Swarm flocking control with collision avoidance via spatial-temporal GNN based deep reinforcement learning
Background
Flocking control, a fundamental behavior observed in nature, has garnered significant attention in the field of multi-agent systems. The ability of agents to move cohesively while avoiding collisions is crucial for various applications, including autonomous vehicles, robotics, and drone swarms. Traditional flocking algorithms often rely on predefined rules or potential fields, which may not adapt well to dynamic environments or complex interactions among agents.
Methods
-
A spatio-temporal graph neural network (ST-GNN) is designed to capture time-varying interactions among agents, enabling effective navigation in scenes that contain both static and dynamic obstacles.
-
A trajectory-prediction network is incorporated to aid decision-making, while a distributed topology-pruning algorithm is employed to reduce communication complexity and accelerate training efficiency.
-
A multi-agent reinforcement learning (MARL) framework is developed, integrating the ST-GNN and trajectory-prediction network to facilitate collaborative flocking control with collision avoidance.
Visualization
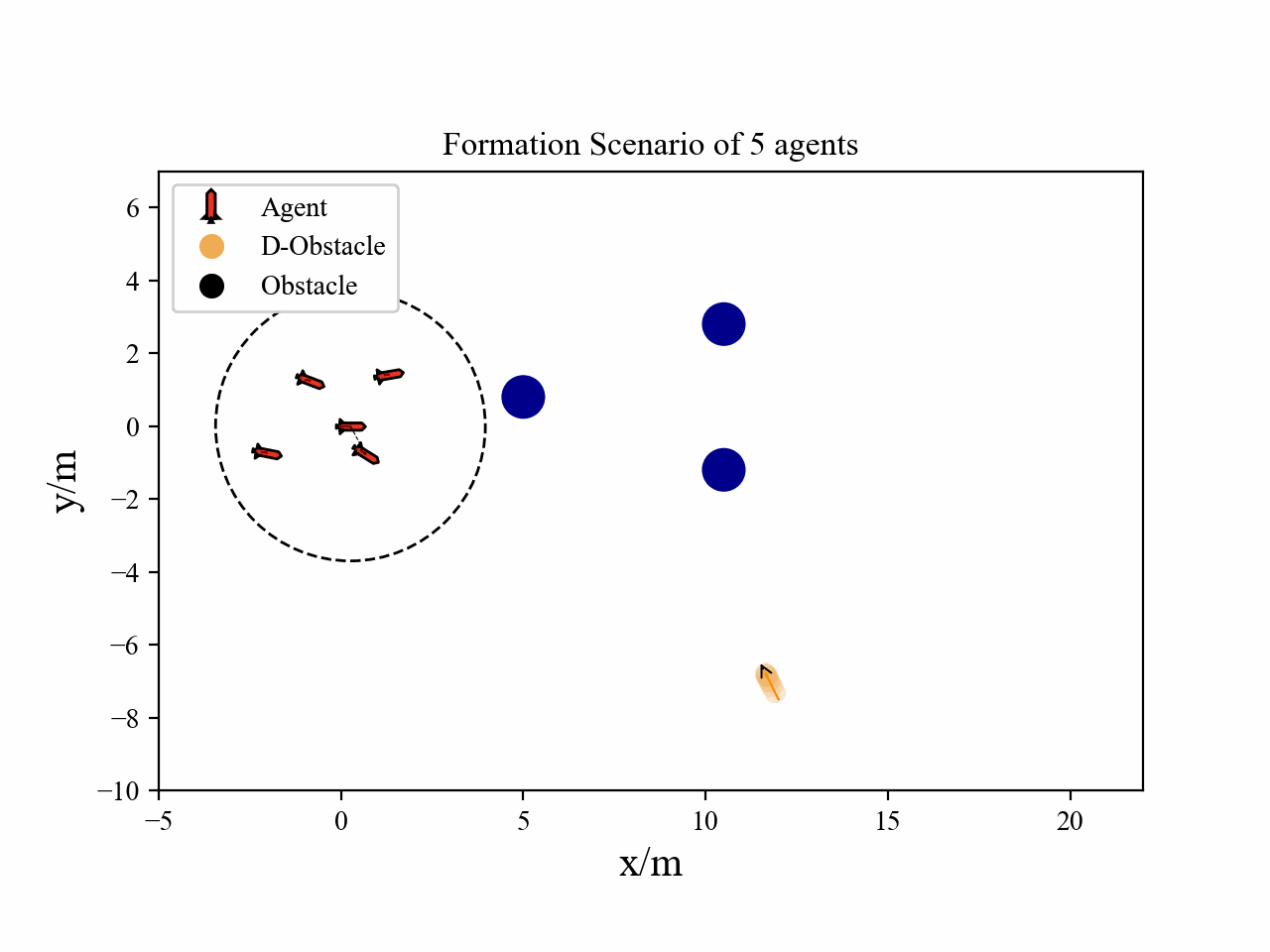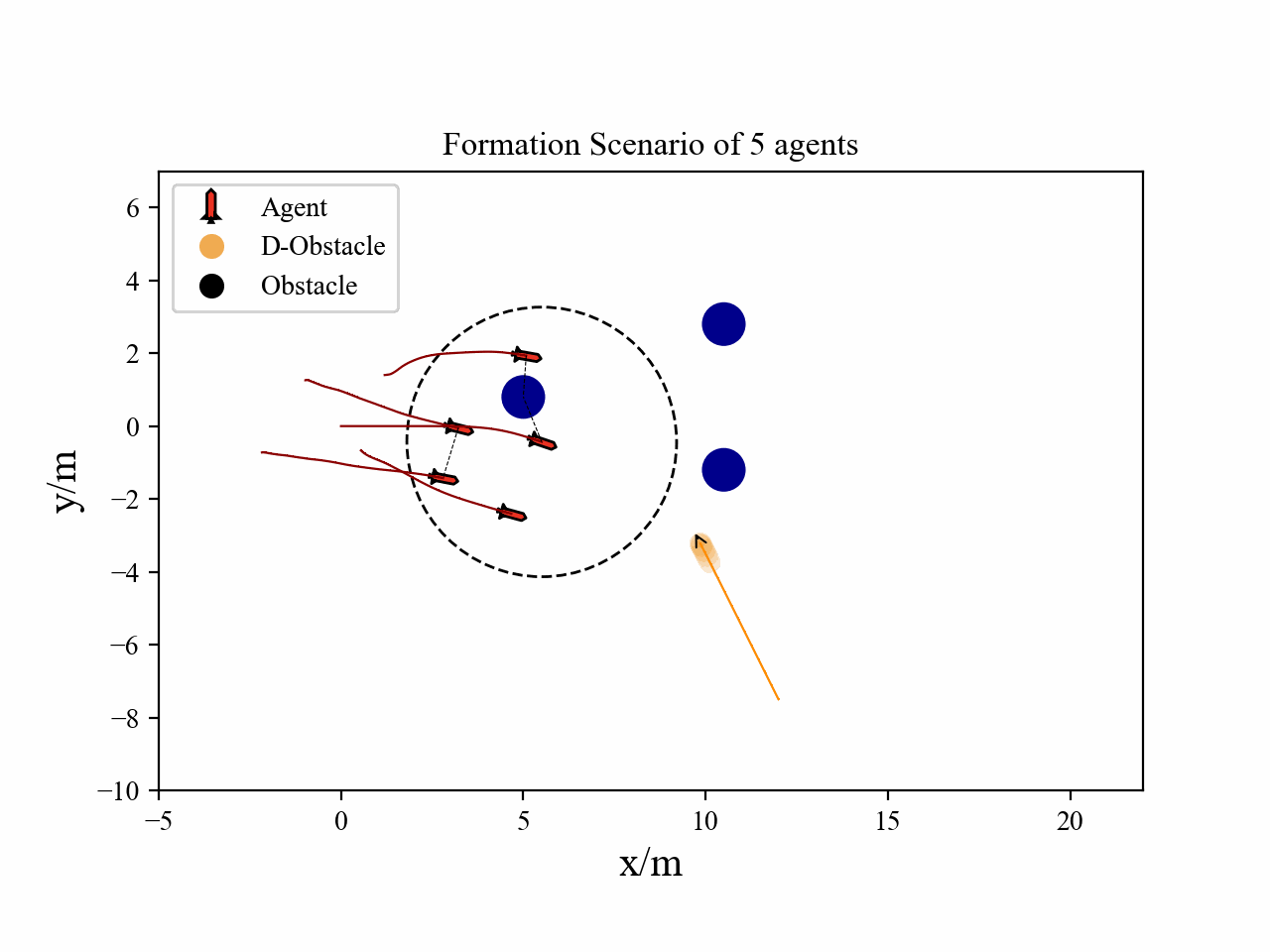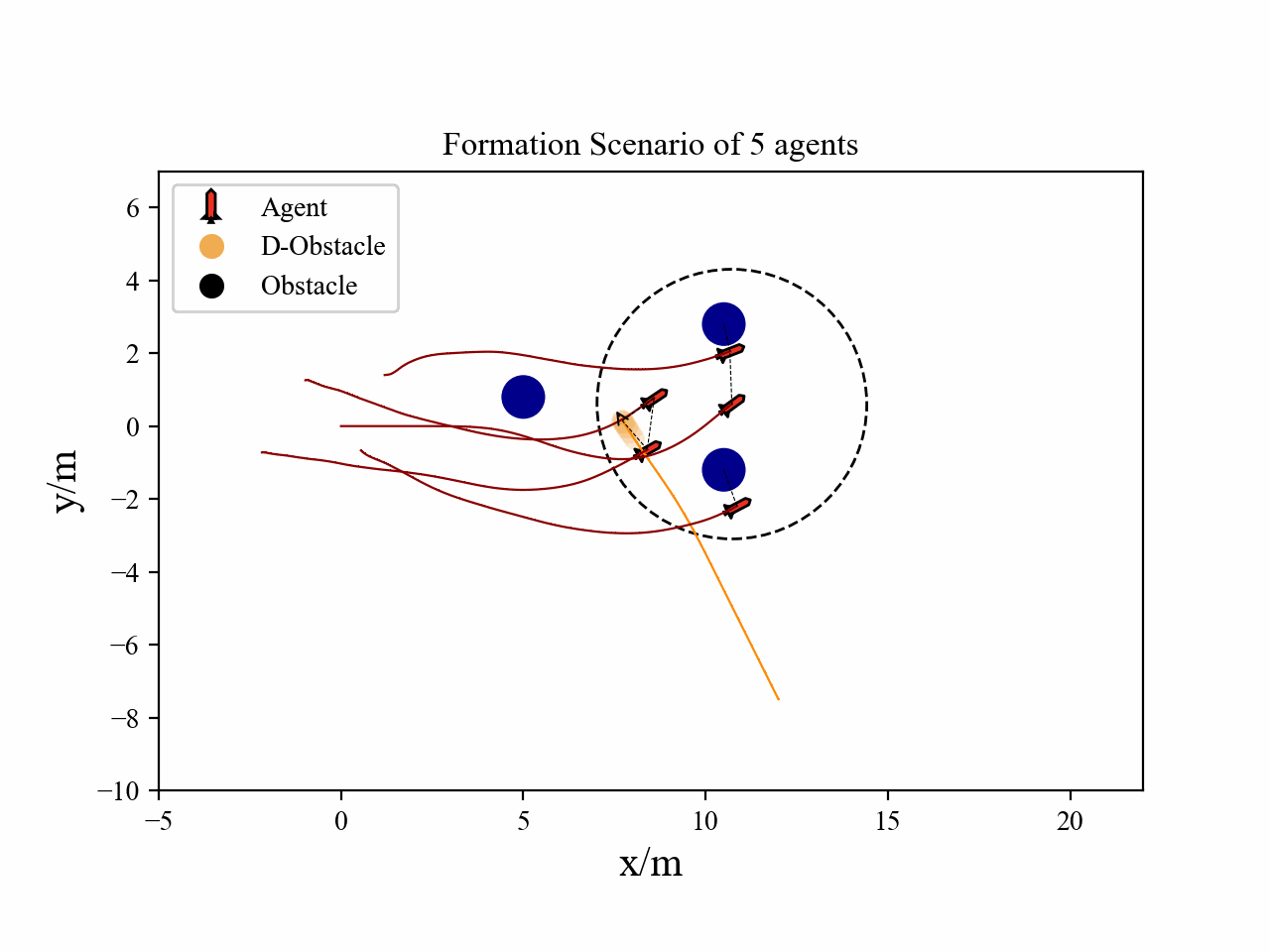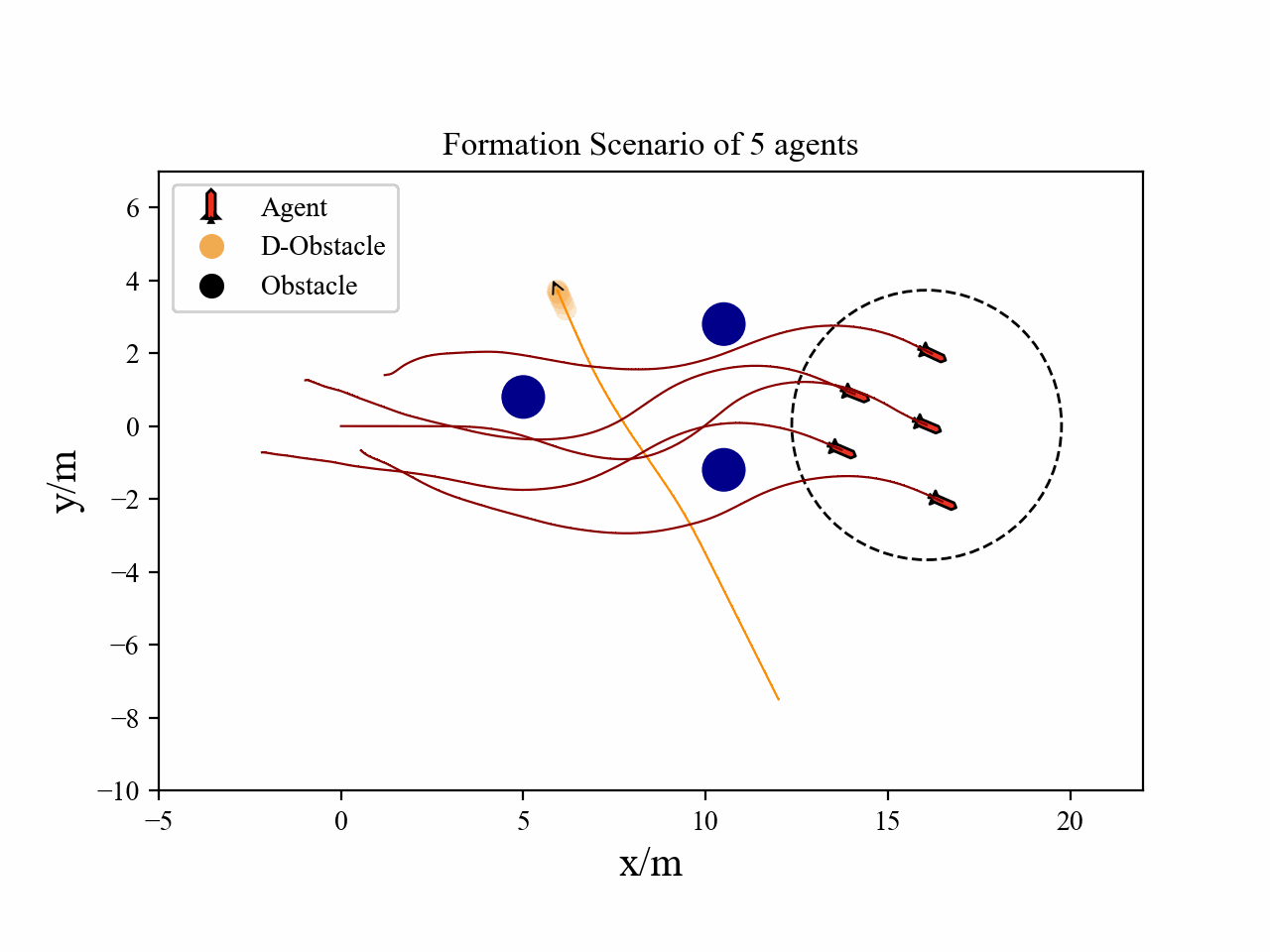
Due to the lack of computation resource, now we only conducted simulations with a small number of agents. More agents’ simulation results will be added later, the expected number is 15+ agents. We are working on sampling trajectories using GPU rather than CPU to speed up the process.
