Coverage based encirclement interception method via deep reinforcement learning
Background
When the target exhibits superior capabilities, a single agent struggles to gain an advantage in one-to-one engagement. Under this premise, deploying multiple weaker agents to cooperatively intercept the target becomes a better strategy. We therefore formulate the interception task as a multi-agent encirclement problem and train the team via multi-agent reinforcement learning, thereby raising the success rate against stronger target.
Methods
-
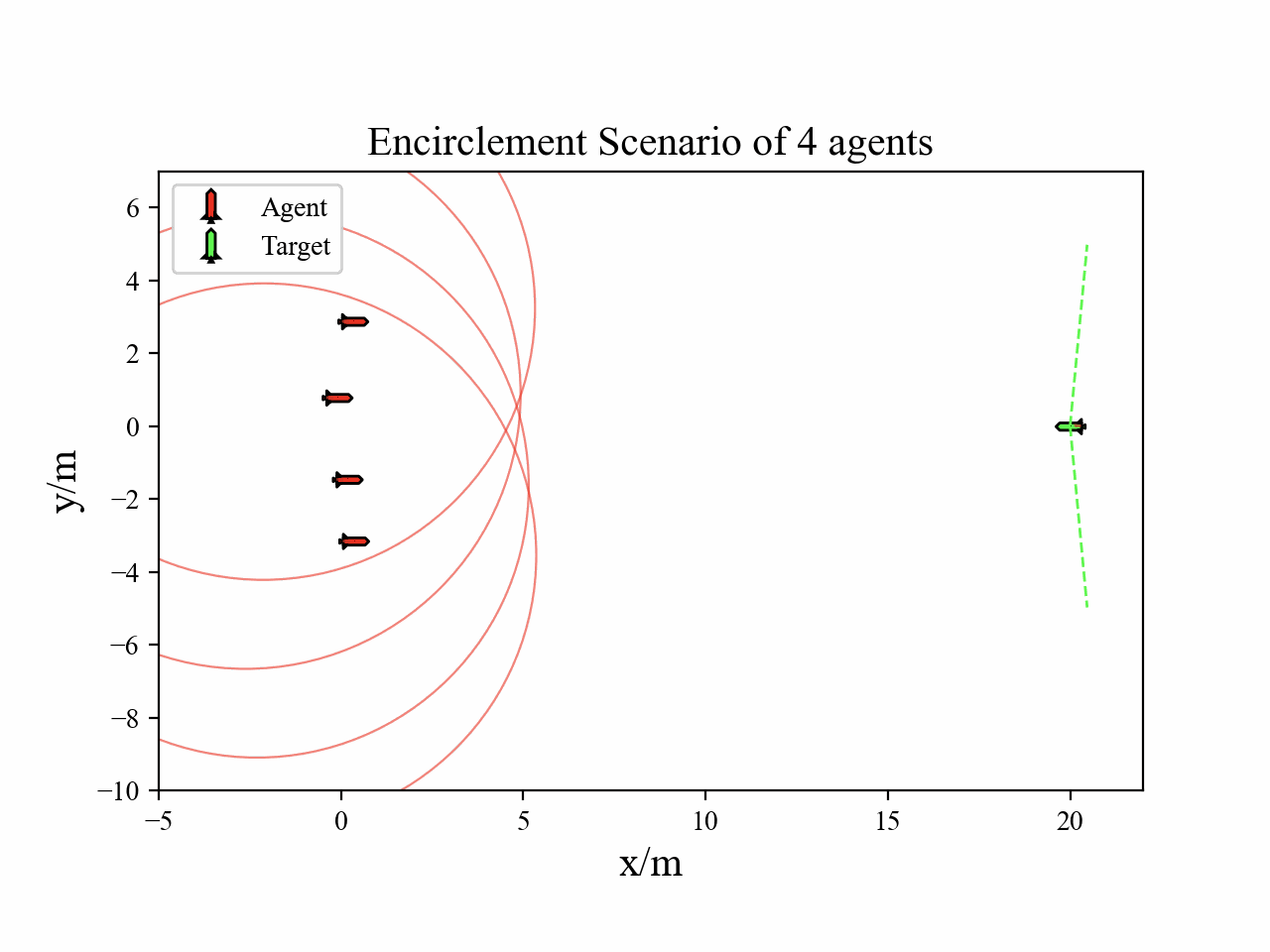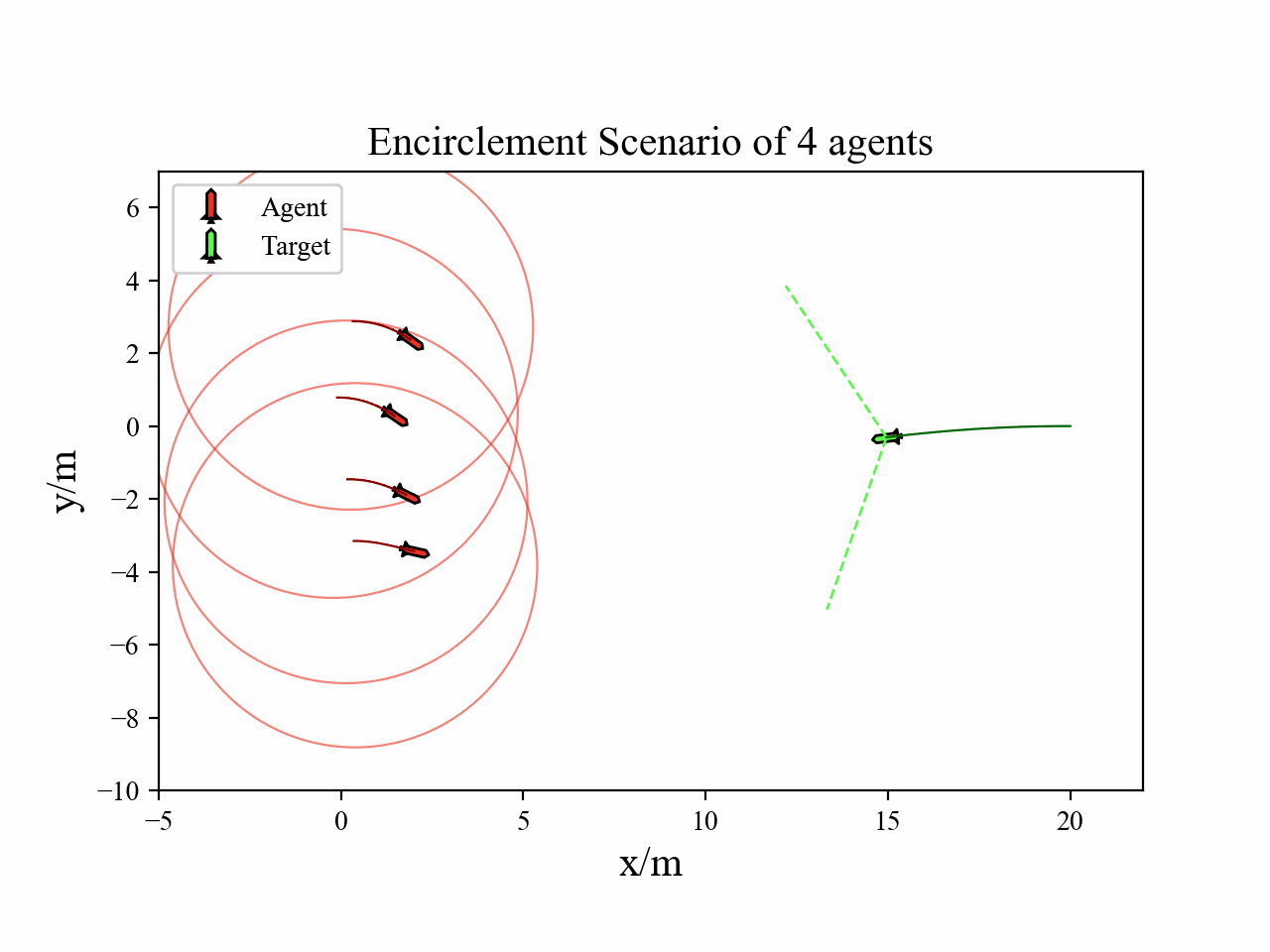