A Graph-Based Safe Reinforcement Learning Method for Multi-agent Cooperation
Abstract
Safety and Restricted Communication are two critical challenges faced by practical Multi-Agent Systems (MAS). However, most Multi-Agent Reinforcement Learning (MARL) algorithms that rely solely on reward shaping are ineffective in ensuring safety, and their applicability is rather limited due to the fully connected communication. To address these issues, we propose a novel framework, Graph-based Safe MARL (GS-MARL), to enhance the safety and scalability of MARL methods. Leveraging the inherent graph structure of MAS, we design a Graph Neural Network (GNN) based on message passing to aggregate local observations and communications of varying sizes. Furthermore, we develop a constrained joint policy optimization method in the setting of local observation to improve safety. Simulation experiments demonstrate that GS-MARL achieves a better trade-off between optimality and safety compared to baselines, and it significantly outperforms the latest methods in scenarios with a large number of agents under limited communication. The feasibility of our method is also verified by hardware implementation with Mecanum-wheeled vehicles.
Index Terms—Safe reinforcement learning, Graph neural networks, Constrained policy optimization, Multi-agent cooperation, Collision avoidance.
Contributions
-
We utilize the graph neural networks (GNNs) to achieve implicit communication between agents under partial observable environments, while enhancing sampling efficiency during the training phase of multi-agent tasks.
-
We employ the constrained joint policy optimization to solve safe MARL problem, which can handle multiple constraints to ensure safety during both the training and testing phases.
-
Extensive experiments, including hardware implementation, have been conducted to demonstrate the zero-shot transferring ability and safety level of GS-MARL, and we compared the effectiveness of GS-MARL with other prevailing works.
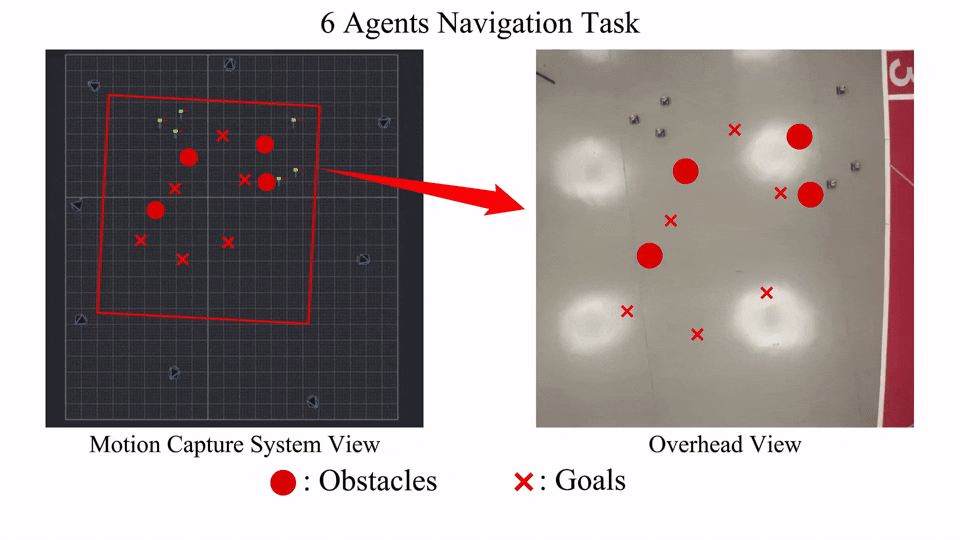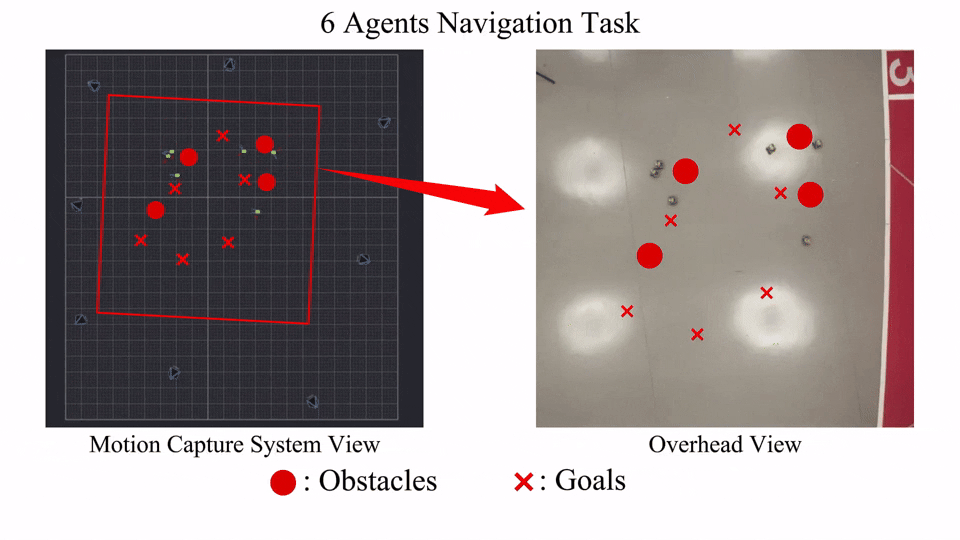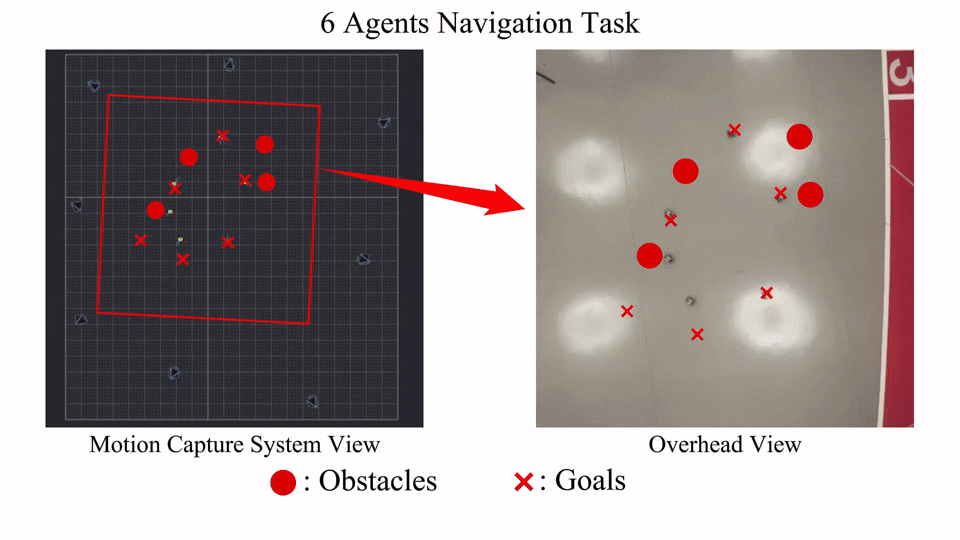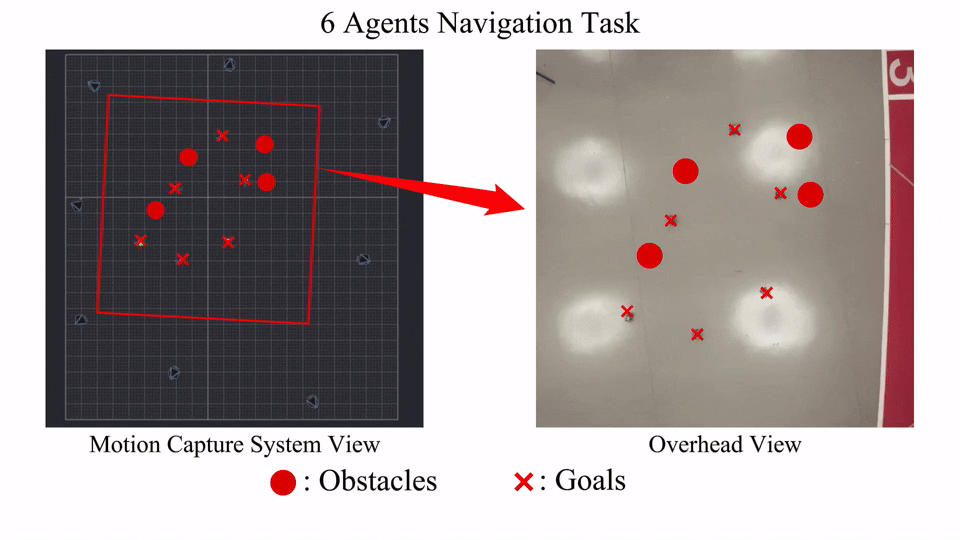
Visualization
Here we provide some visualization of training reward and cost(represented by number of collisions).