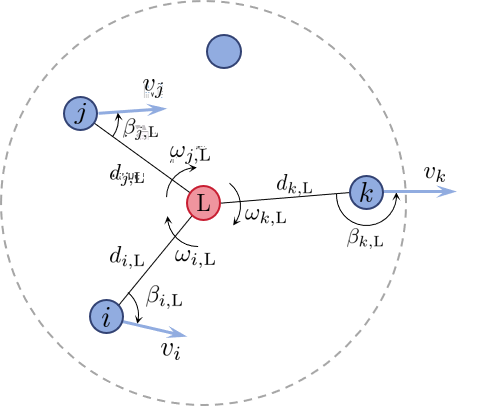
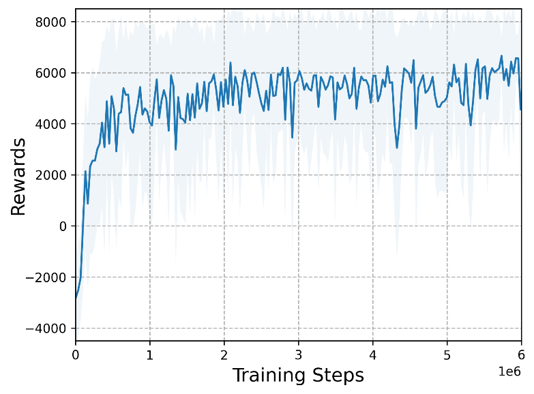
The following