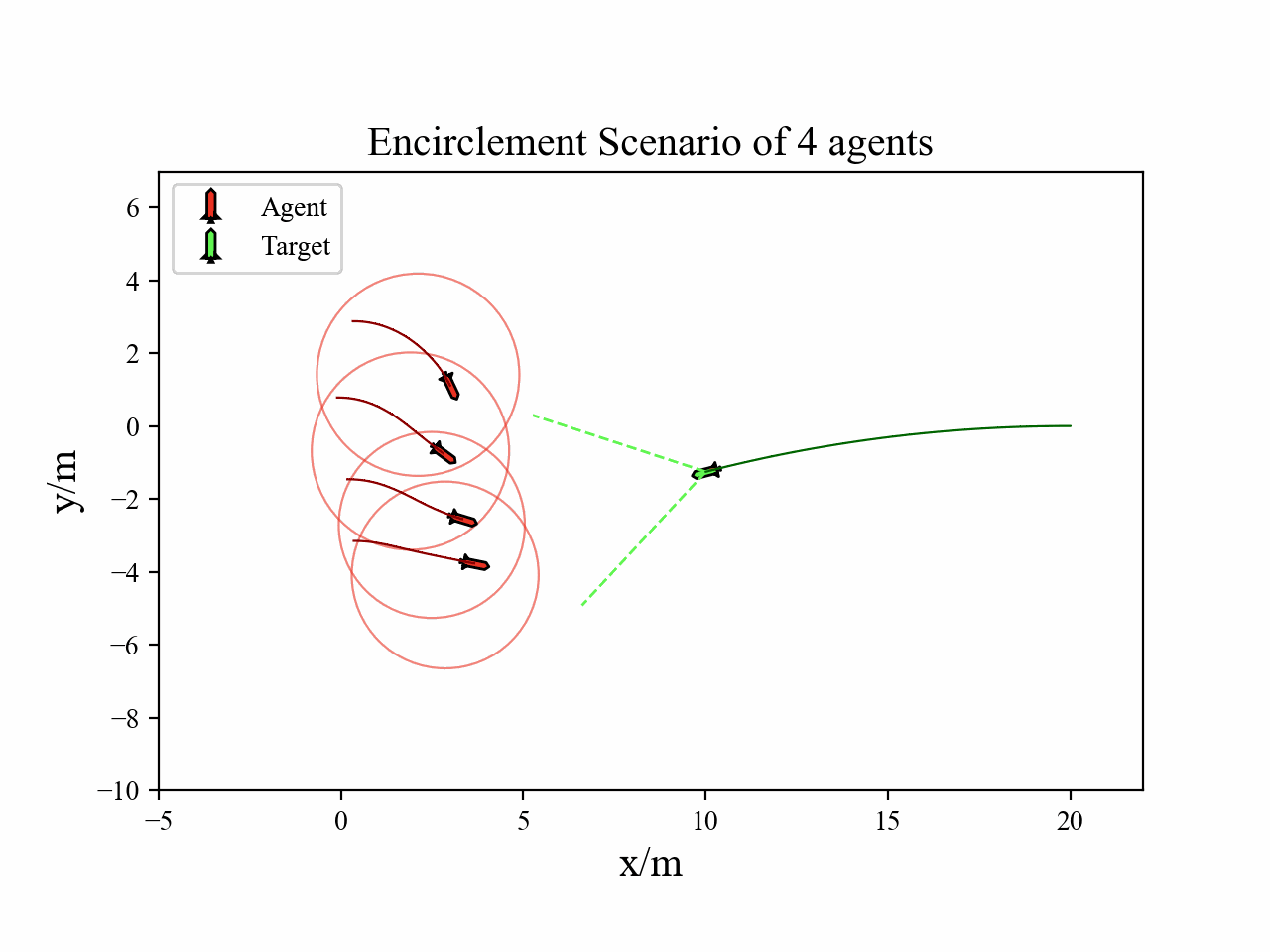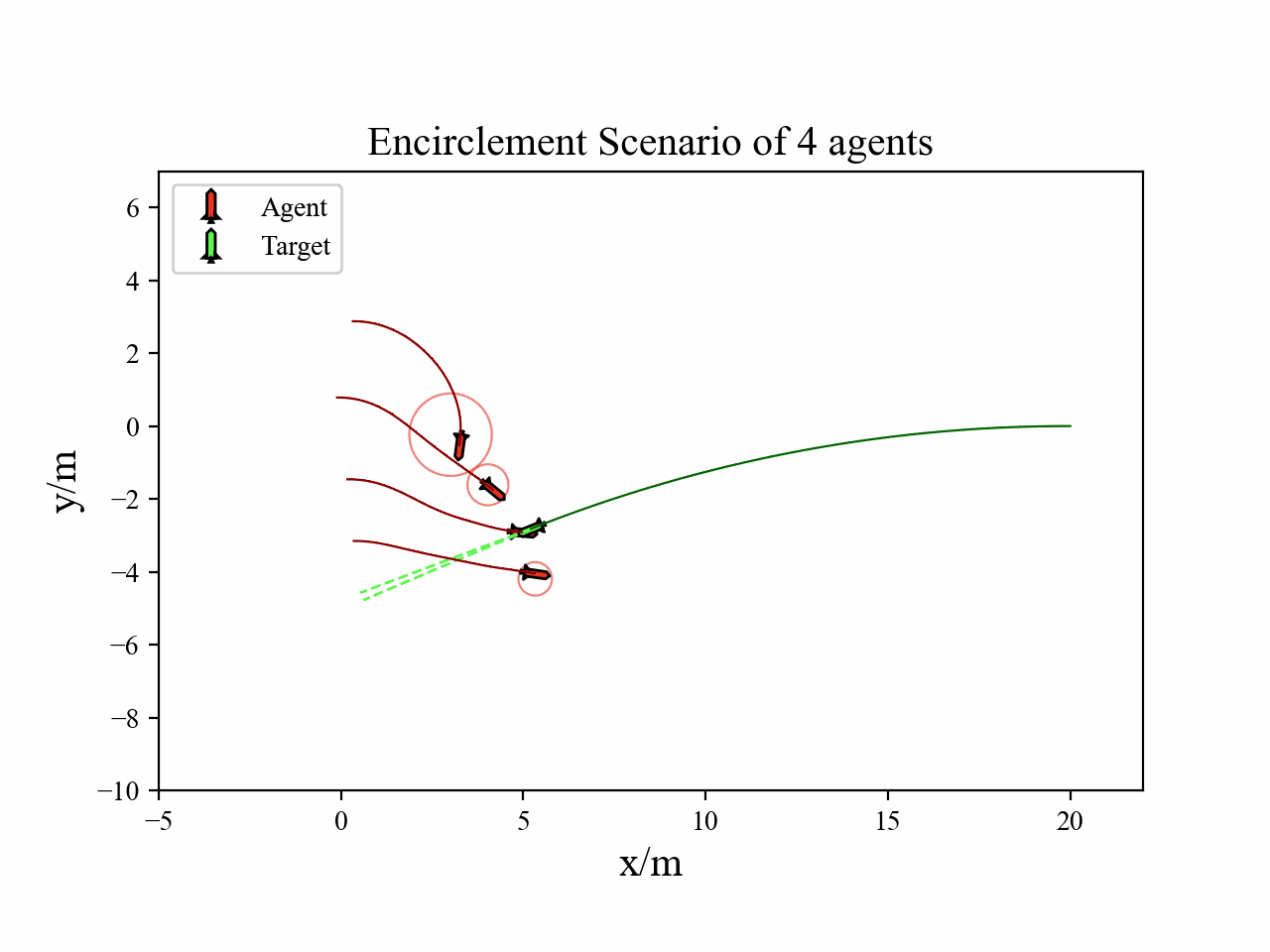
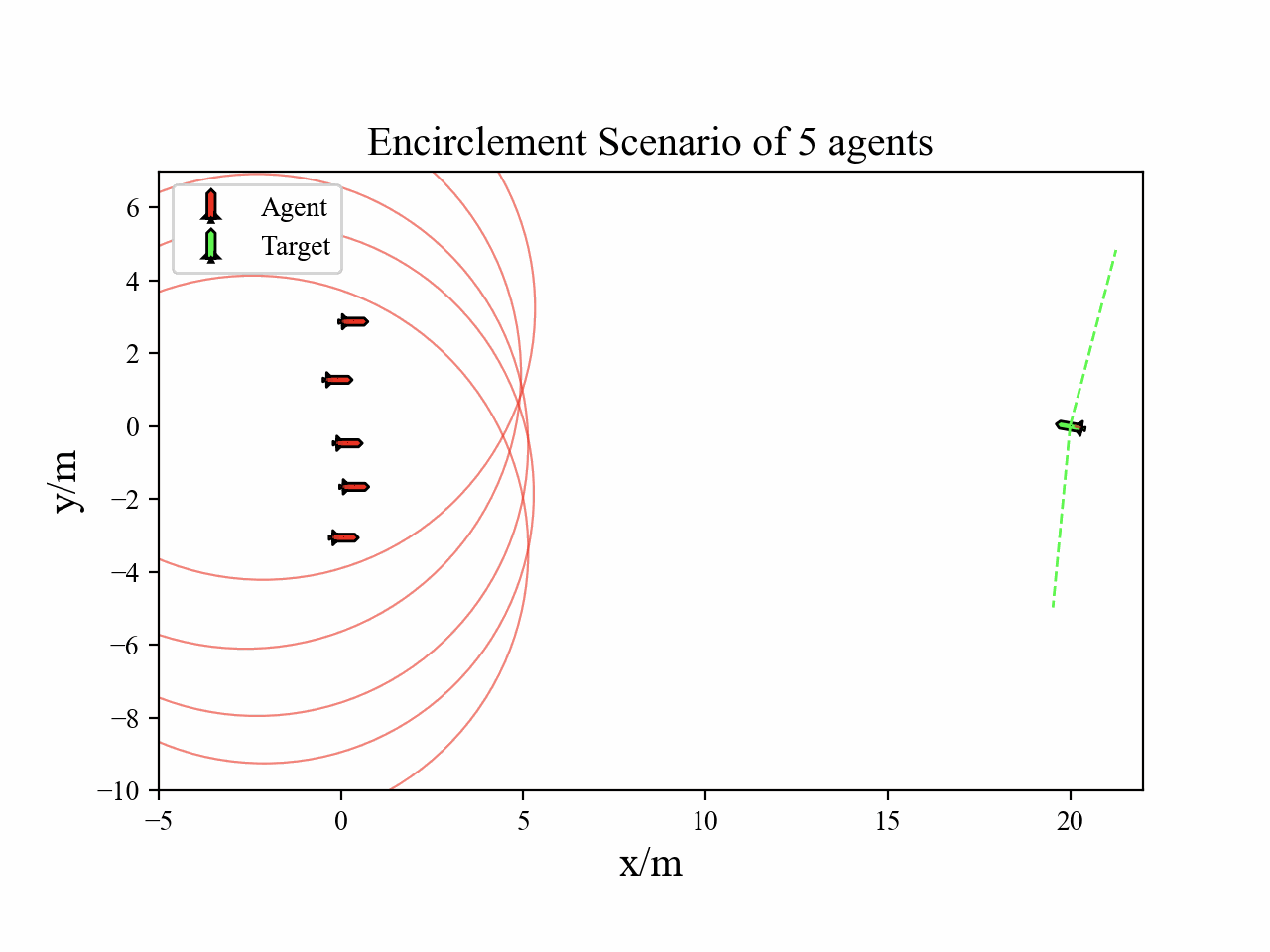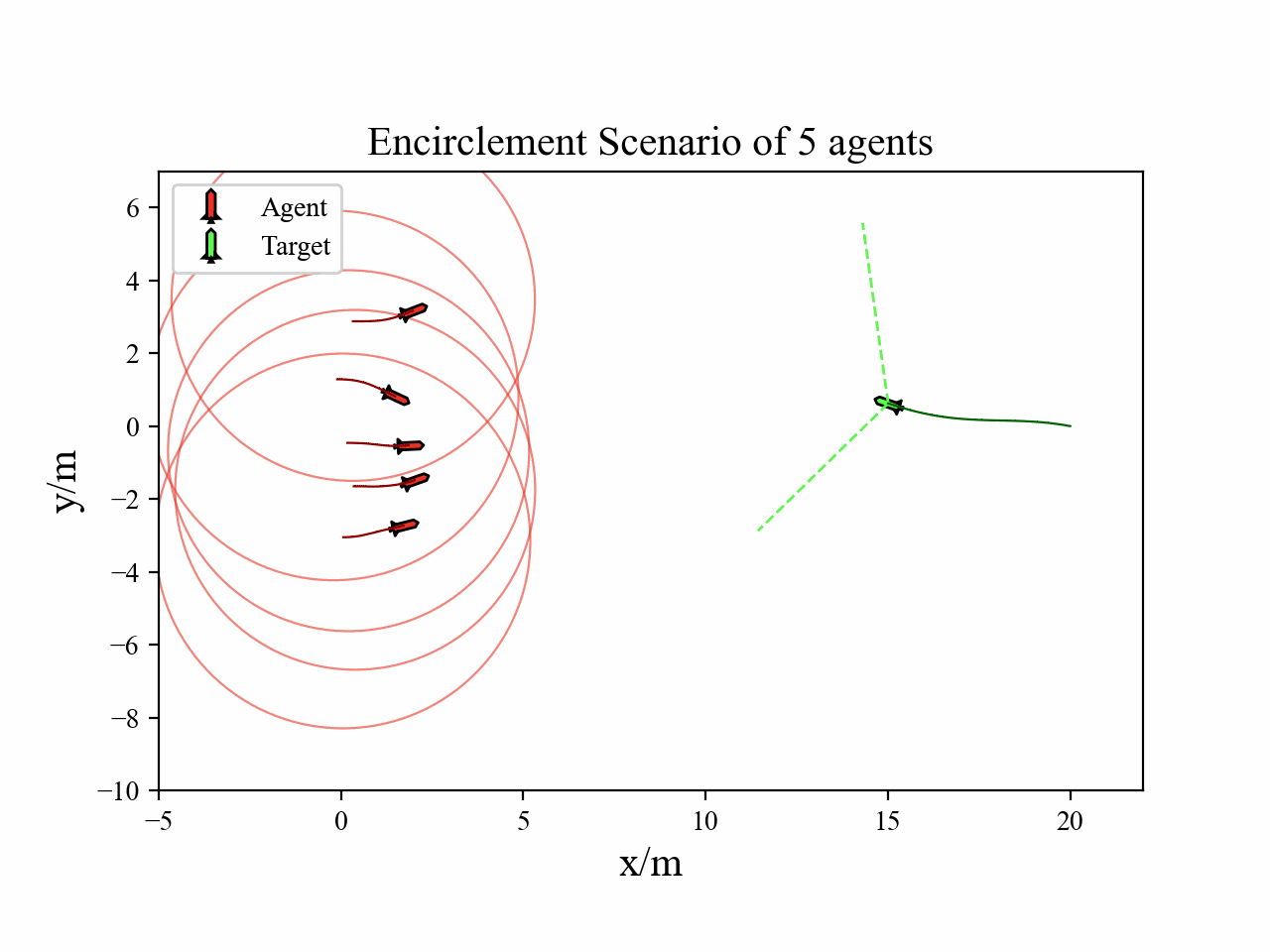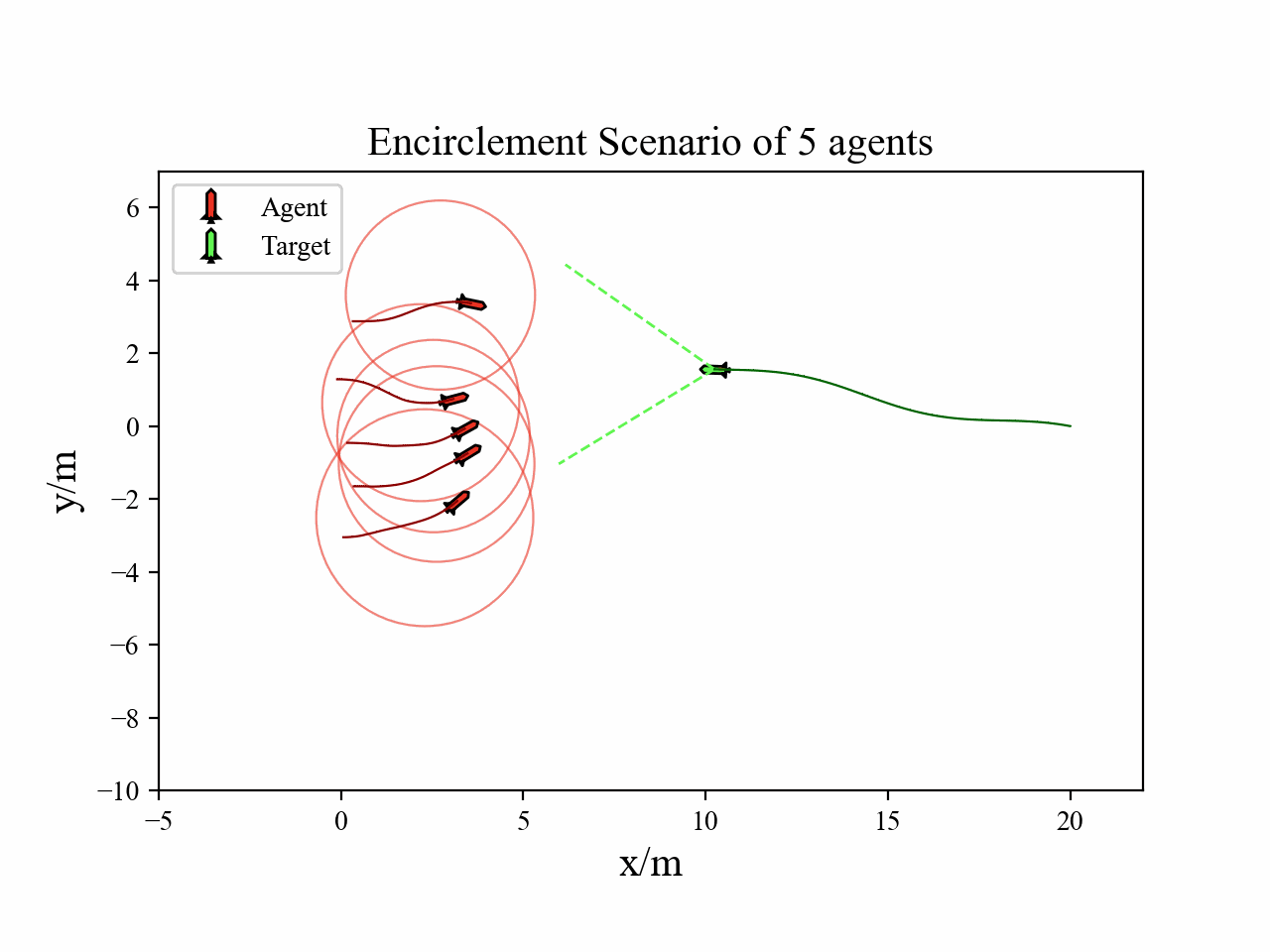