Three-dimensional TAD game using deep reinforcement learning
Background
This is the extended work of our paper in IROS 2025. In this work, we investigate a three-dimensional (3D) TAD game using hierarchical learning methods, with different entity positions, target maneuvers, and defender policies. The attacker policy is trained via DRL. To make the task difficult for attacker, the initial position is advantageous to defender and target.
Methods
-
We designed the action space, state space, and reward function to the scenario. The action space is nonlinearly mapped to yield smoother control transients, while the reward aggregates two competing objectives: hitting target and evading defender.
-
A hierarchical reinforcement-learning paradigm is adopted: the attacker selects between two high-level options—evading the defender or hitting the target. All model parameters are updated via proximal policy optimization (PPO).
Visualization
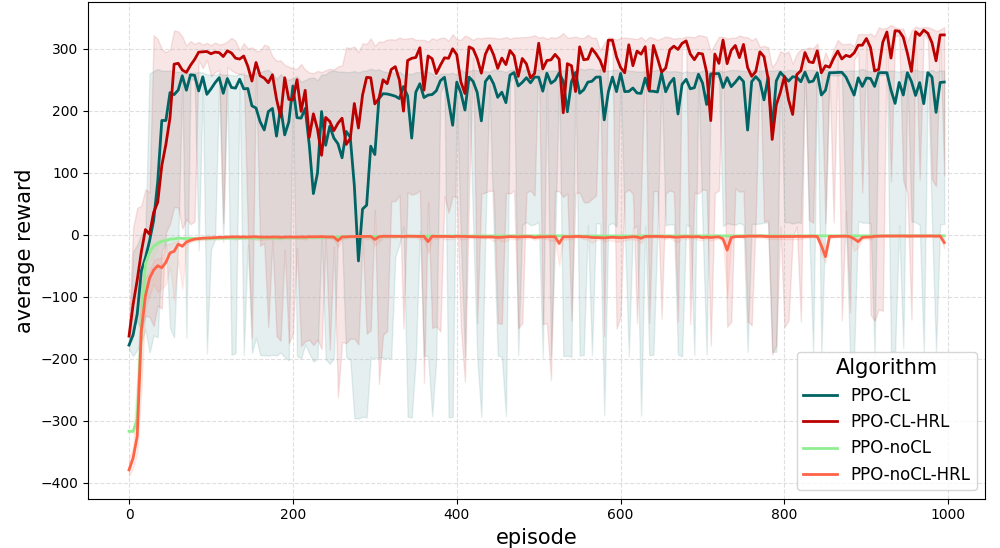
The following figure demonstrate the training reward using different algorithms.
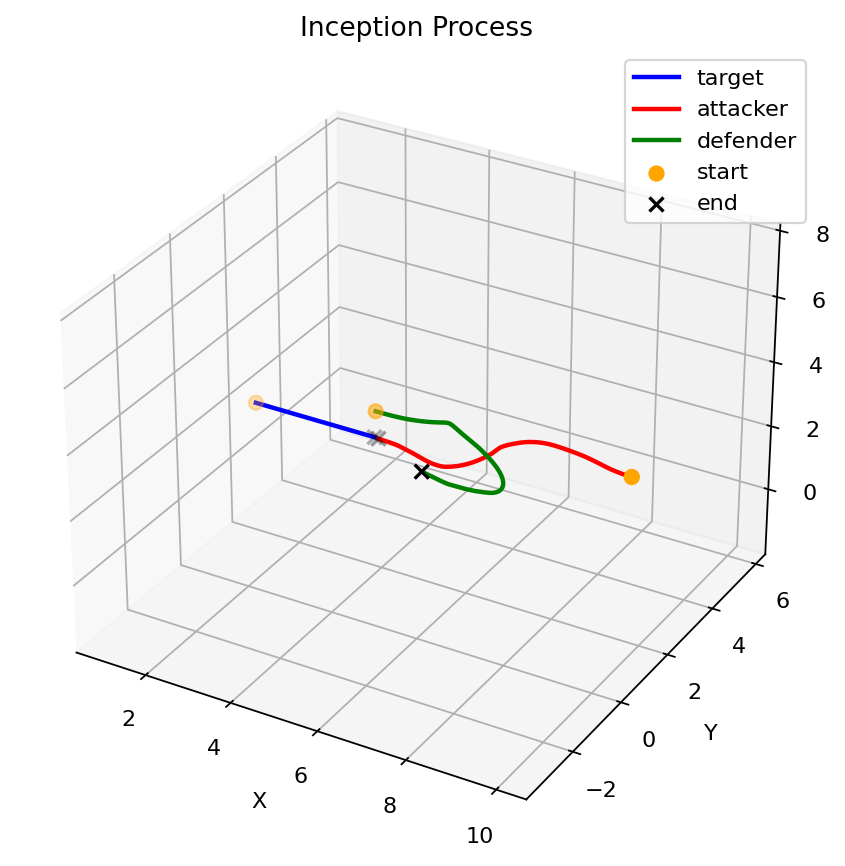
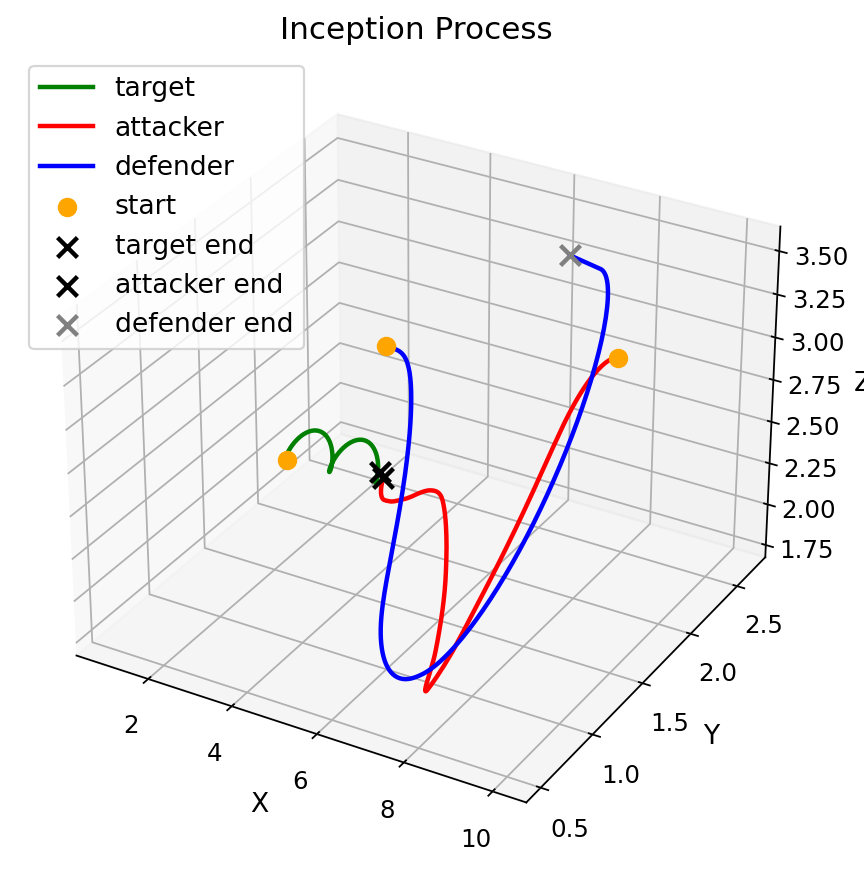
The following figures demonstrate the rendered trajectories for different scenarios.