figure demonstrate the local observation representation and the training reward.
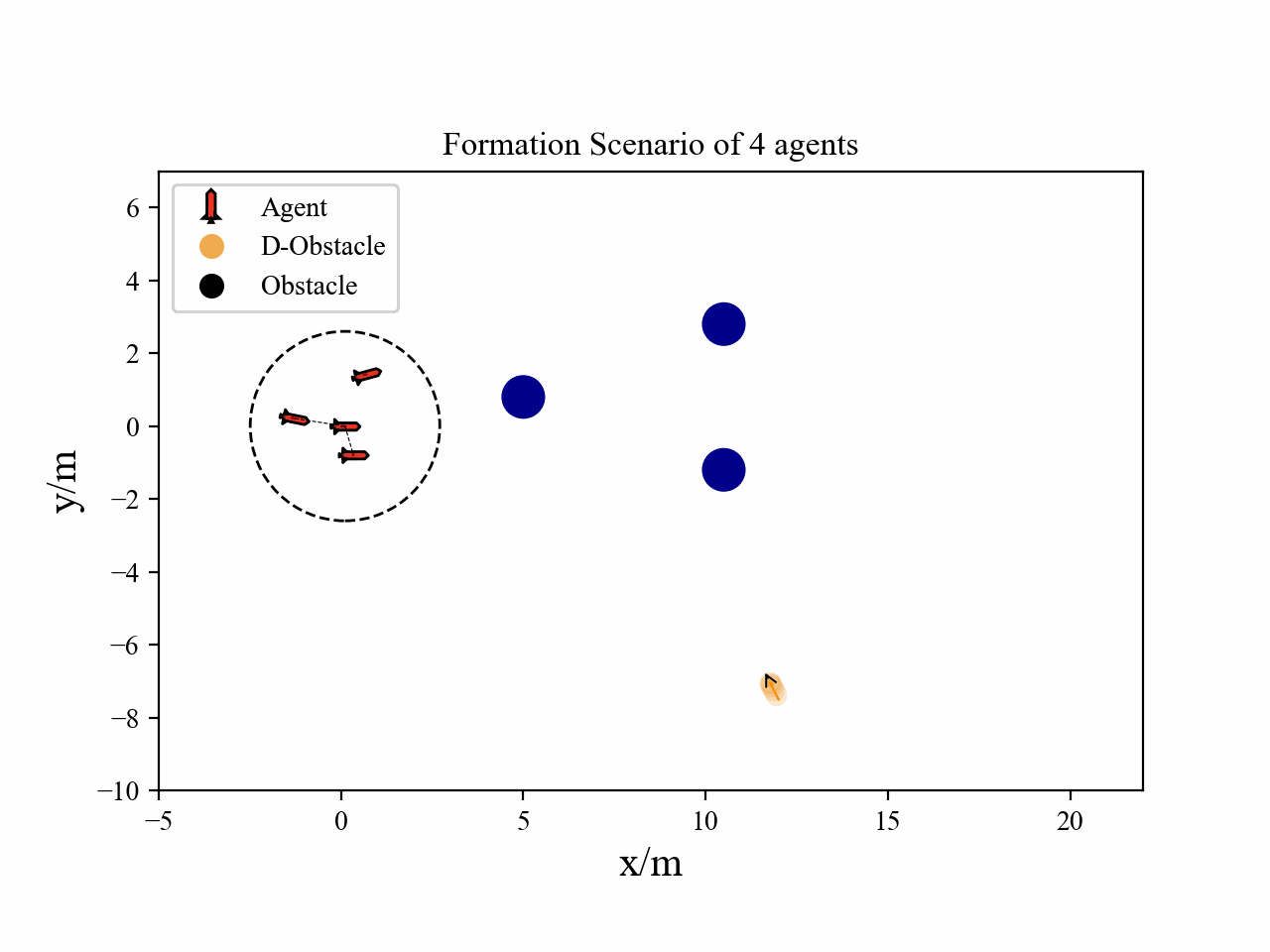