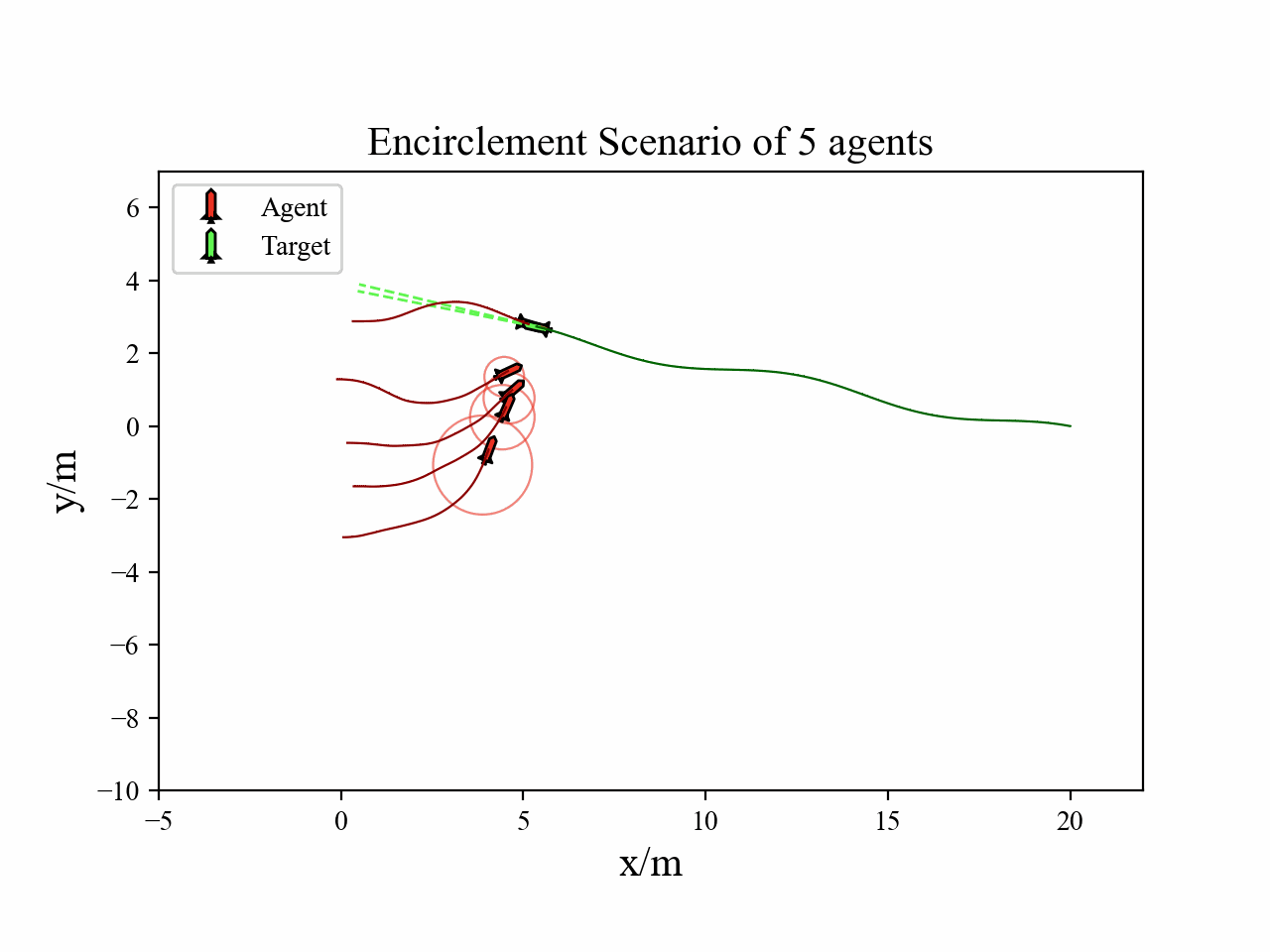
We construct the agent-to-target Apollonius circle and forward-propagate the target’s reachable set over the upcoming horizon.
-
Encirclement positions are then optimized