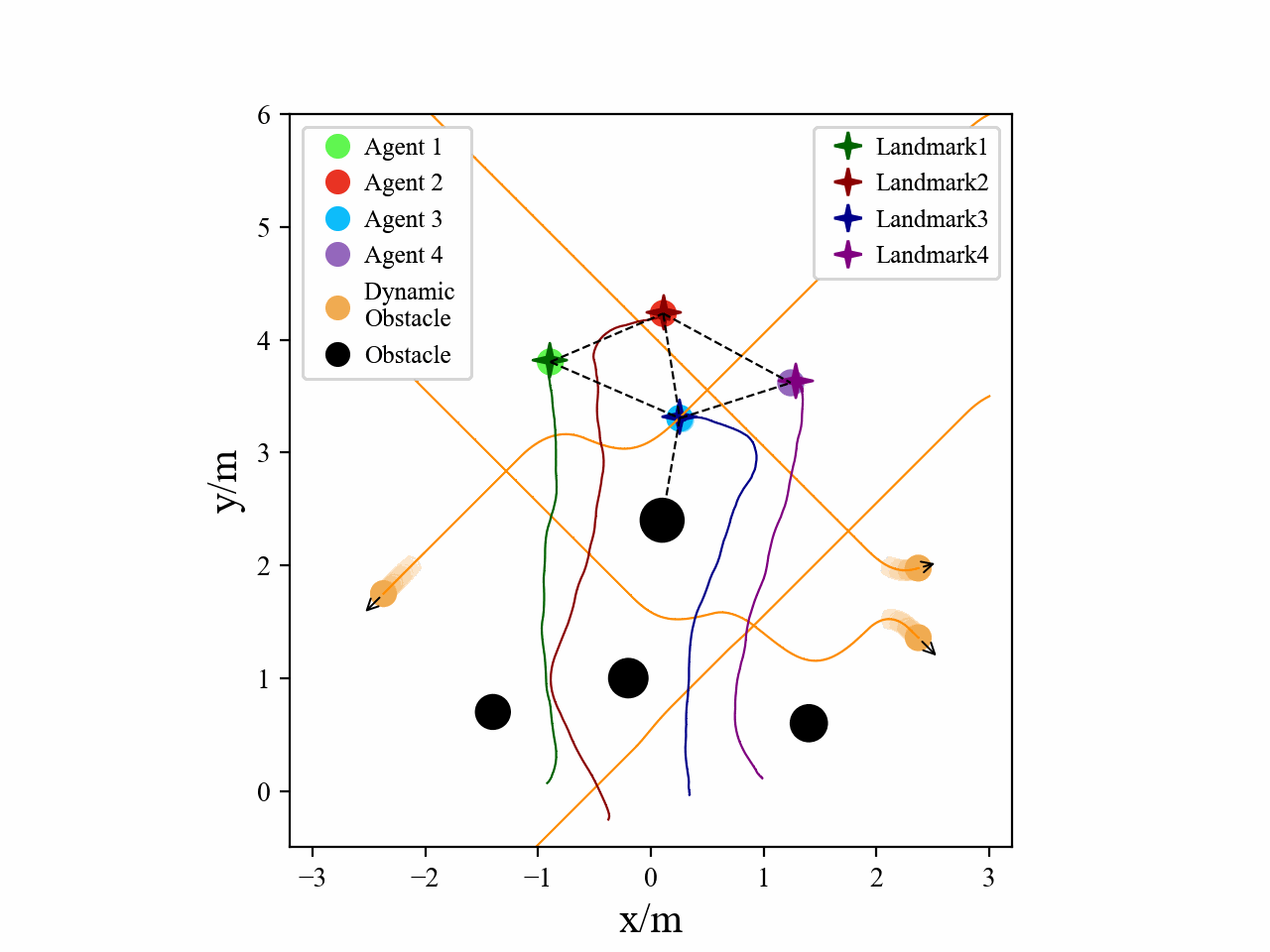
Visualization
Here we provide some visualization of three multi-agent tasks in our experiments using the proposed GPA-RL framework.
The following GIFs illustrate the encirclement, formation and navigation process of multiple agents trained using our proposed GPA-RL method in environments with multiple static and dynamic obstacles.