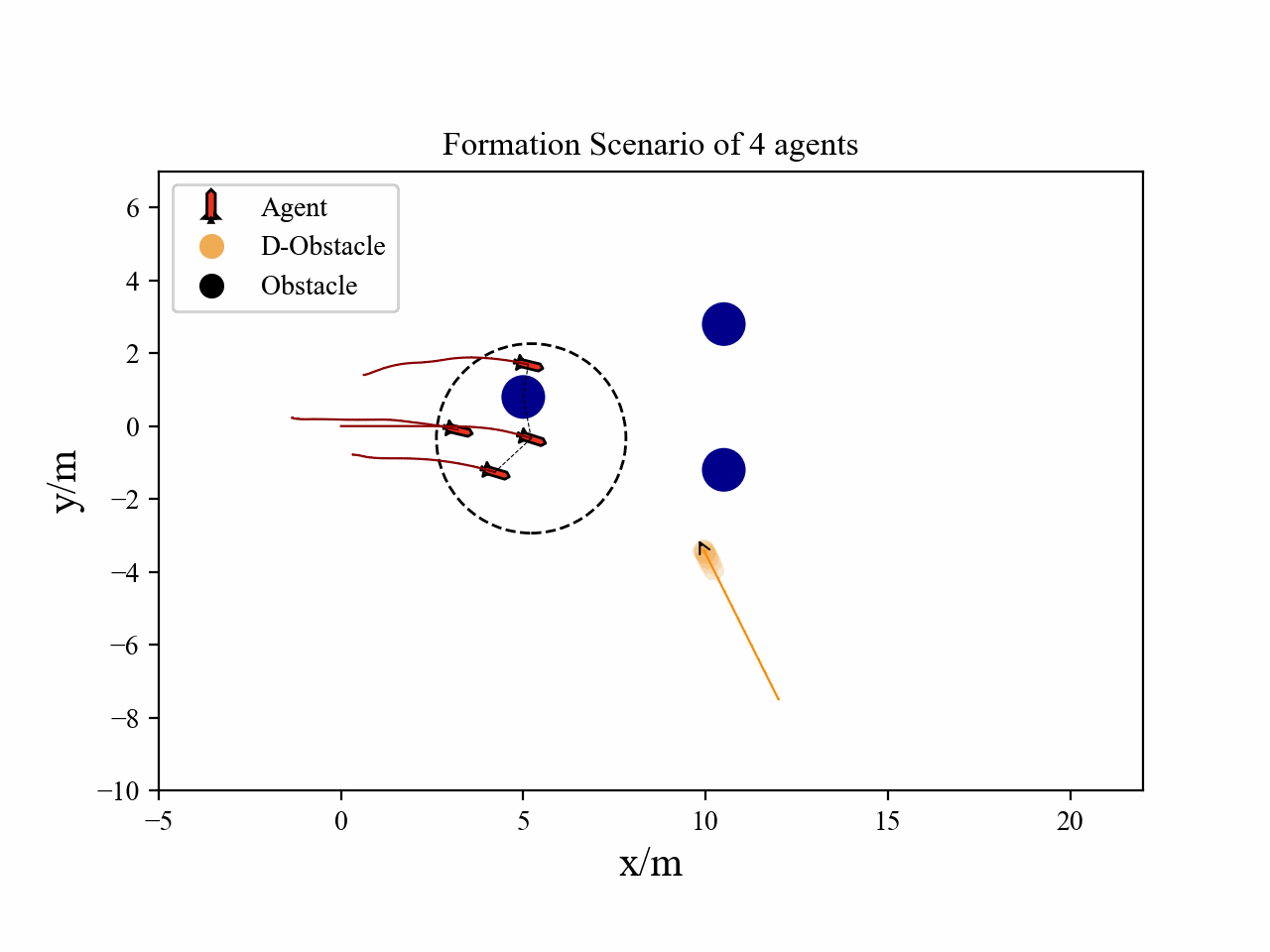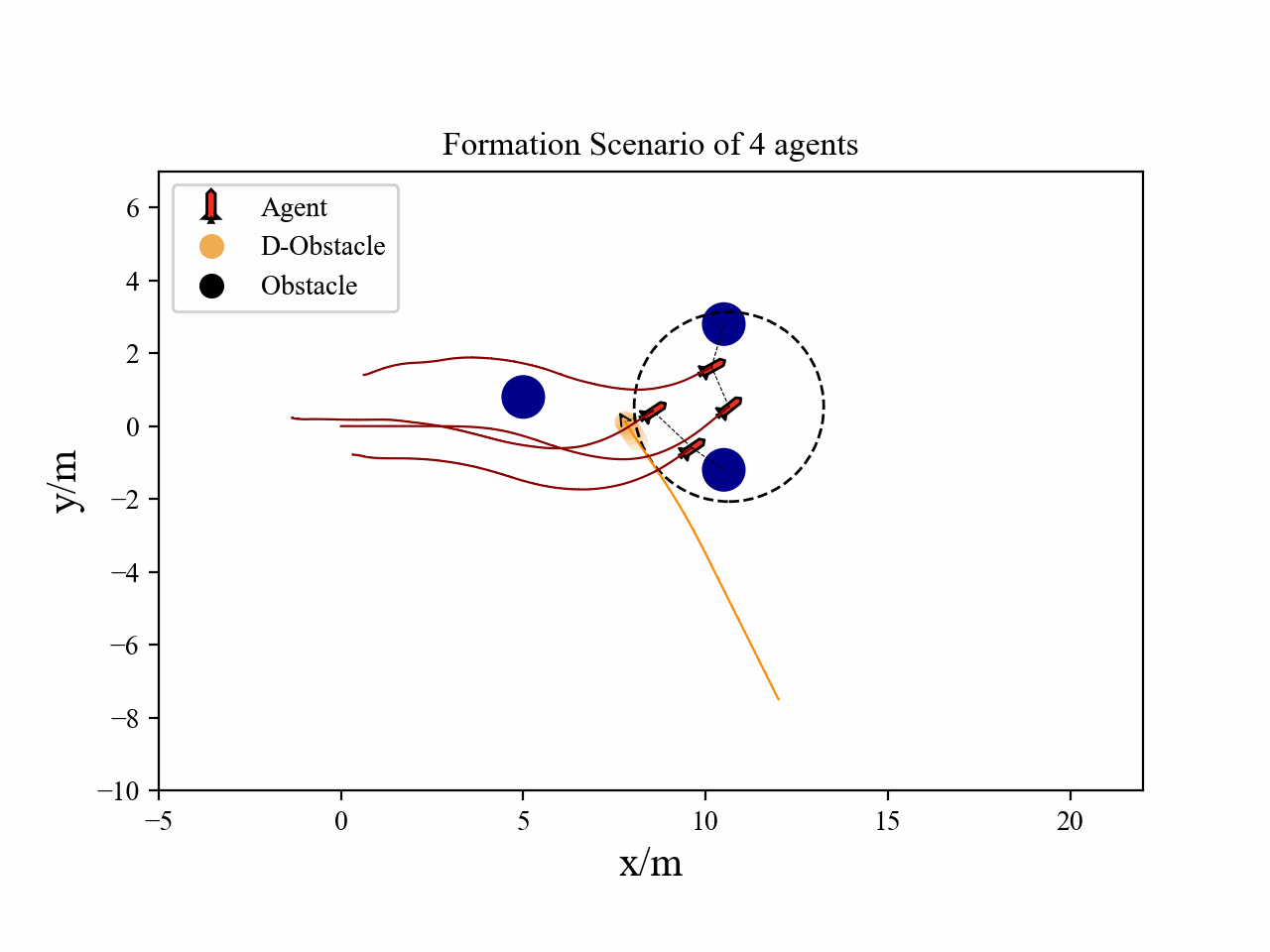