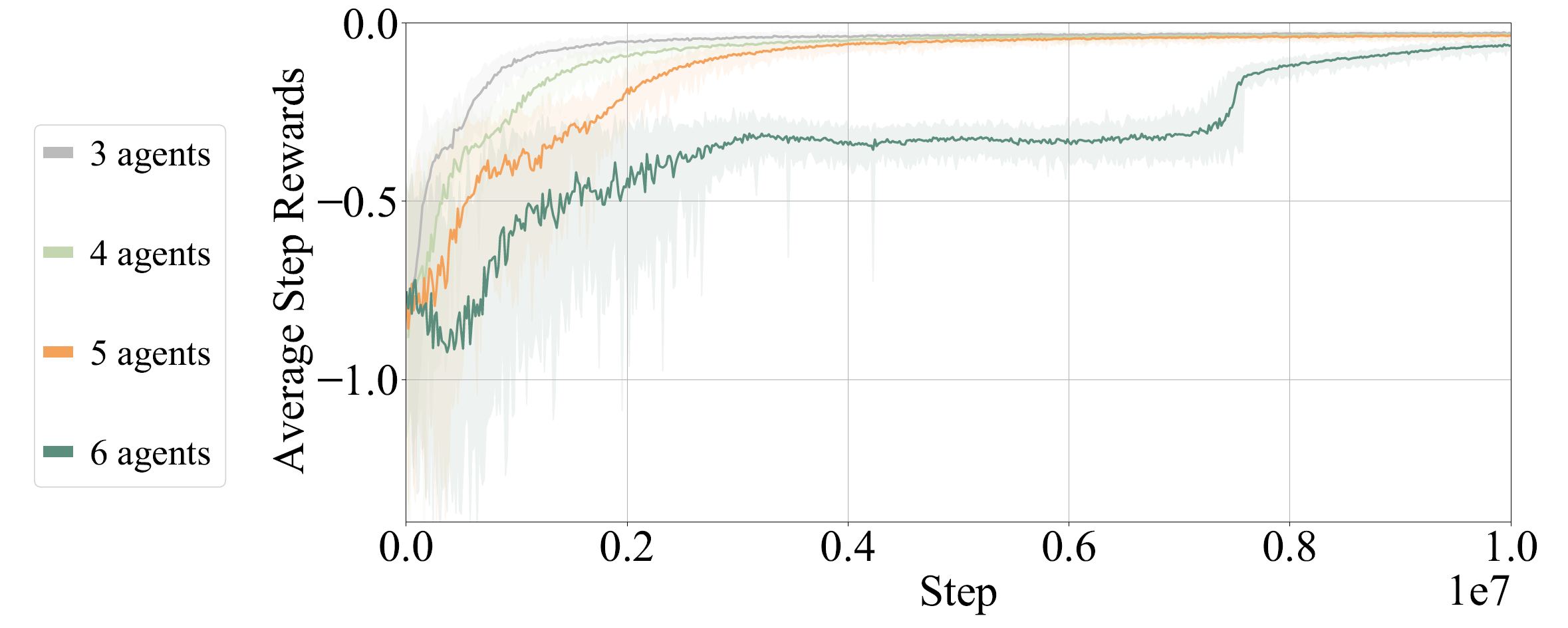
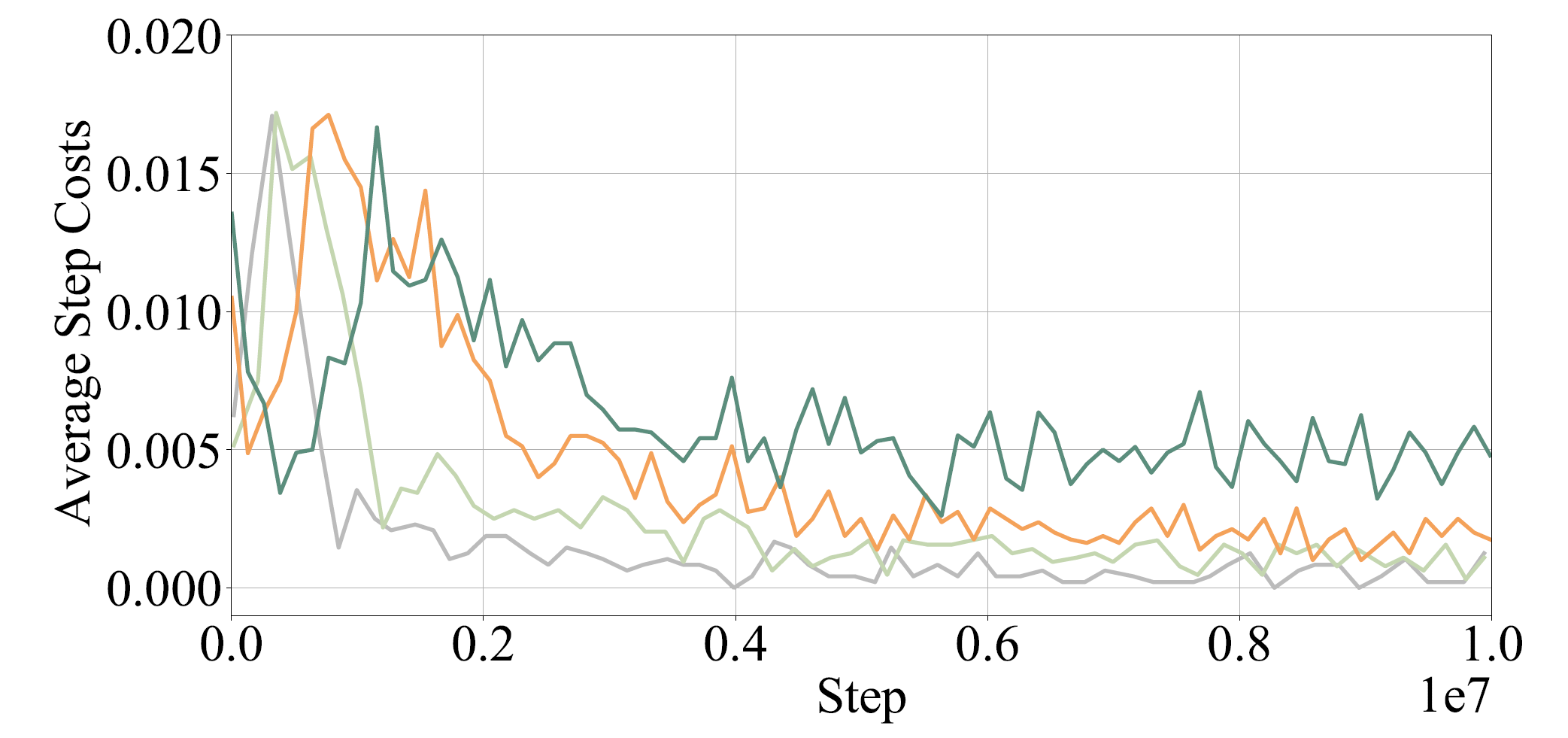
The following GIFs illustrate the navigation process of different numbers of agents. For large agent numbers, we use a zero-shot transfer method to directly apply the trained model with small agent numbers to more agents without further training.