so that the union of Apollonius circles provides high-coverage of this forward reachable region.
-
A multi-agent reinforcement learning framework is designed to learn the cooperative interception policy, where each agent decides its action to maintain encirclement positions and intercept target.
Visualization
The following figure demonstrate the agent-target Apollonius circle.

The following figures demonstrate the training rewards under different scenarios.
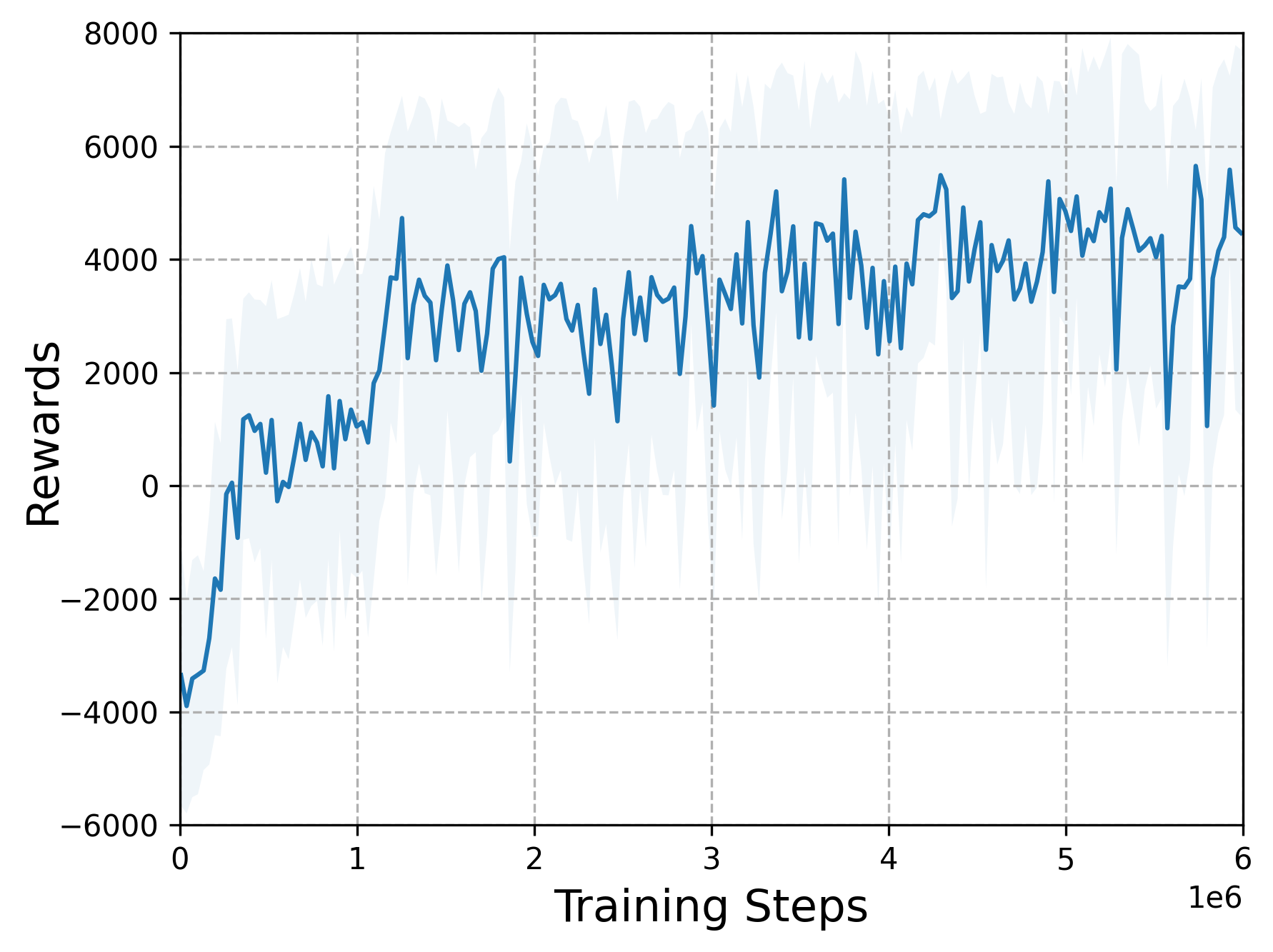
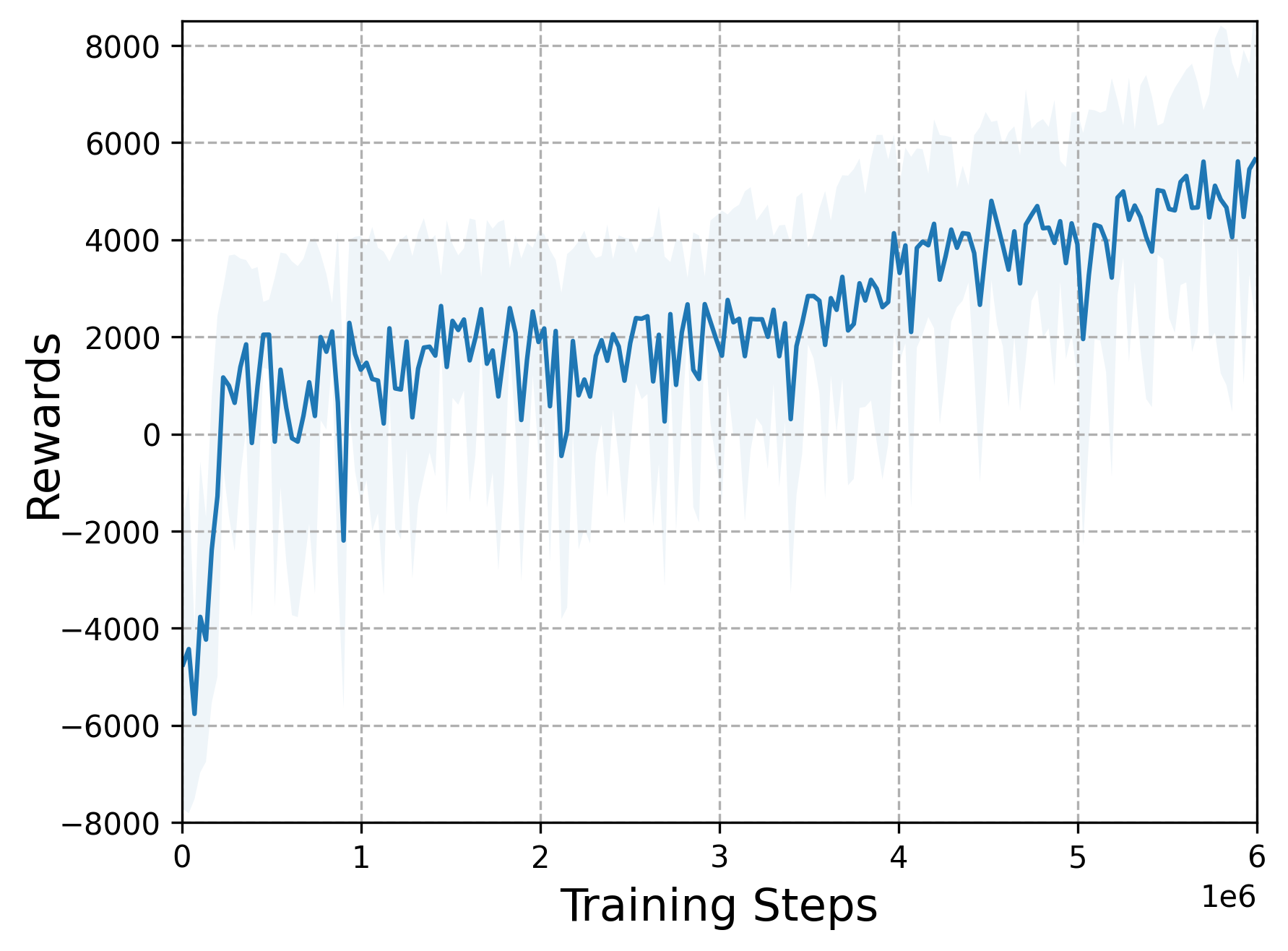
The following videos describe the encirclement interception process.