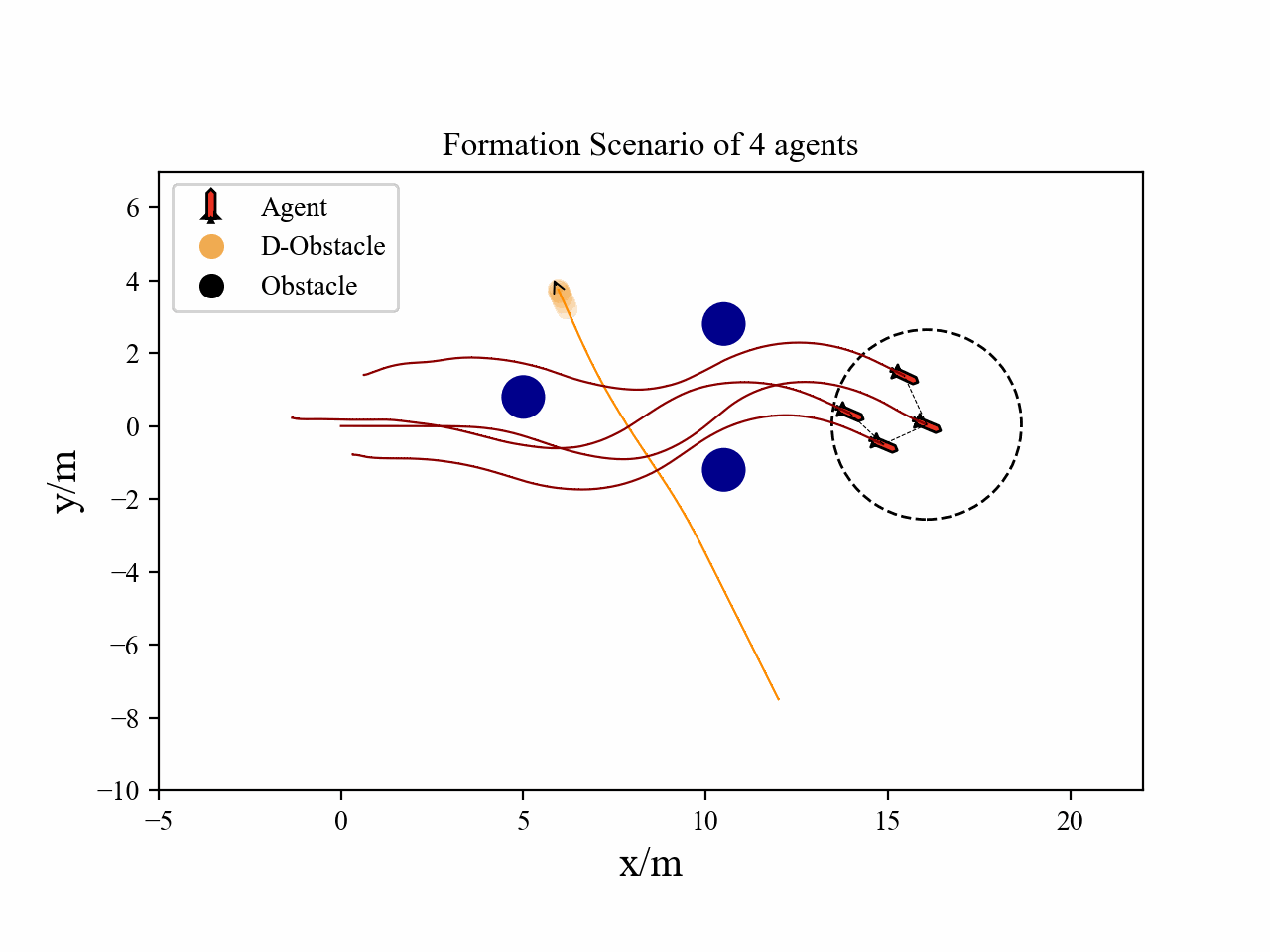
The following videos describe the flocking control process.